Spark有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
spark-yarn运行流程
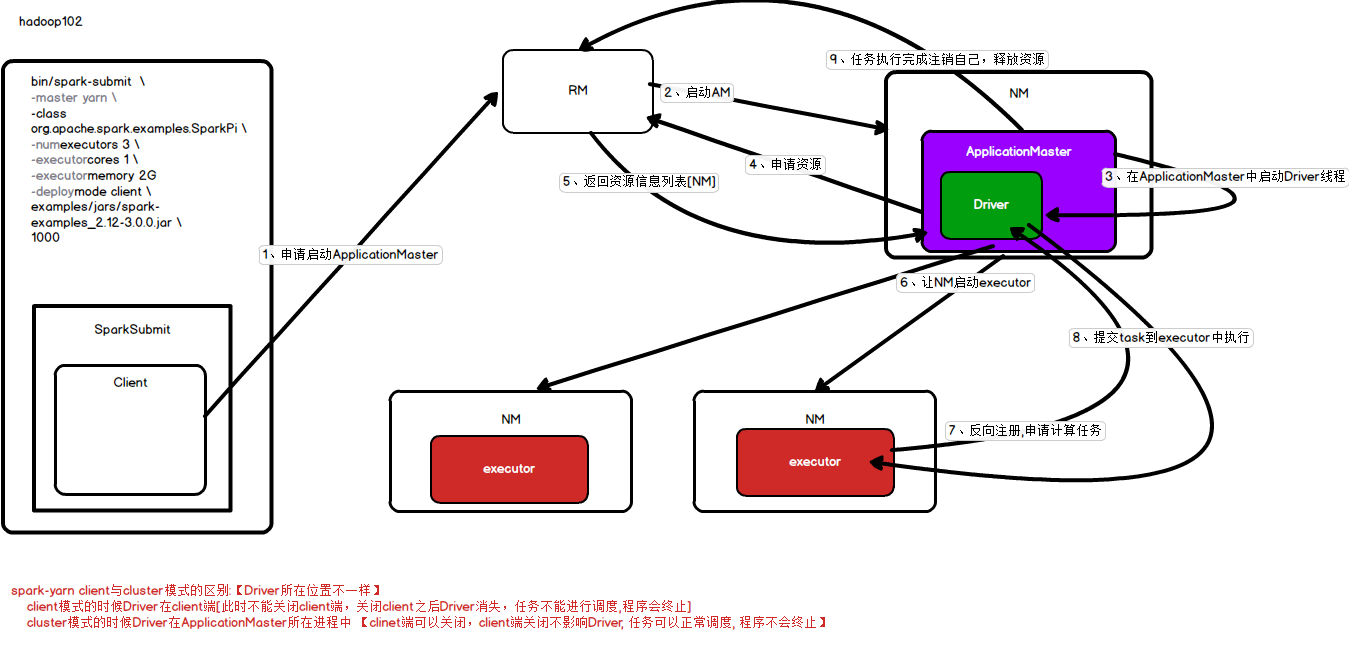
客户端模式
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出。
流程:
1、提交客户端任务执行指令
2、生成一个spark submit 进程,在进程内启动客户端并生成一个Driver线程
3、之后客户端向RM注册任务,申请启动appmaster
4、RM找到一台NM在其中启动appmaster
5、appmaster再想RM申请资源
6、RM将资源列表返回给appmaster去找到NM,appmaster根据资源列表找到NM并启动executor
7、excutor启动完毕后向Driver进行反注册,申请计算任务,
8、driver将task交给executor执行
9、等到executor执行完毕后,appmaster向RM注销自己,释放资源
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode client \./examples/jars/spark-examples_2.12-3.0.0.jar \10 --jar包的参数
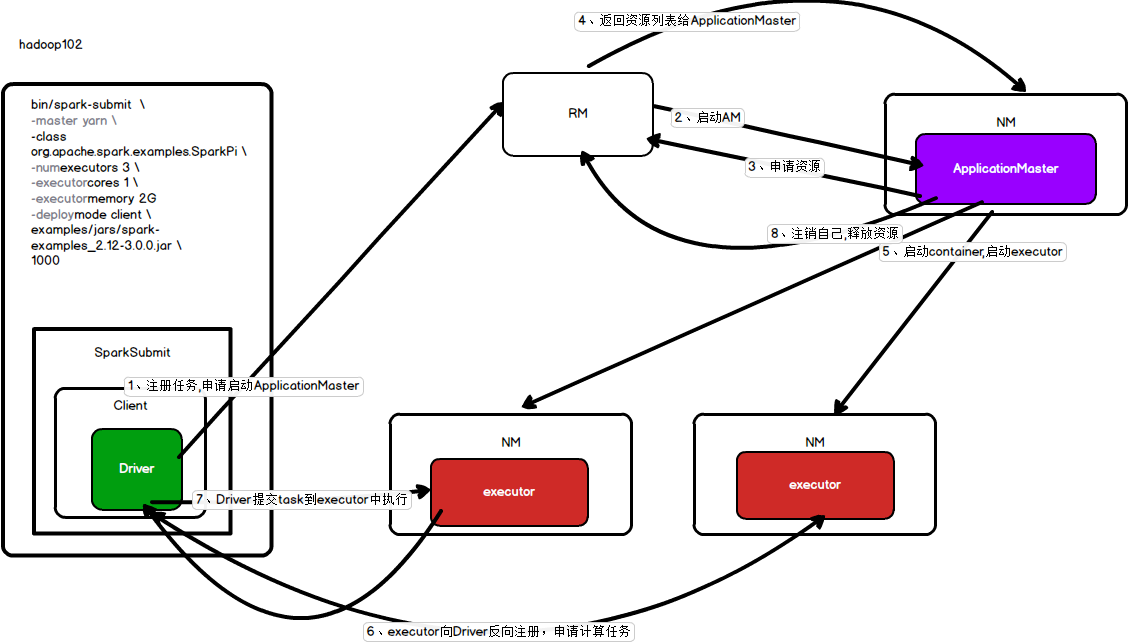
集群模式
yarn-cluster:Driver程序运行在由ResourceManager启动的APPMaster适用于生产环境。
流程:
1、提交集群模式计算指令
2、指令提交后会生成一个spark submit的进程,进程中启动客户端
3、客户端向RM注册并申请启动APPmaster
4、RM接收到申请后找到一台NM并在其中启动appmaster
5、appmaster向RM申请资源
6、RM返回符合要求的NM资源列表,appmaster根据资源列表找到NM并在其中启动executor
7、executor启动完成后向Driver反向注册,并申请计算任务
8、Driver向excutor发送task
9、等到executor执行完成后,appmaster向RM注销自己,释放资源
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \./examples/jars/spark-examples_2.12-3.0.0.jar \10
查看运行结果
(1)查看http://hadoop103:8088/cluster页面,点击History按钮,跳转到历史详情页面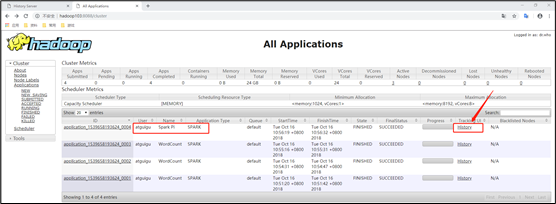
(2)http://hadoop102:18080点击Executors->点击driver中的stdout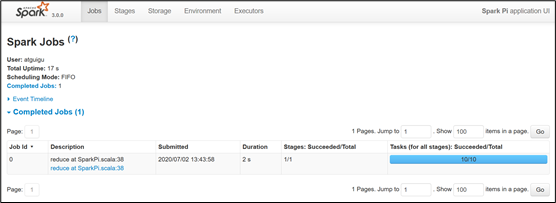
注意:如果在yarn日志端无法查看到具体的日志,则在yarn-site.xml中添加如下配置并启动Yarn历史服务器
