导入需要的依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency>
使用总结
Table API总结
Table resultTable = table.where($("vc").isGreaterOrEqual(20)).groupBy($("id")).aggregate($("vc").sum().as("vc_sum")).select($("id"), $("vc_sum"));
SQL 总结
tEnv.executeSql("create table sensor(" +"id string," +"ts bigint," +"vc int, " +"t as to_timestamp(from_unixtime(ts/1000,'yyyy-MM-dd HH:mm:ss'))," +"watermark for t as t - interval '5' second)" +"with("+ "'connector' = 'filesystem',"+ "'path' = 'input/sensor.txt',"+ "'format' = 'csv'"+ ")");
以下是流操作
TableAPI(动态表) 与 DateStream之间的转换
流到表的转换
public class Flink01_TableApi_BasicUse {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> waterSensorStream =env.fromElements(new WaterSensor("sensor_1", 1000L, 10),new WaterSensor("sensor_1", 2000L, 20),new WaterSensor("sensor_2", 3000L, 30),new WaterSensor("sensor_1", 4000L, 40),new WaterSensor("sensor_1", 5000L, 50),new WaterSensor("sensor_2", 6000L, 60));// 1. 创建表的执行环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 2. 创建表: 将流转换成动态表. 表的字段名从pojo的属性名自动抽取Table table = tableEnv.fromDataStream(waterSensorStream);// 3. 对动态表进行查询Table resultTable = table.where($("id").isEqual("sensor_1")).select($("id"), $("ts"), $("vc"));// 4. 把动态表转换成流// 有了Row.class就可以起别名了DataStream<Row> resultStream = tableEnv.toAppendStream(resultTable, Row.class);resultStream.print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}}
聚合操作
// 3. 对动态表进行查询Table resultTable = table.where($("vc").isGreaterOrEqual(20)).groupBy($("id")).aggregate($("vc").sum().as("vc_sum")).select($("id"), $("vc_sum"));// 4. 把动态表转换成流 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);
表到流的转换
动态表可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。它可能是一个只有一行、不断更新的表,也可能是一个 insert-only 的表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
Append-only 追加流
调用:**tenv.toAppendStream**_**(**_**t1, Row.class**_**)**_**;**
使用条件:只有insert操作使用,加入你使用了分组,本来流中来了1条sensor_1,1 ,后面再来一条sensor_1,1,此时再分组sum聚合后,数据更新了,则不能使用这种模式
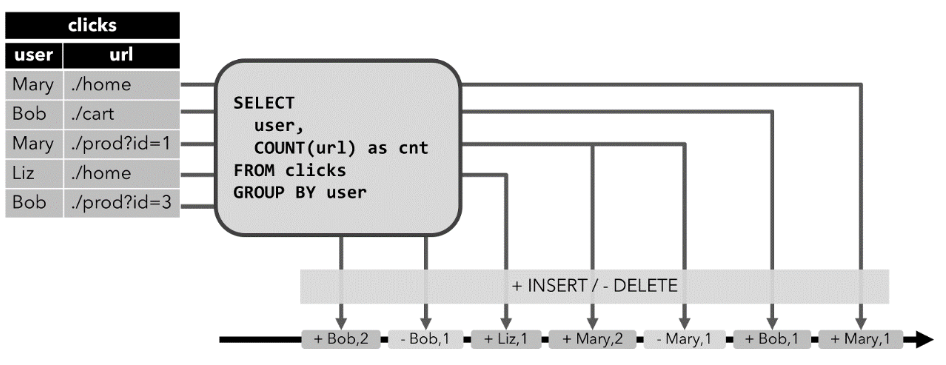
Retract 流,撤回流
调用:**tenv.toRetractStream**_**(**_**t1,Row.class**_**)**_
使用条件:包含insert、delete、update的操作,一般产生这些操作的算子是聚合操作算子
原理:
retract 流包含2种类型的 message:
add message+ retract message
将INSERT 操作编码为 add message、
将 DELETE 操作编码为 retract message、
将 UPDATE 操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,
效果:因为有了先把原先重复数据删除再添加的操作,会让数据不出现重复的效果
Upsert 流
调用:**在将动态表转换为 DataStream 时,只支持 append 流和 retract 流**
upsert 流包含两种类型的 message:
upsert messages 和delete messages。
转换为 upsert 流的动态表需要(可能是组合的)唯一键。
将 INSERT 和 UPDATE 操作编码为 upsert message,
将 DELETE 操作编码为 delete message ,
将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。
