架构
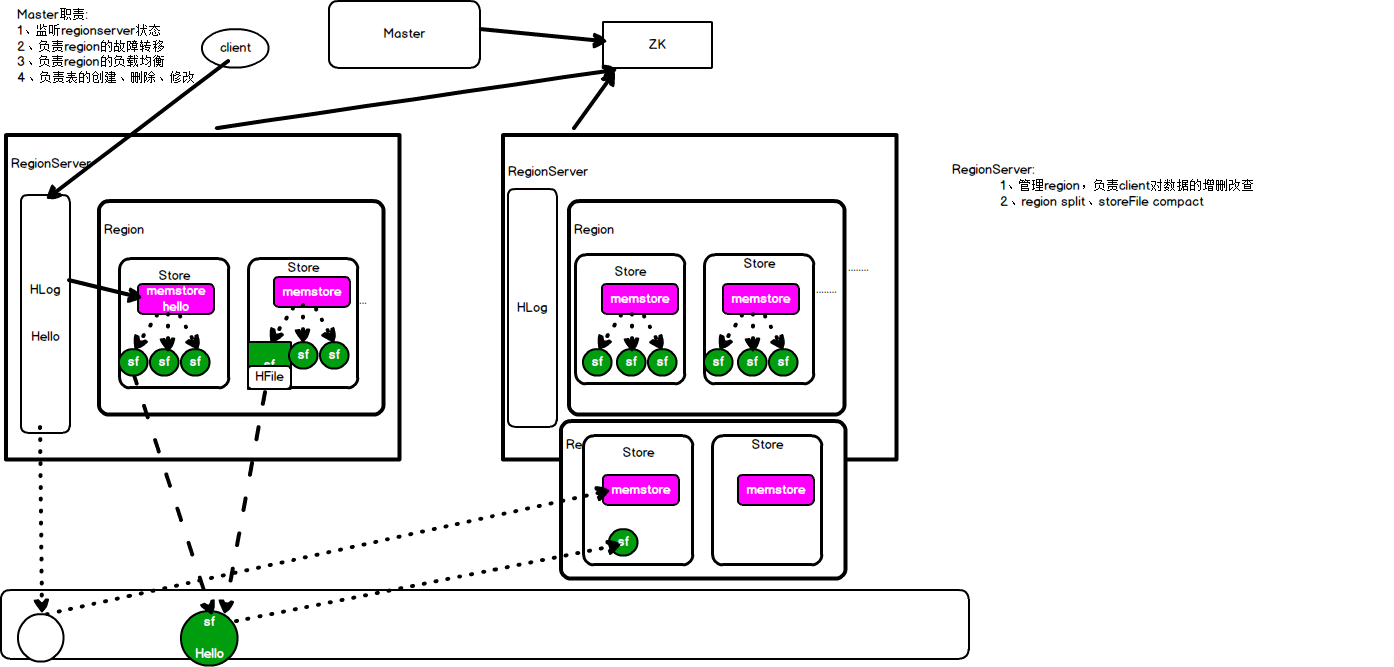
| master | 职责: 1. 监听regionserver状态 1. 负责region的故障转移:将出现故障的region转移出去,重新创建一个一样的region 1. 负责region的负载均衡:每个region的数据量差异不要过大,防止某个region负载过大 1. 负责表的创建、删除、修改(DDL) |
|
|---|---|---|
| regionserver | 部署在一台物理服务器上,region在这台物力服务器上 ( 访问hbase的时候,先去hbase 系统表查找定位这条记录属于哪个region,然后定位到这个region属于哪个服务器,然后就到哪个服务器里面查找对应region中的数据) 职责: 1. 管理region,负责client对数据的增删改查, 1. region split、storeFile compace |
HLog、 region |
| region | 表的分段,相当于hdfs的datanode,将数据分在多个区,可以同个split设置 设置后,根据rowkey的字典排序进行表的分段 |
stroe |
| store | 相当于列簇f,存放storefile表,如bash_info在一个store内,extra_info在另一个stroe内,两个store在一个region中 | memstore |
