Task与SubTask
一个算子就是一个Task. 一个算子的并行度是几, 这个Task就有几个SubTask
对应关系:
算子=>Task
并行度=>SubTask
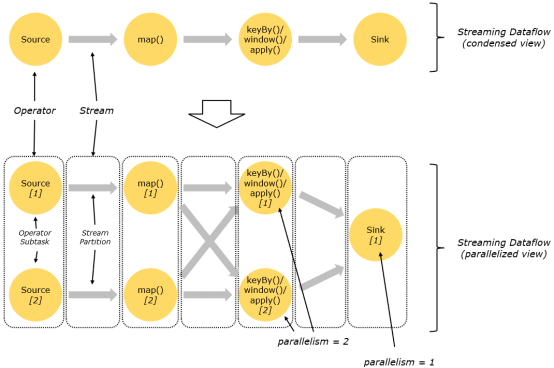
Parallelism并行度
关键点
不同的并行度(subtask),肯定在不同的slot,但也可能在不同的taskmanager
一个流程序的并行度,可以认为就是其所有算子中算子并行度最大的并行度
数据传输模式:
One-to-one:
类似于spark中的窄依赖
Redistributing
类似于spark中的宽依赖
stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)
例如,
keyBy()基于
hashCode重分区(类似shuffler)、
broadcast(一个流向多个)
rebalance(并行度不一致)
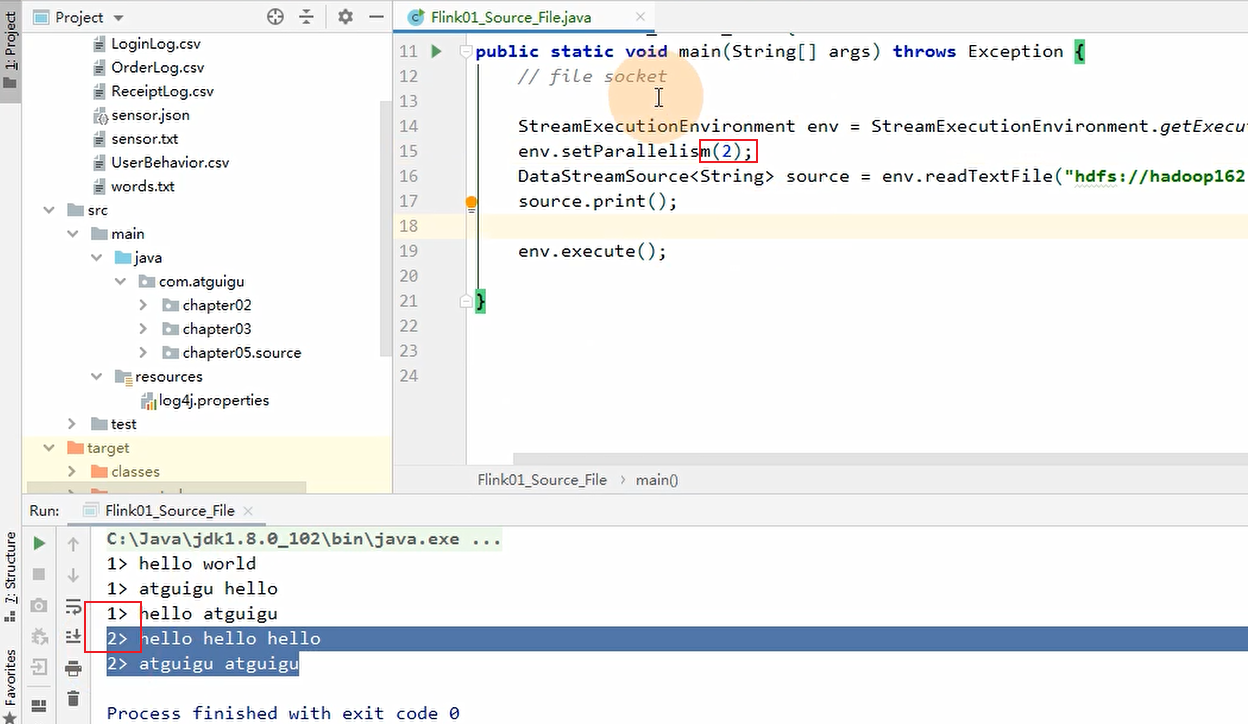
并行度在代码中的体现
设置并行度
如何控制操作链(生产环境下不会用):
1. .startNewChain()
从当前算子开启一个新链
2. .disableChaining()
当前算子不会和任何的算子组成链
3.env.disableOperatorChaining();
全局禁用操作链
给算子设置并行度(优先级越来越高,4最高):
1. 在配置文件中 flink.yaml parallelism.default: 1
2. 在提交job的时候通过参数传递 -p 3
3. 通过执行环境来设置并行度 env.setParallelism(1);
4. 单独的给每个算子设置并行度
Operator Chains(任务链)—>这是flink默认的优化
相同并行度的one to one操作,Flink将这样相连的算子链接在一起形成一个task,原来的算子成为里面的一部分。 每个subtask被一个线程执行.