与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。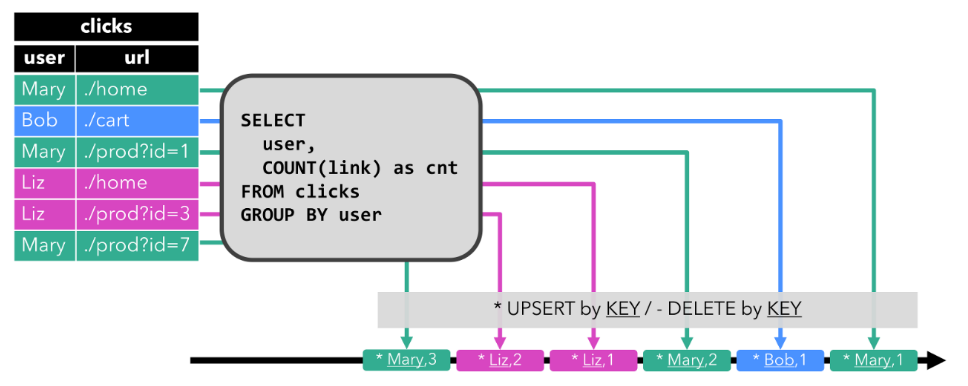
效果:
数据会重复,最后的数据才是全局的数据
以上属于流操作
TableAPI(动态表) 与 数据源(conncect)之间的转换
写入source
File source
// 2. 创建表// 2.1 表的元数据信息Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());// 2.2 连接文件, 并创建一个临时表, 其实就是一个动态表tableEnv.connect(new FileSystem().path("input/sensor.txt")).withFormat(new Csv().fieldDelimiter(',').lineDelimiter("\n")).withSchema(schema).createTemporaryTable("sensor");// 3. 做成表对象, 然后对动态表进行查询Table sensorTable = tableEnv.from("sensor");Table resultTable = sensorTable.groupBy($("id")).select($("id"), $("id").count().as("cnt"));// 4. 把动态表转换成流. 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);resultStream.print();
Kafka Source
// 2. 创建表// 2.1 表的元数据信息Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());// 2.2 连接文件, 并创建一个临时表, 其实就是一个动态表tableEnv.connect(new Kafka().version("universal").topic("sensor").startFromLatest()// 指定offset.property("group.id", "bigdata").property("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092")).withFormat(new Json()).withSchema(schema).createTemporaryTable("sensor");// 3. 对动态表进行查询Table sensorTable = tableEnv.from("sensor");Table resultTable = sensorTable.groupBy($("id")).select($("id"), $("id").count().as("cnt"));// 4. 把动态表转换成流. 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);resultStream.print();
写出sink:
File Sink
// 1. 创建表的执行环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);Table sensorTable = tableEnv.fromDataStream(waterSensorStream);Table resultTable = sensorTable.where($("id").isEqual("sensor_1") ).select($("id"), $("ts"), $("vc"));// 创建输出表Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());tableEnv.connect(new FileSystem().path("output/sensor_id.txt")).withFormat(new Csv().fieldDelimiter('|')).withSchema(schema).createTemporaryTable("sensor");// 把数据写入到输出表中resultTable.executeInsert("sensor");
Kafka Sink
// 1. 创建表的执行环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);Table sensorTable = tableEnv.fromDataStream(waterSensorStream);Table resultTable = sensorTable.where($("id").isEqual("sensor_1") ).select($("id"), $("ts"), $("vc"));// 创建输出表Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());tableEnv.connect(new Kafka().version("universal").topic("sink_sensor").sinkPartitionerRoundRobin().property("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092")).withFormat(new Json()).withSchema(schema).createTemporaryTable("sensor");// 把数据写入到输出表中resultTable.executeInsert("sensor");
其他connector用法
参考官方文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/connect.html

若有收获,就点个赞吧
0 人点赞
