学习目标:
①从宏观上了解Job(Spark on YARN)提交的流程。(画图)
②了解Job在提交之后,进行任务的划分,Stage的划分,任务的调度的过程!
结合: 宽依赖,窄依赖,Stage,task , job
③了解整个Job在执行期间Driver和Executor之间的通信方式
④Shuffle (区别不同的shuffle)
Spark是如何实现Shuffle!1
不同的Shuffle的效率影响!
⑤Spark的内存管理 (只有统一内存管理,用什么GC回收器)
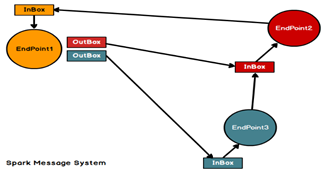
spark的通信框架
spark每个终端(endpoint)都会有以后收信箱(inbox),还可以选择启动多个发信信箱(outbox),具体由需要发送给什么终端决定。
每个终端通过dispatcher,将信息发送给本地或者其他终端,
如果发送个其他终端则先将信息发送到outbox,之后通过transportClient将数据发送出去,由别的终端的transportServer接收后传输到inbox,被其他终端消费,依据是指向inbox的标识nettyRpcEndpointRef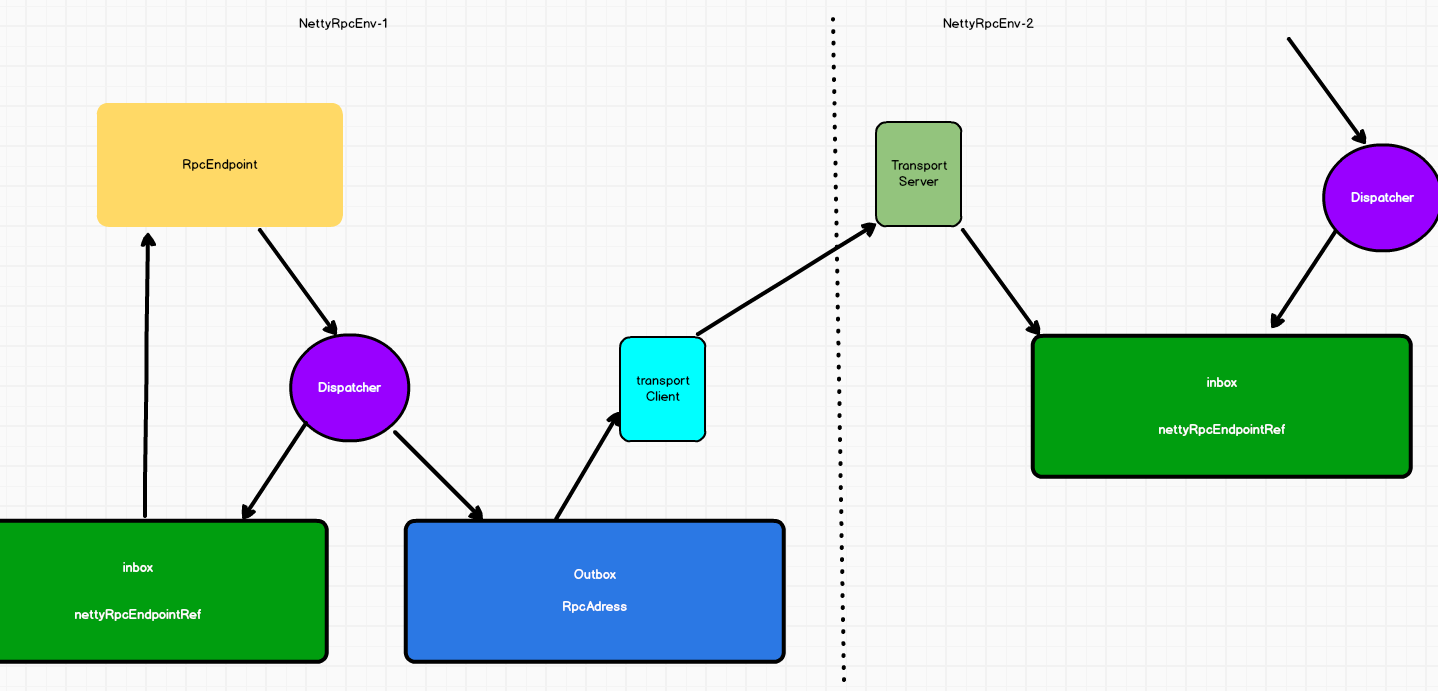
spark的app部署模式
SparkOnYarnClient提交流程:

client模式的源码解析:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-yarn_2.12</artifactId><version>3.0.0</version></dependency>spark-submit --master yarn --xxx xx com.atguigu.spark.WordCount /input-----------------------------------第一部分: 客户端和YARN通信org.apache.spark.deploy.SparkSubmit.main-- submit.doSubmit(args)--super.doSubmit(args)// 解析spark-submit后传入的参数,加载spark默认的参数-- val appArgs = parseArguments(args)--submit(appArgs, uninitLog)--doRunMain()//运行spark-submit 提交的主类 中的main方法--runMain(args, uninitLog)// 如果deployMode == CLIENT,此时childMainClass=自己提交的全类名// 如果deployMode == CLUSTER,是YARN集群 childMainClass=org.apache.spark.deploy.yarn.YarnClusterApplication--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)//创建childMainClass的Class类型--mainClass = Utils.classForName(childMainClass)--val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]} else {//如果是client 模式,此时运行下一行new JavaMainApplication(mainClass)}//JavaMainApplication.start-- app.start(childArgs.toArray, sparkConf)//获取用户编写的 app类的main-- val mainMethod = klass.getMethod("main", new Array[String](0).getClass)//执行main方法,Driver启动--mainMethod.invoke(null, args)------------------------------------------------------------------------第二部分: WordCount.mainSparkContext sc=new SparkContextSparkContext的重要组件:private var _taskScheduler: TaskScheduler = _ //负责Task的调度private var _dagScheduler: DAGScheduler = _ // Job中DAG Stage的切分private var _env: SparkEnv = _ // RpcEnv(通信环境) BlockManager(存数据)--------------_taskScheduler = ts_taskScheduler.start()//YarnClientSchedulerBackend.start()--backend.start()-- client = new Client(args, conf, sc.env.rpcEnv)//提交应用程序到YARN-- bindToYarn(client.submitApplication(), None)//参考cluster模式--......