内存模型


进程内存
| flink内存 堆内内存 框架堆内内存 task堆内内存 堆外内存 直接内存 框架堆外内存 task堆外内存 网络缓冲内存 管理内存 jvm内存 |
|---|
说明:
内存模型讲的是taskmanager的内存模型,一般也只调整taskmanager的内存模型
jobmanager内存一般不改,改以只改一点,因为他不处理数据也不保存数据
cpu优化
提交代码
bin/flink run \-t yarn-per-job \-d \-p 5 \ 指定并行度-Dyarn.application.queue=test \ 指定 yarn 队列-Djobmanager.memory.process.size=2048mb \ JM2~4G 足够-Dtaskmanager.memory.process.size=4096mb \ 单个 TM2~8G 足够-Dtaskmanager.numberOfTaskSlots=2 \ 与容器核数 1core:1slot 或 2core:1slot-c com.atguigu.flink.tuning.UvDemo \/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
使用 DominantResourceCalculator 策略

Yarn 的容量调度器默认情况下是使用“DefaultResourceCalculator”分配策略,只根 据内存调度资源,所以在 Yarn 的资源管理页面上看到每个容器的 vcore 个数还是 1。
可以修改策略为 DominantResourceCalculator,该资源计算器在计算资源的时候会 综合考虑 cpu 和内存的情况。
在 capacity-scheduler.xml 中修改属性: yarn.scheduler.capacity.resource-calculatororg.apache.hadoop.yarn.util.resource.DominantResourceCalculator
配置文件修改如下:
<property><name>yarn.scheduler.capacity.resource-calculator</name><!-- <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> --> --默认是container:core=1:1<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>--> 动态计算,例如上面的提交参数设置了每个taskmanager用2个slot,那么就会默认使用slot:core 1:1的数据量来执行</property>
使用 DominantResourceCalculator 策略

JobManager1 个,占用 1 个容器,
vcore=1 TaskManager3 个(因为并行度是5),占用 3 个容器,每个容器 vcore=2,总 vcore=2*3=6,
因为默认 单个容器的 vcore 数=单 TM 的 slot 数
使 用 DominantResourceCalculator 策 略 并 指 定 容 器 vcore 数
bin/flink run \-t yarn-per-job \-d \-p 5 \-Drest.flamegraph.enabled=true \-Dyarn.application.queue=test \-Dyarn.containers.vcores=3 \ --这里指定!!!!!!!!!1-Djobmanager.memory.process.size=1024mb \-Dtaskmanager.memory.process.size=4096mb \-Dtaskmanager.numberOfTaskSlots=2 \-c com.atguigu.flink.tuning.UvDemo \/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar

JobManager1 个,占用 1 个容器
vcore=1 TaskManager3 个,占用 3 个容器,每个容器 vcore =3,总 vcore=3*3=9
并行度优化
全局并行度计算,大概估算全局
开发完后,先进行测压。
任务并行度给10以下,测试单个并行度,看看有没有反压,有反压证明某个子任务到达瓶颈,看反压出现的节点 ,一般是看source,source的数据没有被处理过,能更直观显示问题。
看产生反压后的这个并行度往下游传递的速度(每秒钟能发送多少条数据)
随后:总 QPS/单并行度的处理能力 = 并行度
设置最好不要用平均qps,设置高峰的qps比较好
比如平均qps=1000条/s 高峰2万条/s,
而source端的产生反压的数据是5000条/s,
此时并行度=2万/5000=4
再预留0.2倍,4*1.2=5个并行度
压测:
现在造数据写到kafka,积压数据,之后用flink消费数据
比如用生产环境的数据,弄24小时的数据量到kafka或者用自己写到程序来造,然后用flink去消费
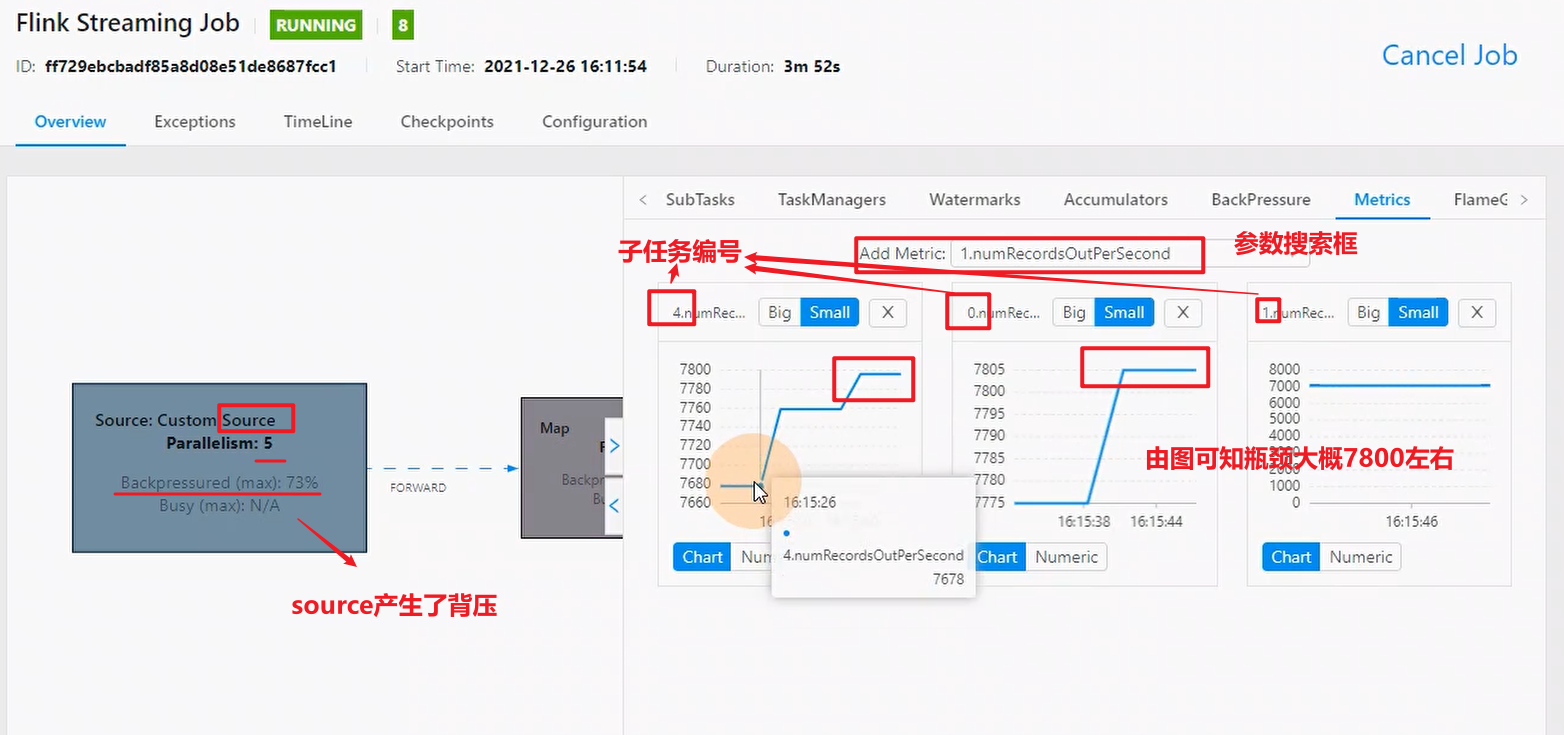
如上图,看到source中一个并行度峰值大概是7800
加入峰值qps=30000条每秒,那么并行度应该设置为:(30000/7800)*1.2=4.6,并行度给5合理

若有收获,就点个赞吧
0 人点赞