| memstore | store的内存区域,client会将数据写入memstore中等到memstore达到一定条件后会flush落盘,数数据在落盘前进行排序 | |
| storefile | memstore中的数据每flush一次生成一个storefile文件,文件以HFile格式保存在hdfs中,由hdfs副本保存机制进行备份保存 (kafka则是自己保存在磁盘,不借助hdfs) |
Hflie |
| HLog 预写日志 |
作用: 1. 防止memstore宕机造成数据丢失 1. 起消息队列的作用,可以异步写数据,不必等到写完一条数据再告诉master可以写下一条数据 机制: client将数据写在HLog后再写入memstore,并为防止Hlog宕机而保存到hdfs(异步) 当memstore的数据flush入hdfs后,自动删除Hlog在hdfs中的数据,加快后期数据恢复速度以及不造成数据冗余 宕机的情况: 一部分数据从hdfs中读取hlog进行恢复数据(flush前的数据),恢复到memstore,另一部分从hdfs中的storefile中关联即可(flush后的数据)(new:落盘的数据不是已经保存好了吗,为什么要恢复,应该错了吧) |
Hbase存储目录:
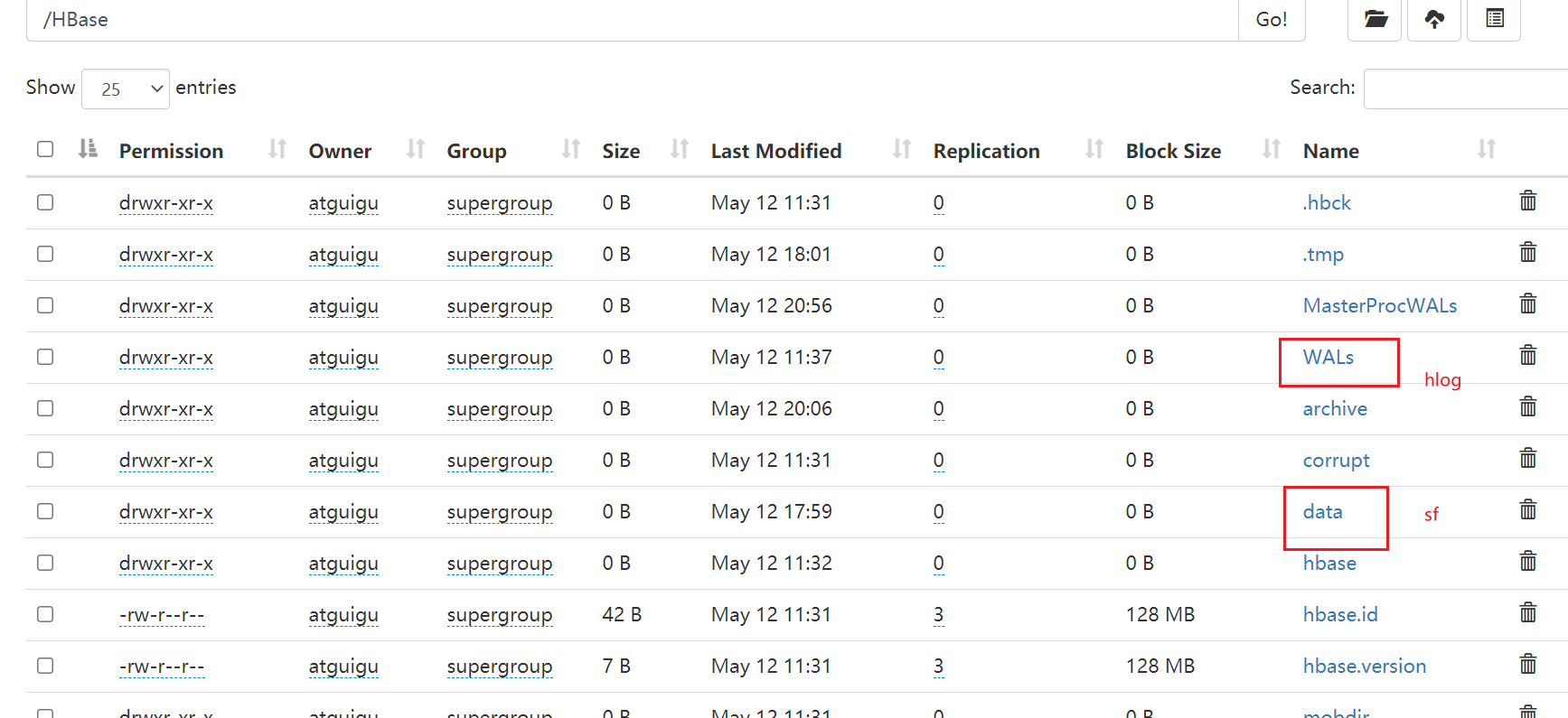
HLog:
存放在与data存放位置相同的一台机器上
data:
hbase网页: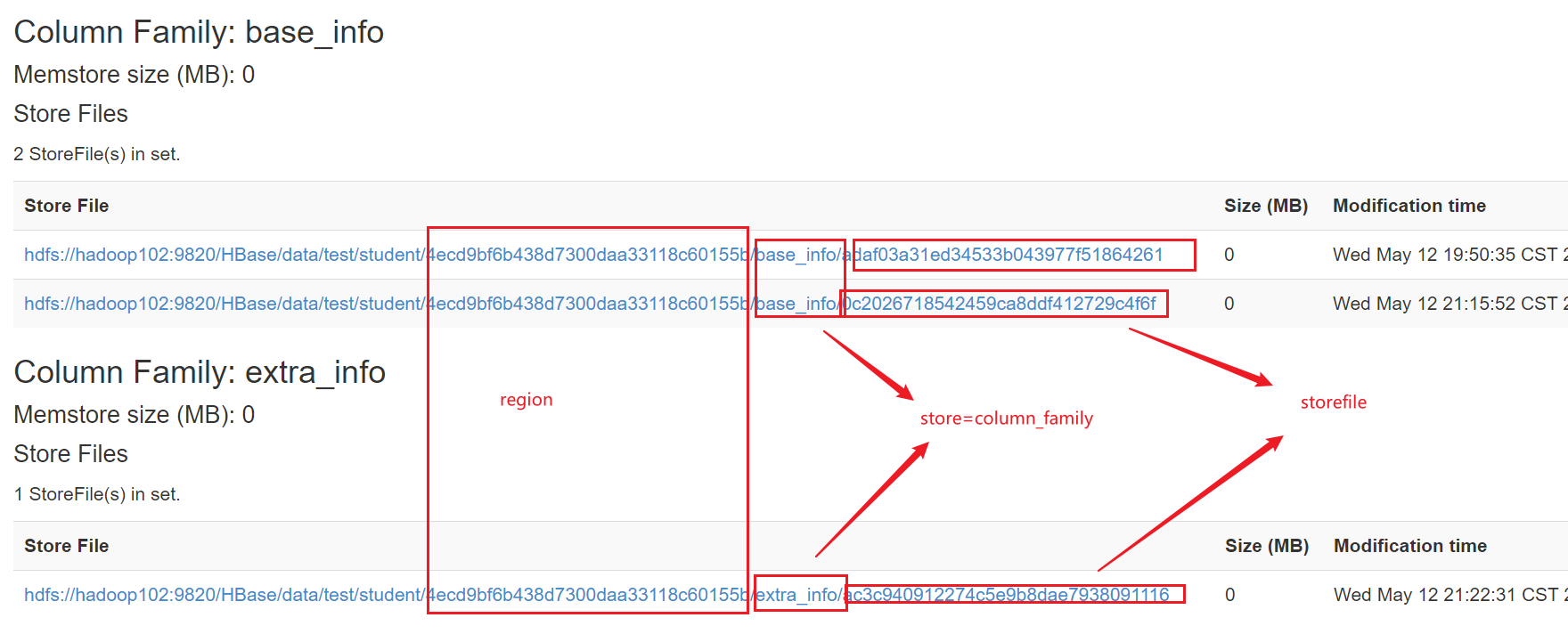