--在容器中运行的AM的全类名: org.apache.spark.deploy.yarn.ExecutorLauncher-----------------------------第二部分:启动AMorg.apache.spark.deploy.yarn.ExecutorLauncher.main//ExecutorLauncher 是对AM的封装,也是AM的实现ApplicationMaster.main(args)-- --master.run()if (isClusterMode) {--runDriver()} else {//client模式运行runExecutorLauncher() //申请Container启动Executor}----------------------------------------------------------------------------// YarnClusterApplication.start() Client是可以和yarn进行通信的一个客户端--new Client(new ClientArguments(args), conf, null).run()--this.appId = submitApplication()// 提交应用程序到YARN上,获取YARN的返回值-- val newApp = yarnClient.createApplication()//确定app保存临时数据的作业目录,通常是在hdfs中的/tmp目录中生成一个子目录-- val appStagingBaseDir = sparkConf.get(STAGING_DIR)//确保YARN有足够的资源运行当前app的 AM// 如果集群资源不足,此时会阻塞,一直阻塞到超时,会FAILD-- verifyClusterResources(newAppResponse)-- val containerContext = createContainerLaunchContext(newAppResponse)// 确定AM的主类名// AM是YARN提供的一个接口// 任何的应用程序如果希望提交APP到YARN,实现AM的接口// MR写的app,MR实现AM// spark写的App,spark实现AM--val amClass =if (isClusterMode) {//集群模式AM的全类名是org.apache.spark.deploy.yarn.ApplicationMasterUtils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName} else {Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName}-- val appContext = createApplicationSubmissionContext(newApp, containerContext)//提交运行AM-- yarnClient.submitApplication(appContext)
SparkOnYarnCluster提交流程架构图示:
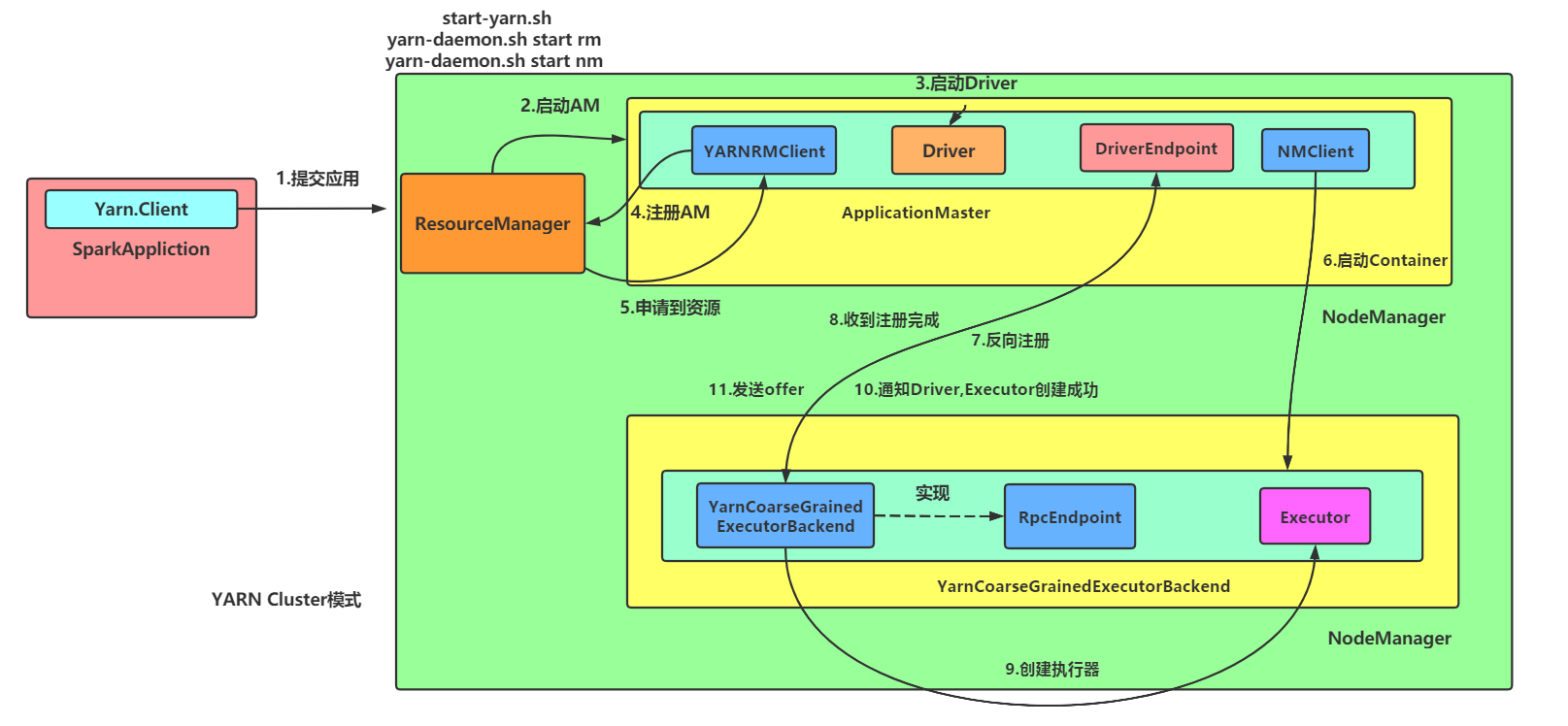
流程源码概述:
1、客户端与yarn通信:
1)通过:spark-submit --master yarn --deploy-mode cluster --xxx xx com.atguigu.spark.WordCount /input指令
2)启动执行org.apache.spark.deploy.SparkSubmit.main进程,启動client线程,在客户端中提交申请应用给resouremanage
3)之后resourceManager找到一台nodemanager
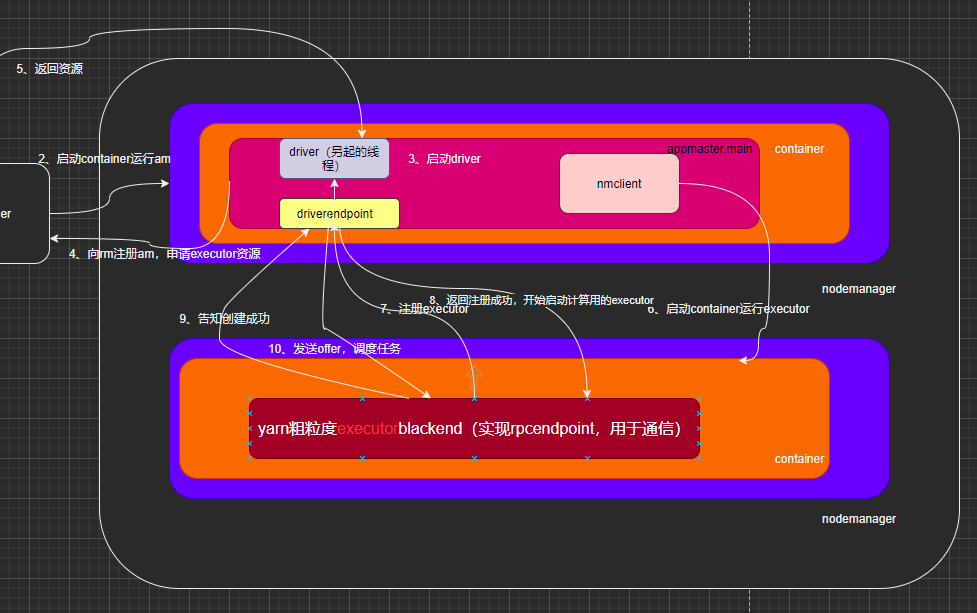
2、AM进程启动
1)創建amContainer并在其中执行ApplicationMaster.main.run 方法,启动一个线程来运行用户自己编写的app应用程序,并起名为“Driver”
2)等用户的app运行完毕,获取用户自己创建的sparkContext,通過獲取sparkContext的參數向RM汇报AM启动成功(registerAM,其实是注册)并申请Executor的资源:container
3)之后RM返回其资源列表给appmaster,master获取到已经分配的container,在其中运行进程,每个container都会创建一个 ExecutorRunnable,交给线程池运行
4)org.apache.spark.executor.YarnCoarseGrainedExecutorBackend就是那个运行的进程,這個進程就是我們的executor
3、启动YarnCoarseGrainedExecutorBackend进程(executor,负责通信):
1)进程中向driver请求spark配置信息:new SparkConf,与driver产生通信
