什么是状态
状态分类
<br /> 任何算子都有状态,在参数中使用: <br />richxx类才有open方法,才能获得运行时类<br /> <br />
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime托管, 自动存储, 自动恢复, 自动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink提供多种常用数据结构, 例如:ListState, MapState等 | 字节数组: byte[] |
| 使用场景 | 绝大数Flink算子 | 所有算子 |
管理状态:flink替我们管理状态,交给运行时对象托管
总结:算子状态和键控状态:
算子状态每个算子都能用
键控状态只能用在keyby后的算子
Operator State算子状态
可使用在所有算子中
算子状态,只和并行度有关,所有不同的key都可以访问同一个状态
按并行度进行隔离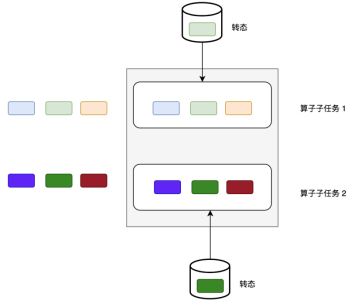
列表状态
list state (几乎不用)
并行度状态合并后,复制,平均分配给每个并行度,前提是并行度发生改变
联合列表状态
union list state (几乎不用)
并行度状态合并后,复制,全量分配给每个并行度,不需要并行度的改变
(source和sink有可能用到)如kafka-source
广播状态BroadcastProcessFunction
广播流本质:<br /> BroadcastState<String, String> bdState = ctx.getBroadcastState(bdStateDesc);<br /> map集合<br /> 作用:<br /> 每个并行度共享相同的广播状态<br /> 在不同并行度中,都能按需求获得相同的值,就算分区相隔也能使用相同的状态值<br />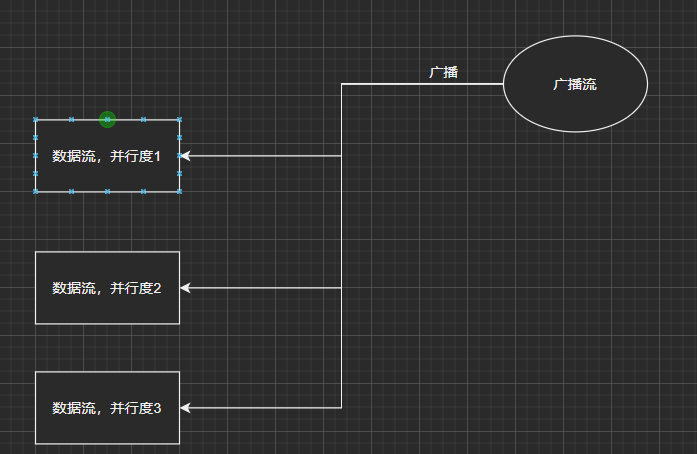<br /> 组成:<br /> 控制流:获取控制信号的流<br /> 将:信号--转换(broadcast)--为广播流<br /> 数据流:获取需要计算的数据的流<br /> 用:数据流--关联(connect)--广播流<br /> 再调用process方法,对广播处理函数进行方法重写。<br /> processElement 数据流(普通porcess都有的方法 )<br /> processBroadcastElement 广播流<br />与spark的广播状态区别:<br />spark的广播是为了节省内存<br />flink 的广播是为了动态调节数据,使得每个并行度中的数据都能使用到广播状态
Keyed State键控状态
只能用在keyby后面的流上,
状态和并行度无关,**只和key有关系**,有多少个不同的key就有多少个状态
按不同的key进行隔离
也有广播状态KeyedBroadcastProcessFunction
process算子new KeyedProcessFunction
map等算子 new RichXxxFuntion
不信?-> |
|---|
每种key只会去到不同的并行度当中,所以不存在隔并行度的key<br />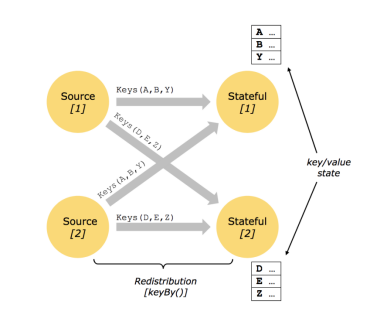
种类
valuestate
liststate
ReducingState
在状态中定义聚合规则。
不可改变类型,传入一个值聚合,比如只算sum
AggregatingState
在状态中定义聚合规则。
可改变类型,传入多个值聚合,比如算sum和count,求avg
MapState
去重,如果只去重,key定义类型即可(比如水位去重,则key类型为integer),value可以不管,类型改不改都无所谓
以上5中都不是,那么用getState方法,这个是通用的``
通用流程
open方法获取状态xxState,因为是父类的方法,需要`ctrl+o` 来实现<br />flink将状态托管给:运行时,所以先获取运行时<br />从运行时获取状态<br /> processElement调用状态,<br /> 将当前值添加到状态(落盘,累计)<br /> Out.collect.get()/.key()整个状态写出
状态清理
窗口+状态+process方法
**以上3个条件缺一不可,如果没窗口,也不需要清理**
1、对于process算子:
不同窗口会共享一个状态,使用的时候,如果要单独统计,那么务必记得对上一个窗口的状态就行清空:
xxxState.clear().