对比: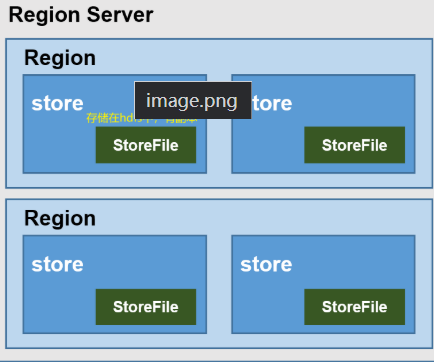
在hdfs上: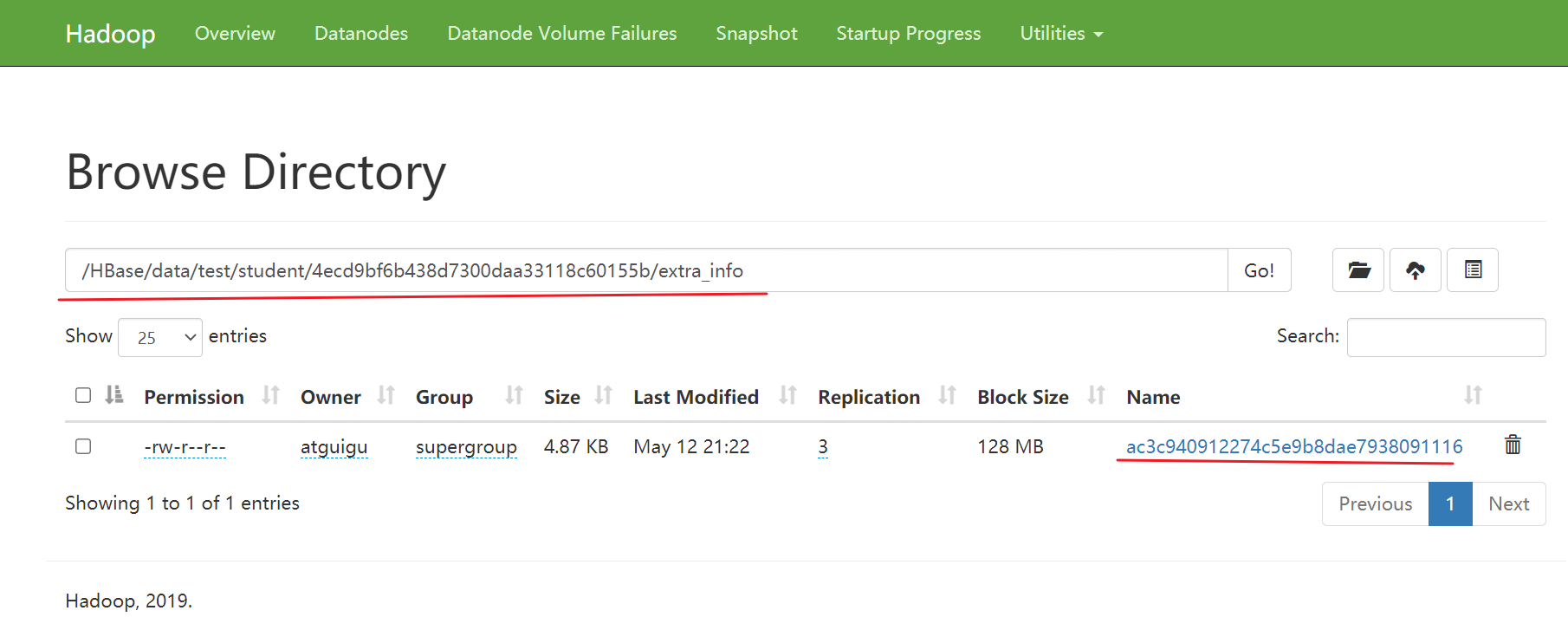
元数据表
原始数据表始终只有一个region
先切割出region:
create 'test:region_test','base_info','extra_info',{SPLITS=>['10','20']}
查看元数据:
scan 'hbase:meta'
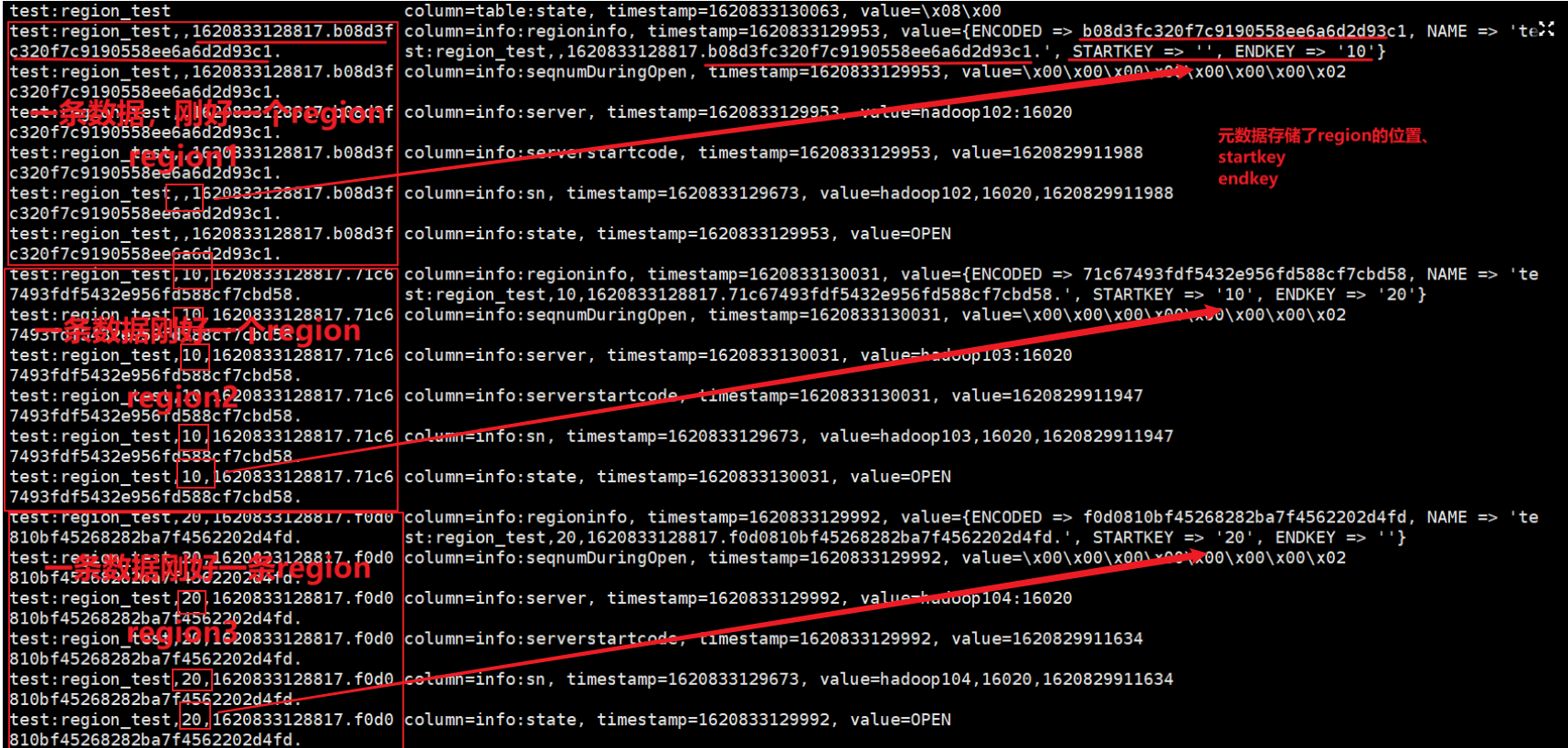
插入数据后就根据rowkey(如put ‘ns1:t1’,’r1’,’f1:q1’,’v1’)找到对应region,再找到对应的机器(102、103、104),最后进行读或写
put 'ns1:t1','r1','f1:q1','v1'
元数据region存储位置:
zookeeper
client先访问zookeeper,获取hbase:meta表位于哪个regionserver
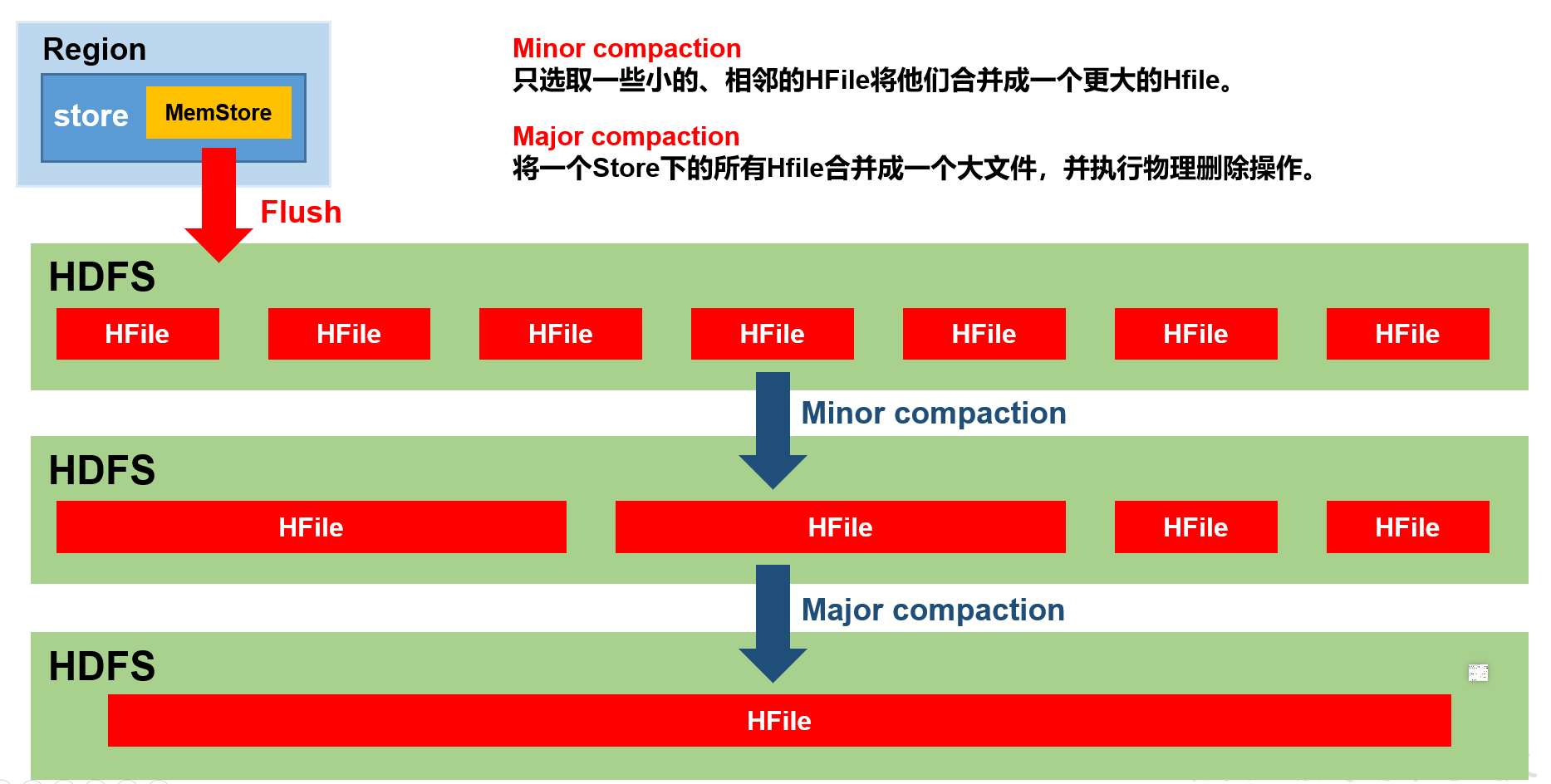
StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete,标记Delete并不会在磁盘中删除,只有major