2)并且给当前进程在网络中起了一个“Executor”别名,这里的负责通信的executor和下面负责计算的executor都是图中所说的executor,只是负责的功能不一样
其中:进程YarnCoarseGrainedExecutorBackend别名就是executor,负责通信
而这个进程类中,就有个属性 val executor =null ;负责计算
下图所框出来的起始就是负责通信的executor
3)之后该进程向Dirver发送RegisterExecutor的反向注册信息,Driver接收到注册信息后返回注册成功信息
4)注册成功过后,YarnCoarseGrainedExecutorBackend.receive方法接收到返回信息,开始调用父类GrainedExecutorBackend的Executor,(spark的计算者,他维护 了一个线程池,用来计算各种Task,但需要等待driver发送task过来才能运行。)之后返回executor启动成功的信息给driver
5)之后driver线程调用DriverEndPoint.receive方法处理过来的信息,并向Executor调度工作任务makeOffers(上图的发offers,就是指派任务的意思):(Task)
task如何发送:
//从调度池(TaskSet)中,根据TaskSet的优先级,调度其中的Task。
// 按照轮流发送的原则将Task调度到所有的Executor,保证负载均衡。
//调度应该发往次Executor的Task
6)之后反序列化task,然后创建task运行线程new TaskRunner(context, taskDescription)执行task:
ResultTask
ShufflerTask
cluster模式的源码解析:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-yarn_2.12</artifactId><version>3.0.0</version></dependency>spark-submit --master yarn --deploy-mode cluster --xxx xx com.atguigu.spark.WordCount /input-----------------------------------第一部分: 客户端和YARN通信org.apache.spark.deploy.SparkSubmit.main-- submit.doSubmit(args)--super.doSubmit(args)// 解析spark-submit后传入的参数,加载spark默认的参数-- val appArgs = parseArguments(args)--submit(appArgs, uninitLog)--doRunMain()//运行spark-submit 提交的主类 中的main方法--runMain(args, uninitLog)// 如果deployMode == CLIENT,此时childMainClass=自己提交的全类名// 如果deployMode == CLUSTER,是YARN集群 childMainClass=org.apache.spark.deploy.yarn.YarnClusterApplication--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)//创建childMainClass的Class类型--mainClass = Utils.classForName(childMainClass)--val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {//如果是cluster 模式,此时运行下一行mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]} else {new JavaMainApplication(mainClass)}-- app.start(childArgs.toArray, sparkConf)// YarnClusterApplication.start() Client是可以和yarn进行通信的一个客户端--new Client(new ClientArguments(args), conf, null).run()--this.appId = submitApplication()// 提交应用程序到YARN上,获取YARN的返回值-- val newApp = yarnClient.createApplication()//确定app保存临时数据的作业目录,通常是在hdfs中的/tmp目录中生成一个子目录-- val appStagingBaseDir = sparkConf.get(STAGING_DIR)//确保YARN有足够的资源运行当前app的 AM// 如果集群资源不足,此时会阻塞,一直阻塞到超时,会FAILD-- verifyClusterResources(newAppResponse)-- val containerContext = createContainerLaunchContext(newAppResponse)// 确定AM的主类名// AM是YARN提供的一个接口// 任何的应用程序如果希望提交APP到YARN,实现AM的接口// MR写的app,MR实现AM// spark写的App,spark实现AM--val amClass =if (isClusterMode) {//集群模式AM的全类名是org.apache.spark.deploy.yarn.ApplicationMasterUtils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName} else {Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName}-- val appContext = createApplicationSubmissionContext(newApp, containerContext)//提交运行AM-- yarnClient.submitApplication(appContext)----------------------------------------第二部分 AM启动ApplicationMaster.main--master.run()--if (isClusterMode) {//cluster模式运行--runDriver()} else {runExecutorLauncher()}// 启动一个线程,运行用户自己编写的app应用程序的main方法--userClassThread = startUserApplication()//为线程起名Driver--userThread.setName("Driver")//等待用户自己编写的app的main方法运行结束后,获取用户自己创建的SparkContext--val sc = ThreadUtils.awaitResult(sparkContextPromise.future,Duration(totalWaitTime, TimeUnit.MILLISECONDS))// 向RM回报,AM已经启动成功了--registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)// 创建一个可以向RM申请资源的对象,申请资源启动Executor-- createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)//allocator: YarnAllocator 作用就是向RM申请Container,决定获取到COntainer后,使用Container干什么--allocator = client.createAllocator()--allocator.allocateResources()//发送申请请求-- val allocateResponse = amClient.allocate(progressIndicator)//从YARN的响应中获取已经分配的Container--val allocatedContainers = allocateResponse.getAllocatedContainers()//处理申请到的Container-- handleAllocatedContainers(allocatedContainers.asScala)//在Container中运行进程-- runAllocatedContainers(containersToUse)//每个Container都会创建一个ExecutorRunnable,交给线程池运行--new ExecutorRunnable.run-- nmClient = NMClient.createNMClient()nmClient.init(conf)nmClient.start()//准备容器中的启动进程startContainer()--org.apache.spark.executor.YarnCoarseGrainedExecutorBackend 容器中启动的进程--val commands = prepareCommand()org.apache.spark.executor.YarnCoarseGrainedExecutorBackend①本身就是一个通信端点②var driver: Option[RpcEndpointRef] = NoneRpcEndpointRef: 某个通信端点的引用类比为网络中的一个通讯设备都有唯一的电话号------------------第一部分: YarnCoarseGrainedExecutorBackend进程启动--YarnCoarseGrainedExecutorBackend.main-- CoarseGrainedExecutorBackend.run(backendArgs, createFn)//向Driver请求spark的配置信息--val executorConf = new SparkConf// 