2、对于其他算子:
算子内部代码已经帮我们进行清空,所以无序再清空。
原始状态
二次开发用
状态后端
状态后端主要负责两件事:
本地(taskmanager)的状态管理:
远程存储(checkpoin)状态写入远程存储:
在配置文件中配置了就可以不再代码中指定远程的(少用,不灵活,一般在代码改)
如果在代码中不指定则默认使用memory村存储,
memory:(适用于测试)
本地存储用的是taskmanager的内存
远程存储用的是jobmanager的内存
fs:(适用于一般状态作业,分钟级别的窗口聚合)
本地存储用的是taskmanager的内存
远程存储用的是hdfs的文件系统中
rockDB:(适用于超大作业状态,天级别的窗口聚合,读写要求不高(因为要溢写磁盘))
本地存储在Taskmanager的rockDB数据库(noSQL,K/V 类型,需要序列化)中(内存+磁盘,内存不够溢写磁盘)
远程存在hdfs中
总结:
状态 ck <br /> 内存 TM的堆内存 JM的堆内存<br /> FS TM的堆内存 HDFS <br /> RocksDB RocksDB HDFS
创建方式
1.12:
new MemoryStateBackend()
new FsStateBackend()
new RocksDbStateBackend()
1.13:
memory、fs
memory:
//env.setStateBackend(new HashMapStateBackend());本地内存
//env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());远程内存
fs:
//env.setStateBackend(new HashMapStateBackend());本地内存
// env.getCheckpointConfig().setCheckpointStorage(“hdfs://hadoop162:8020/ck”);远程磁盘
rockdb <br /> //env.setStateBackend(new EmbeddedRocksDBStateBackend());本地内存+磁盘<br /> //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop162:8020/ck/rocks");远程磁盘
长窗口,大键值状态,高可用形态
建议,管理内存设置为0
确保内存使用无上限
上图是fs的远程存储hdfs,chk-20会随着ck次数增加而变大
因为ck是设置了每多少时间做一次,会不断加大,