compaction的时候才会删除)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,加快查询时间,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种,分别是Minor Compaction和Major Compaction。
| (1)Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。 结果:一个store可能有多个较大文件 |
|
|---|---|
| (2)Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉过期和删除的数据。 结果:一个store只有一个大文件 |
合并后,通过指令删除数据就会真正地删除了 |
触发条件
hbase.hstore.compaction.min默认3个小文件合并 具体判定看小文件判定 |
Description The minimum number of StoreFiles which must be eligible for compaction before compaction can run. The goal of tuning hbase.hstore.compaction.min is to avoid ending up with too many tiny StoreFiles to compact. Setting this value to 2 would cause a minor compaction each time you have two StoreFiles in a Store, and this is probably not appropriate. If you set this value too high, all the other values will need to be adjusted accordingly. For most cases, the default value is appropriate. In previous versions of HBase, the parameter hbase.hstore.compaction.min was named hbase.hstore.compactionThreshold. Default 3 |
|---|---|
hbase.hregion.majorcompaction默认7天合并 |
Description Time between major compactions, expressed in milliseconds. Set to 0 to disable time-based automatic major compactions. User-requested and size-based major compactions will still run. This value is multiplied by hbase.hregion.majorcompaction.jitter to cause compaction to start at a somewhat-random time during a given window of time. The default value is 7 days, expressed in milliseconds. If major compactions are causing disruption in your environment, you can configure them to run at off-peak times for your deployment, or disable time-based major compactions by setting this parameter to 0, and run major compactions in a cron job or by another external mechanism. Default 604800000 |
Region Split
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
Region Split触发机制:
| R=tableRegionsCount:当前region所属表在当前regionserver上的region个数 max.filesize=hbase.hregion.max.filesize=10G flush.size=hbase.hregion.memstore.flush.size=128M |