当前进程在网络中有一个通信的别名称为Executor-- env.rpcEnv.setupEndpoint("Executor",backendCreateFn(env.rpcEnv, arguments, env, cfg.resourceProfile))//阻塞,一直运行,除非Driver发送停止命令--env.rpcEnv.awaitTermination()constructor -> onStart -> receive* -> onStop--------------------------------------第二部分: YarnCoarseGrainedExecutorBackend进程向Driver发送注册请求onStart// ref:RpcEndpointRef 代表Driver的通信端点引用(电话号)// 向Driver发RegisterExecutor消息,请求答复一个Boolean的值-- ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls,extractAttributes, _resources, resourceProfile.id))}(ThreadUtils.sameThread).onComplete {case Success(_) =>//成功,自己给自己发 RegisteredExecutor消息self.send(RegisteredExecutor)//失败,进程就退出case Failure(e) =>exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)-------------------------------------第三部分: Driver处理注册请求DriverEndPoint.receiveAndReply--case RegisterExecutor-- ①判断是否已经注册过了,如果注册过了,回复失败; 判断是否拉黑,拉黑,注册失败,-- 否则注册,注册完成后,回复truecontext.reply(true)----------------------------------------第四部分: YarnCoarseGrainedExecutorBackend 注册成功后YarnCoarseGrainedExecutorBackend.receive-- case RegisteredExecutor =>logInfo("Successfully registered with driver")try {// Spark的计算者,维护了一个线程池,用来计算各种Taskexecutor = new Executor(executorId, hostname, env, userClassPath, isLocal = false,resources = _resources)// 给Driver发LaunchedExecutor消息driver.get.send(LaunchedExecutor(executorId))-----------------------------------------------------第五部分: Driver处理LaunchedExecutor请求DriverEndPoint.receive-- case LaunchedExecutor(executorId) =>executorDataMap.get(executorId).foreach { data =>data.freeCores = data.totalCores}//Driver向Executor发送工作任务(Task)makeOffers(executorId)//从调度池中,根据TaskSet的优先级,调度其中的Task。// 按照轮流发送的原则将Task调度到哦所有的Executor,保证负载均衡。//调度应该发往次Executor的Task--scheduler.resourceOffers(workOffers)-- launchTasks(taskDescs)-- val serializedTask = TaskDescription.encode(task)//为要发送的Executor打个招呼,发送Task--executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))--------------------------------------------------第六部分: Executor收到Task-- case LaunchTask(data) =>if (executor == null) {exitExecutor(1, "Received LaunchTask command but executor was null")} else {// 反序列化得到Task的描述(TaskDescription)val taskDesc = TaskDescription.decode(data.value)logInfo("Got assigned task " + taskDesc.taskId)taskResources(taskDesc.taskId) = taskDesc.resources//启动Task的运算executor.launchTask(this, taskDesc)//创建一个Task运行的线程-- val tr = new TaskRunner(context, taskDescription)runningTasks.put(taskDescription.taskId, tr)// 启动线程threadPool.execute(tr)--TaskRunner.run()//构造可以运行的Task对象--task = ser.deserialize[Task[Any]]//运行Task获取结果-- val res = task.run()// ShuffleMapTask 或 ResultTask--runTask(context)}
job的stage的task的调度
- Application: 应用
Job: 任务 .—>一个行动算子一个job
stage: 阶段
task: 单个任务
一个SparkContext对应一个Application
一个Application对应多个Job,一个action(行动算子)产生一个job
一个job中对应多个stage,stage的个数 = shuffle个数(shufflerMapStage) + 1(ResultStage),也就是说一个action对应一个resultStage
* 一个stage对应多个task,task的个数 = 当前stage中最后一个rdd的分区数
一个task也对应多个stage
只有Executor的代码会产生job,Driver端执行的代码不走job
stage与task是交叉关系
下图是一个job: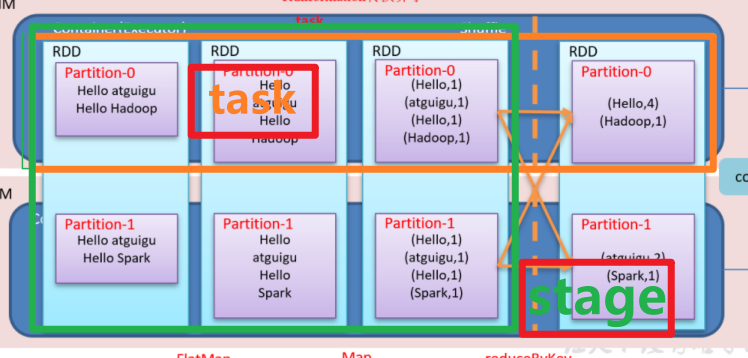
task源码流程概述
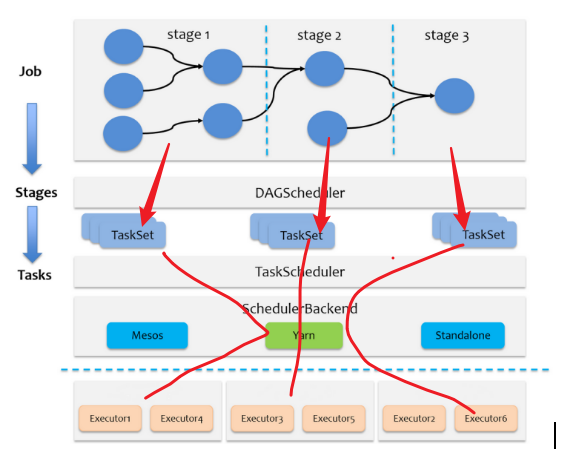
在driver中:
rdd.collect处理各分区的task汇聚成job
通过dagScheduler.handleJobSubmitted方法,开始创建stage
递归依次从后往前找,将ResultStage的所有祖先 ShuffleMapStage都创建完毕,最后才创建最后一个Stage:finalStage = createResultStage
然后提交ResultStage、ShuffleMapStage。
之后根据Stage类型创建对应的Task,(ShuffleMapStage =>new ShuffleMapTask,ResultStage =>new ResultTask)
task个数根据当前Stage要计算的分区数(最后一个stage的分区数)确定
task在hadoop的mr里和在spark的区别
hadoop中:maptask、reducetask:进程级别
spark中:ShuffleMapTask 或ResultTask:线程级别
task调度源码解释
Task的产生--------------RDD.collect--val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)//判断是否存在闭包,闭包变量是否可以序列化-- val cleanedFunc = clean(func)-- dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)-- val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)// event处理循环,放入一个事件 JobSubmitted ,提交job// eventProcessLoop = new DAGSchedulerEventProcessLoop-- eventProcessLoop.post(JobSubmitted())--EventLoop.onReceive(event)-- doOnReceive(event)--case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)----------------------dagScheduler.handleJobSubmitted// Job的最后一个阶段stage--var finalStage: ResultStage = null-- finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)-- 递归依次从后往前找,将ResultStage的所有祖先 ShuffleMapStage都创建完毕,最后才创建最后一个Stage-- val parents = getOrCreateParentStages(rdd, jobId)--val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)// ResultStage创建完毕后,才会生成Job-- val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)//提交ResultStage--submitStage(finalStage)//查看当前阶段有没有未提交的父阶段,按照父阶段的ID排序--val