这里有个问题是ck时间越长,丢失数据的风险越大,因为先在内存做ck,等时间完后落盘,保存
所以考虑到丢数问题,ck设置得越小越好,
但是从性能上来说,ck越小对性能要求越高,所以要看业务需求
容错机制
状态的一致性
at-most-once(最多一次): 可能丢数据
at-least-once(至少一次):可能重复
exactly-once(严格一次) 不多也不少
端到端的状态一致性
source端
需要外部源可重设数据的读取位置!!.(比如flink消费kafka数据消费到offset=100,此时宕机,希望从kafka中从offset=100的位置重新消费,可指定offset进行消费)
目前我们使用的Kafka Source具有这种特性: 读取数据的时候可以指定offset
flink内部
sink端
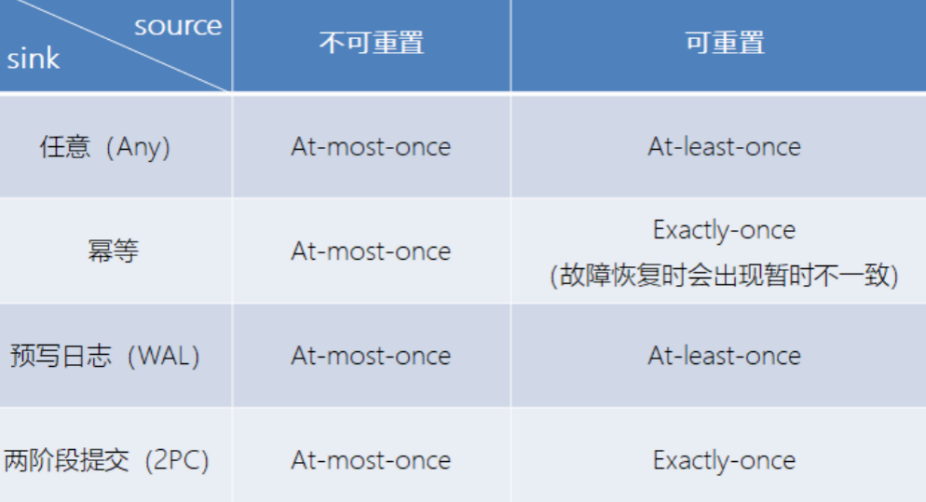
需要保证从故障恢复时,数据不会重复写入外部系统. 有2种实现形式:
a) 幂等(Idempotent)写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
b) 事务性(Transactional)写入
需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
例如:
消费者需要加上--isolation-level read_uncommitted 以保证可以提交事务后才消费,默认是未提交都能消费
幂等性
执行一次和执行n次结果一样
(本质上是覆盖,因为一般是针对数据是否插入成功来看,不会追加,数据本身是不会改变的)
es--幂等<br /> 只要写入id一致就能保证幂等性<br /> mysql--幂等、事务
Checkpoint原理
定义
算法
checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性,比如 ,开启后运行中报错会自动重启。
,开启后运行中报错会自动重启。
快照的实现算法:
a) 简单算法—暂停应用, 然后开始做检查点, 再重新恢复应用
b) Flink的改进Checkpoint算法. Flink的checkpoint机制原理来自”Chandy-Lamport algorithm”算法(钱笛拉波特算法)(分布式快照算)的一种变体: 异步 barrier 快照(asynchronous barrier snapshotting)
异步表现在不需要停止程序来做checkpoint
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作。