R: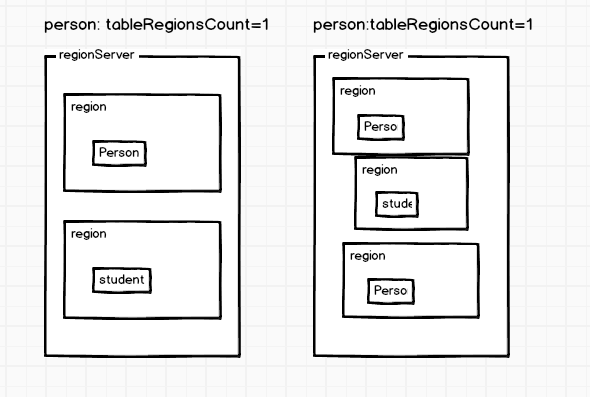 |
|---|---|
| 1)0.94版本之前:使用的是ConstantSizeRegionSplitPolicy策略。 | 当1个region中的某个Store下所有StoreFile的总大小超过max.filesize,该Region就会进行拆分。 公式:storeSize>10G |
| 2)0.94版本-2.0版本:使用的是IncreasingToUpperBoundRegionSplitPolicy。 | 当1个Region中的某个Store下所有StoreFile的总大小超过Min(2R^3 “flush.size”,”max.filesize”),该Region就会进行拆分 公式:R==0||R>100 ? 10G:Math.min(10g,2128R^3) |
| 3)2.0版本:使用的是SteppingSplitPolicy,继承了2),重写了判定方法 | 当R=1,分裂阈值等于flushSize2,否则为max.filesize 公式:storeSize>(R==1 ? 2128M : 10G) |
HBase原理–所有Region切分的细节都在这里了
详情:https://blog.csdn.net/wangyiyungw/article/details/82623426

若有收获,就点个赞吧
0 人点赞