missing = getMissingParentStages(stage).sortBy(_.id)//如果父阶段未提交,按照顺序依次提交,最后提交自己--if (missing.isEmpty) {logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")submitMissingTasks(stage, jobId.get)} else {for (parent <- missing) {submitStage(parent)}waitingStages += stage}// 根据Stage类型创建对应的Task,创建时,根据当前Stage要计算的分区数确定// 如何知道每一个Stage要计算的partition的数量? 取决于Stage最后一个RDD的分区数--val tasks: Seq[Task[_]] = try {val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()stage match {case stage: ShuffleMapStage =>stage.pendingPartitions.clear()partitionsToCompute.map { id =>val locs = taskIdToLocations(id)val part = partitions(id)stage.pendingPartitions += idnew ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())}case stage: ResultStage =>partitionsToCompute.map { id =>val p: Int = stage.partitions(id)val part = partitions(p)val locs = taskIdToLocations(id)new ResultTask(stage.id, stage.latestInfo.attemptNumber,taskBinary, part, locs, id, properties, serializedTaskMetrics,Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,stage.rdd.isBarrier())}}//将每个Stage的task放入调度池,通知Driver,去调度// TaskSet: 包含了一个Stage所有的Tasks, 一个Task的集合--taskScheduler.submitTasks(new TaskSet(tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))//TaskSetManager: 追踪每一个TaskSet中所有Task的运行情况,在它们失败时重启。通过延迟调度// 处理位置敏感的调度,调度每个Task--val manager = createTaskSetManager(taskSet, maxTaskFailures)//将TaskSetManager加入调度池(FIFO | FAIR),不同的调度池,会决定不同的TaskSet被调度的优先级-- schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)-- backend.reviveOffers()//给Driver发消息,告诉Driver有新的TaskSetManager入池了,可以开始发送了-- driverEndpoint.send(ReviveOffers)-- case ReviveOffers =>makeOffers()
shuffler
什么是shuffler
在Spark中,很多算子都会引起RDD中数据的重分区!新的分区被创建,旧的分区被合并或数据被重新分配!在重分区的过程中,如果数据发生了跨节点的移动,就称为shuffle!
hashshuffler(过时)
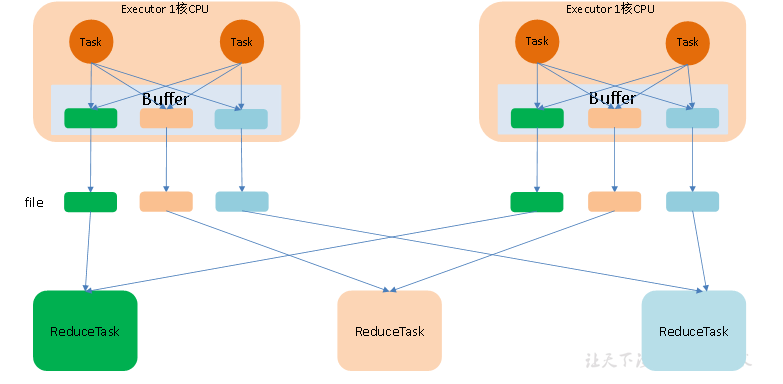
对应hadoop中的MR来解释
每个maptask(spark task)的数据会配分配到多个reducetask中,
N个maptask(spark task)分配到M个reducetask中就是生成:M*N个小文件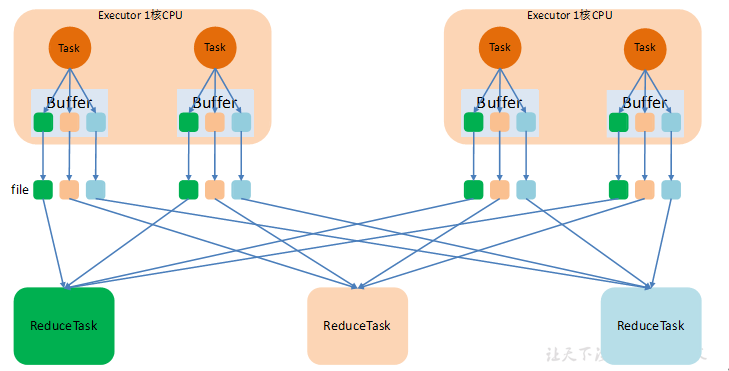
优化后的hashshuffler
原理:
core number: M
将所有task的内容写进一个core中
reduceTask个数:N
M*N个小文件
应用:
启合并机制的配置是spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。
SortShuffle(sort-based shuffle)
随着Hadoop2.0的发布,Spark借鉴了Hadoop2.0中的shuffle过程(sort-based shuffle)!