将算子链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定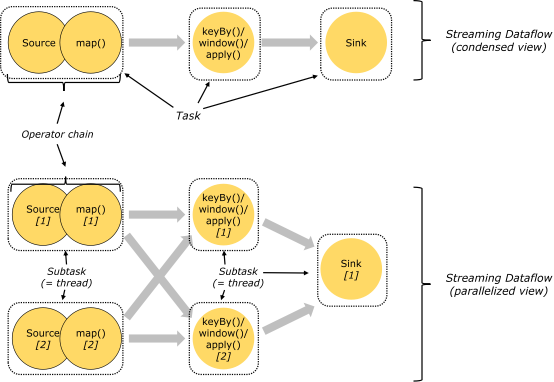
ExecutionGraph(执行图)(了解即可)
由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> Physical Graph。
Ø StreamGraph:
是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
Ø JobGraph:
StreamGraph经过优化后生成了 JobGraph,是提交给 JobManager 的数据结构。主要的优化为: 将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
Ø ExecutionGraph:
JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
Ø Physical Graph:
JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
2个并发度(Source为1个并发度)的 SocketTextStreamWordCount 四层执行图的演变过程
env.socketTextStream().flatMap(…).keyBy(0).sum(1).print();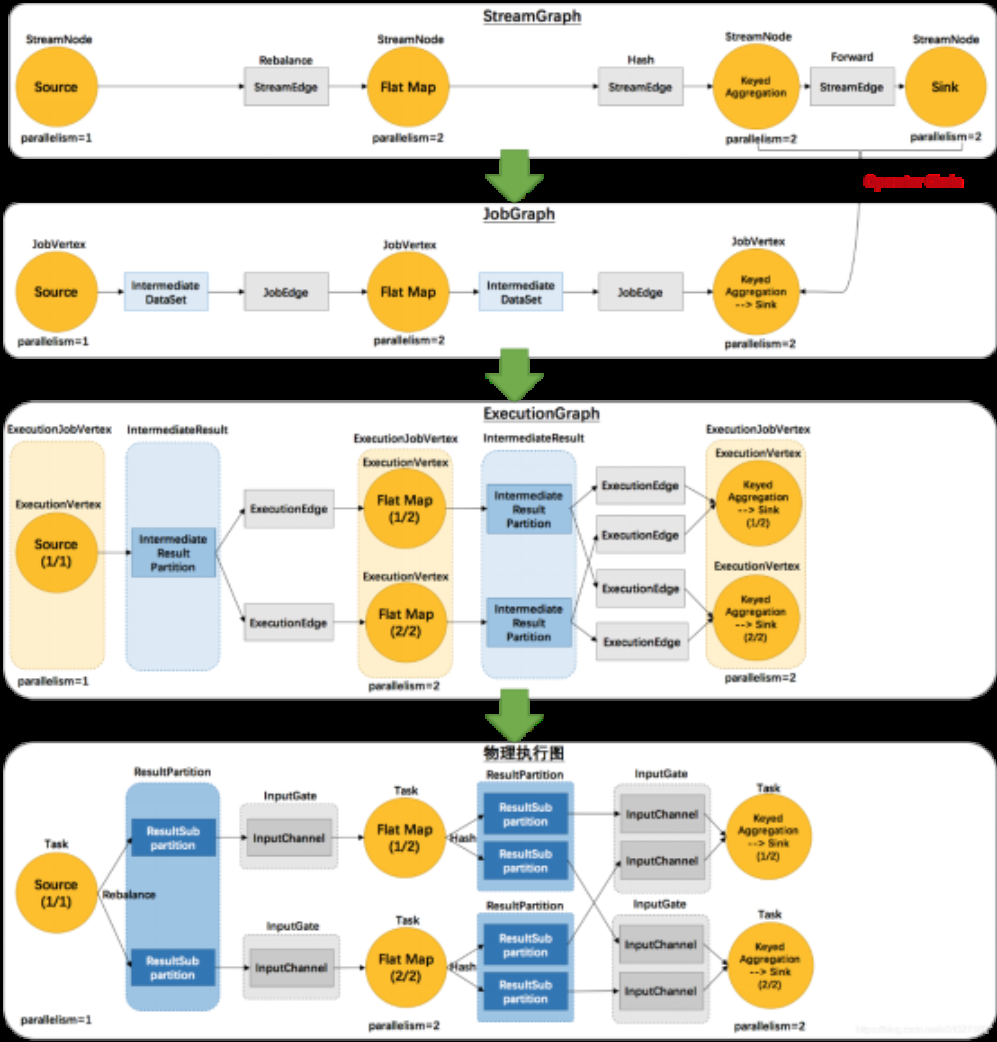

若有收获,就点个赞吧
0 人点赞