barrier
在多并行度下, 如果要实现严格一次, 则要执行barrier对齐.
CheckpointCoordinator 会生成barrier,从source源头开始注入 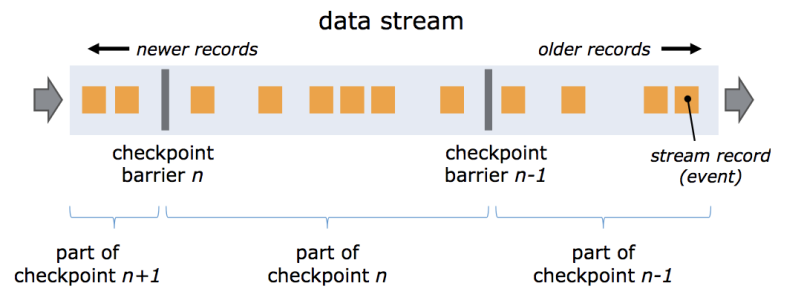
不会跨越流中数据,会随着数据流动而流动,可以看成数据流中的一个特殊数据。
task(算子)看到barrier开始做checkpoint
1、source-kafka看到barrier,开始对自己的offset进行ck,ck完成后,将备份数据的地址(state handle(hdfs))通知给 Checkpoint coordinator
2、flink内部算子算子,同样ck返回地址
3、sink,同样ck并返回地址
coordinator收集到sink的ck数据后,会额外备份一份元数据到hdsf
至少一次语义: barrier不对齐
对象:拥有两个输入流的 Operators(例如 CoProcessFunction)
会执行 barrier 对齐(barrier alignment)
对齐理由比较简单,这里讨论不对齐的情况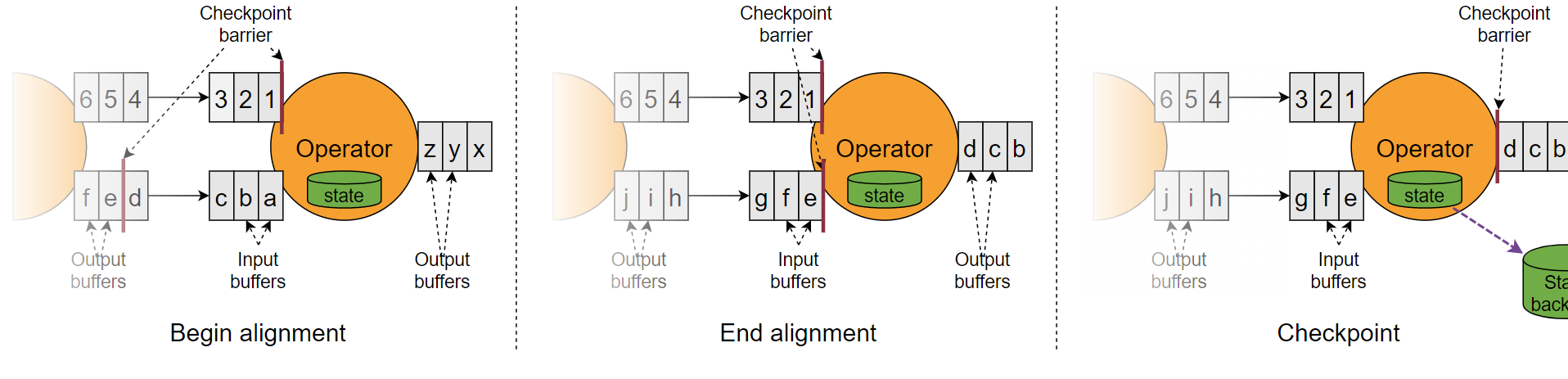
这里checkpoint n 如果不等待对齐就做快照,那么快照就是zyx,
快照部分过去后继续处理checkpoint n+1 的 123,
此时字母流部分还在checkpoint n 还没完成,假设就在此时宕机
那么数字流和字母流都需要从checkpoint n-1 开始重新处理,即xyz前的barrier重新处理
此时字母流的快照:zyx的数据就会发生重复,因为做过一次快照了
Kafka+Flink+Kafka 实现端到端严格一次
案例:Flink10_Checkpoint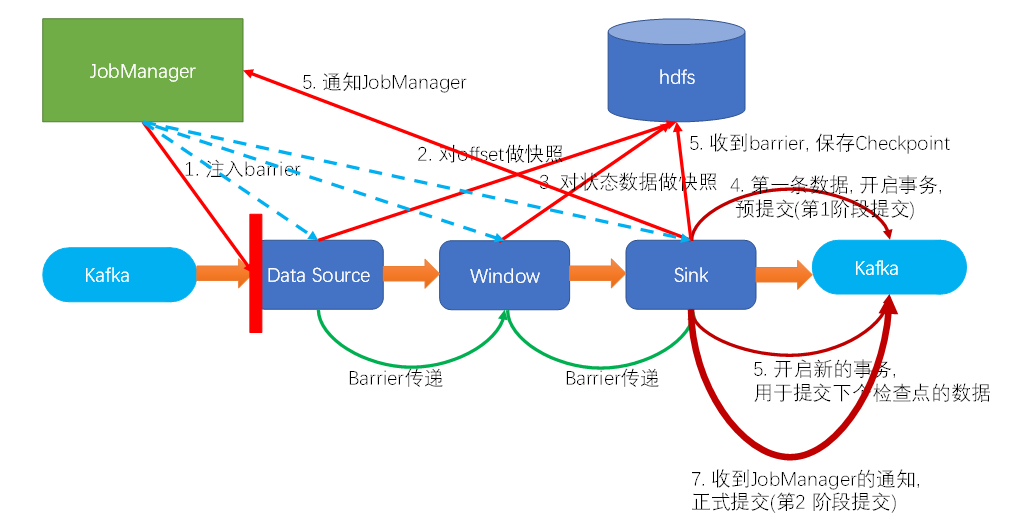
具体的两阶段提交步骤总结如下:
jm的协调器注入barrier到source
source遇到barrier做快照
barrier向后传递并对其
对状态做快照。。。
预提交:sink在遇到barrier时,将数据预写到kafka,同时开始下一波写到kafka的事物,并进行本波checkpoint,等ck完成。
当sink的ck完成,此时jm认为所有操作都完成,通知所有算子,已经完成
第二阶段提交: 此时sink提交事务,完成第二阶段提交
例如:
消费者需要加上--isolation-level read_uncommitted 以保证可以提交事务后才消费,默认是未提交都能消费
完整指令:
bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic s2 ----isolation-level read_uncommitted
数据恢复
案例:Flink10_Checkpoint_2
宕机重启,在idea中是2个应用
idea无法识别这两个应用是不是同一个,
必须打包到flink应用程序中运行
模拟:
1在页面kill掉job模拟宕机
2再在生产者中生产新数据,此时消费者接收不到数据
3重新通过以下指令启动bin/flink run -d -s hdfs://hadoop162:8082/flink/checkpoints/fs/307eb20442a1b97a3f9633a109fdd226/chk-208 -c com.atguigu.chapter07.state.Flink10_Checkpoint_2 flink210223-1.0-SNAPSHOT.jar
说明:-s指定ck位置,精准到 xxx/chk-208
4观察消费者,发现再次对第2步中新生产的数据进行消费
说明:此时甚至更改jar应用都可以,只要输入数据结构符合要求
savepoint
手动版的checkpoint,
checkpoint是自动创建的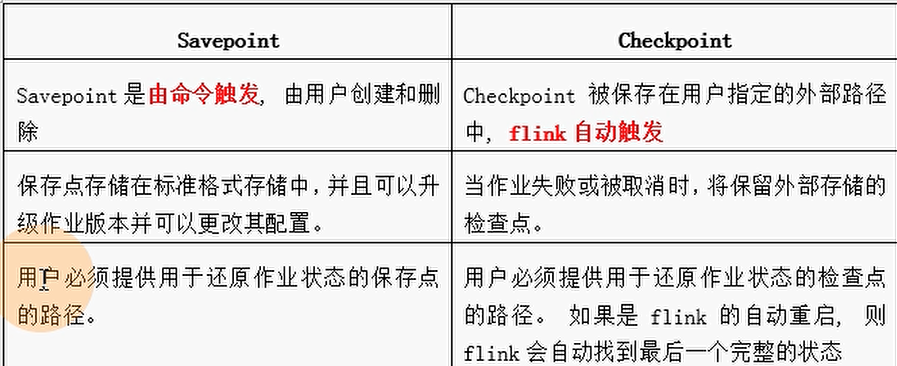
1. Flink 还提供了可以自定义的镜像保存功能,就是保存点(savepoints)
2. 原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点
3. Flink不会自动创建保存点,因此用户(或外部调度程序)必须明确地触发创建操作
4. 保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等
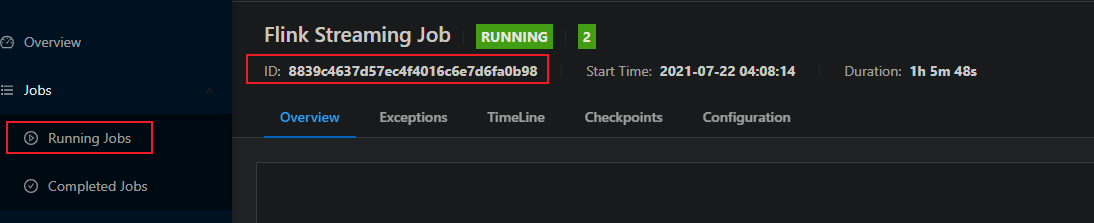
为保存点提供 job id 和 hdfs存储路径
bin/flink savepoit 8839c4637d57ec4f4016c6e7d6fa0b98 hdfs://hadoop162:8020 /sp(存储savepoint路径)
存储后,将之前的程序杀死,重新启动,指定保存点路径
bin/flink run -d -s hdfs://hadoop162:8082/sp(存储savepoint路径) -c com.atguigu.chapter07.state.Flink10_Checkpoint_2 flink210223-1.0-SNAPSHOT.jar


若有收获,就点个赞吧
0 人点赞