本质:
有由索引实现排序
sort-based shuffle核心要义:
1)一个MapTask最终只生成一个数据文件,
2)这一个数据文件中包含2个文件:
一个是包含有若干分区的数据文件,
另一个是包含索引的元数据文件,其中记录了分区的边界!
在产生文件时,默认SortShuffleWriter会进行排序!
3)并不是所有的sort-based shuffle都会对shuffle写出的数据进行排序!:
对比Hadoop2.0的shuffle:
在MapTask上,先分区———>溢写前,进行排序——->溢写为一个片段
所有片段全部溢写完成后———->merge———->合并为一个总的文件!
区别:
hadoop: MapTask: map————->sort————->merge
ReduceTask: sort————->reduce
spark : MapTask: map(各种算子)————->sort————->merge
ReduceTask: merge——->算子(reduce阶段不排序,算子中排序)
spark的shuffle在ReduceTask端不排序!
原因:
1)hadoop的reduce是一个迭代器,且只有一个map和reduce
如果有序:
(a,1),(a,1),(b,1)则输出(a,2),(b,1)
如果无序如:
(a,1),(b,1),(a,1) 则输出(a,1),(b,1),(a,1)
2)而spark会有一些算子实现排序:
- `mapPartitions` to sort each partition using, for example, `.sorted`- `repartitionAndSortWithinPartitions` to efficiently sort partitions while simultaneously repartitioning- `sortBy` to make a globally ordered RDD
普通SortShuffle
在该模式下,数据会先写入一个数据结构,reduceByKey写入Map,一边通过Map局部聚合,一遍写入内存。Join算子写入ArrayList直接写入内存中。然后需要判断是否达到阈值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
在溢写磁盘前,先根据key进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为10000条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是说一个Task过程会产生多个临时文件。
最后在每个Task中,将所有的临时文件合并,这就是merge过程,此过程将所有临时文件读取出来,一次写入到最终文件。意味着一个Task的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个Task的数据在文件中的索引,start offset和end offset。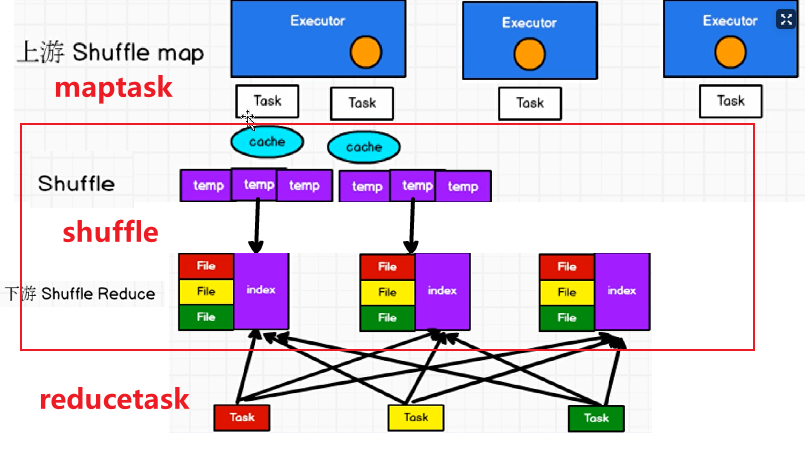
bypass SortShuffle
bypass运行机制的触发条件如下:
1) shuffle reduce task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200。
2) 不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟优化后的的HashShuffleManager是一模一样的,只多了创建的索引文件,通过索引文件,节省了排序功能,提升性能
而该机制与普通SortShuffleManager运行机制的不同在于:不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。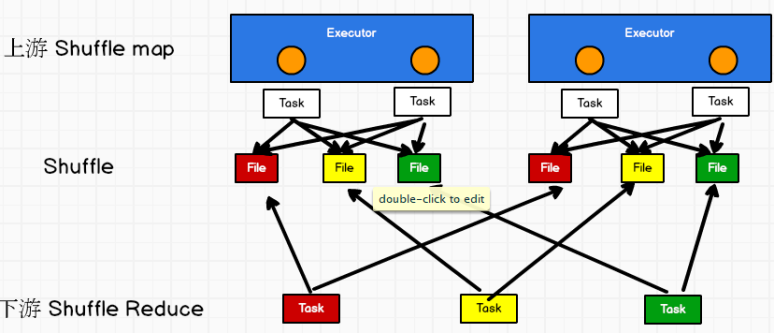

若有收获,就点个赞吧
0 人点赞