<property><name>yarn.log.server.url</name><value>http://hadoop102:19888/jobhistory/logs</value></property>
注意:hadoop历史服务器也要启动 mr-jobhistory-daemon.sh start historyserver
spark-submit工作常用参数:
| —master 指定任务提交给哪个资源调度执行 local模式: local/local[N]/local[] local: 使用单线程模拟执行 local[N]: 使用N个线程模拟执行 local[]: 使用cpu核数个线程模拟执行 standalon模式: spark://master ip:7077,master ip:7077 yarn模式: yarn |
—master local[4] —master spark://master ip:7077,master ip:7077 —master yarn |
|---|---|
| —deploy-mode: 指定运行模式[client与cluster] client与cluster的区别: Driver所在位置不一样 standalon模式: client模式: Driver在client端 cluster模式: Driver在任意一个Worker上 yarn模式: client模式: Driver在client端 cluster模式: Driver在ApplicationMaster所在进程中 |
—deploy-mode client —deploy-mode cluster |
| —class: 指定待运行的带有main方法的主类 | —class org.apache.spark.examples.SparkPi |
| —executor-memory: 指定每个executor的内存大小 | |
| —driver-memory: 指定Driver占用内存大小[一般工作中设置5-10G] | [一般工作中设置5-10G],默认1G |
| —total-executor-cores: 指定任务所有executor的总核数 | [仅用于standalone模式] |
| —executor-cores: 指定每个executor的cpu核数 | |
| —num-executors: 指定executor的个数 | [仅用于yarn模式] |
| —queue: 指定资源队列的名称 | [仅用于yarn模式],不同大数据部门可能用的队列不一样 |
| 提交任务的总资源大小: standalone模式: 任务需要的总CPU核数 = —total-executor-cores 任务需要的总内存 =( total-executor-cores/executor-cores) executor-memory yarn模式: 任务需要的总CPU核数 = executor-cores num-executors 任务需要的总内存 = num-executors * executor-memory |

若有收获,就点个赞吧
0 人点赞
