什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。
代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
要点:
1、弹性:
存储弹性:内存不足,自动落盘
容错弹性:过程中断后,数据可以根据RDD流程重新读取并恢复数据
计算弹性:shuffle阶段如果访问下一RDD,会有默认的3次重试读取下一阶段的机会
分片弹性:也就是分片,和mr的切片一样,不同切片负责处理不同的block,在RDD中,也是不同的partition处理block
2、不可变
RDD封装计算逻辑,不保存数据
而且不可改变,要想改变,只能产生新的RDD
RDD五大特性
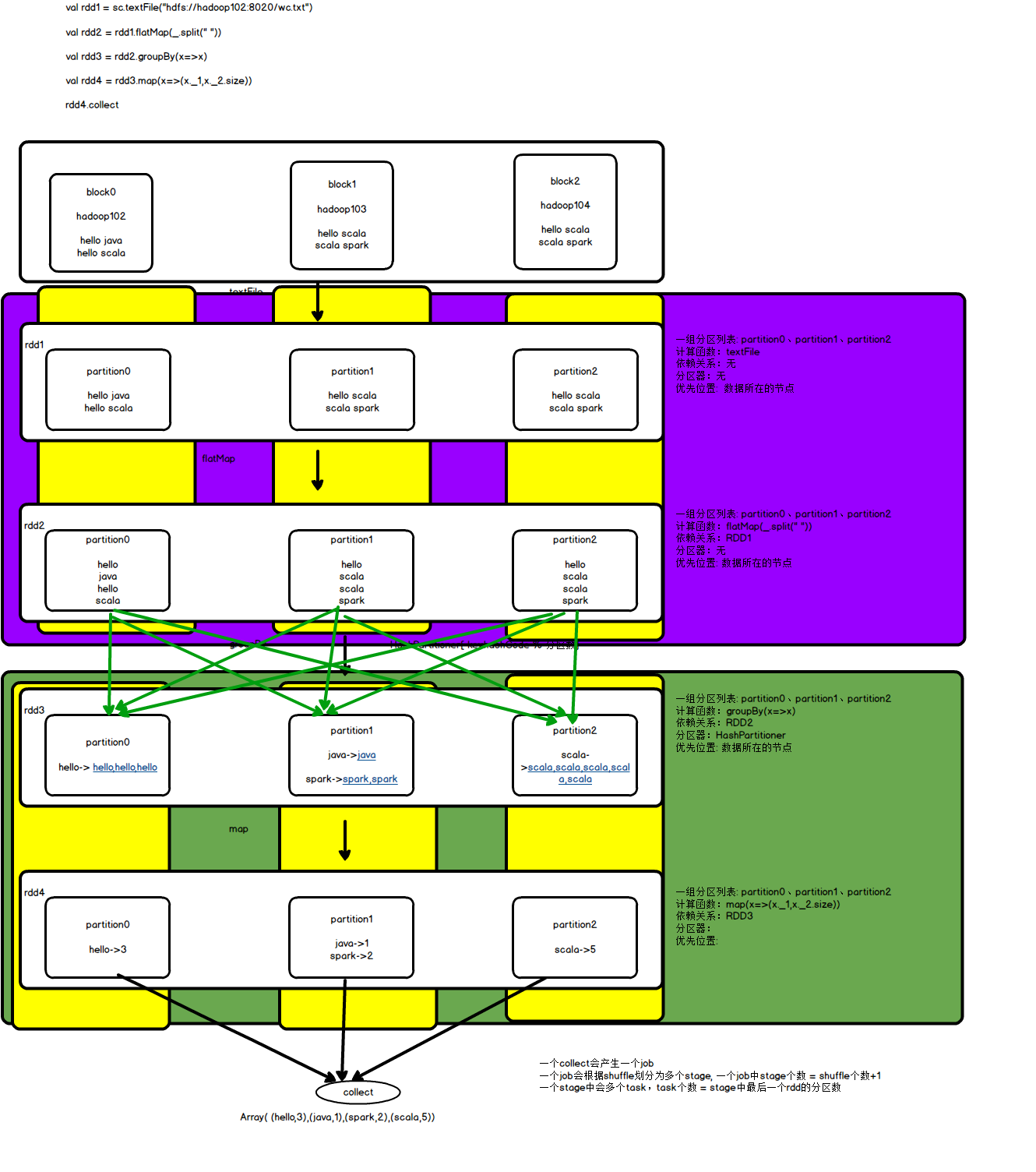 RDD类中对应这这5大特性的方法:
RDD类中对应这这5大特性的方法:
1、分区列表(getPartitions): 数据是分布式存储,所以在计算的时候也是分布式,一般读取HDFS文件的时候一个文件切片对应一个RDD分区
2、作用在每个分区上的计算函数(compute(Partition,TaskContex)): task计算的时候并行的,每个task计算逻辑是一样的,只是处理的数据不一样(同一个task被复制传输到不同节点上实现相同逻辑)
3、依赖关系(getDependencies): RDD不存储数据,RDD中只是封装数据的处理逻辑,如果数据出错需要根据依赖关系从头进行处理得到数据
4、分区器(partitioner): 在shuffle阶段,需要通过分区器将相同key的数据聚在一个分区统一处理
5、优先位置(getPreferredLocations(partition)): spark在分配task的时候最好将task分配到数据所在的节点,避免网络拉取数据影响效率
rdd编程
RDD的创建
通过集合创建:一般测试用
sc.makeRDD(集合)<br /> sc.parallelize(集合)<br /> makeRDD底层就是使用的parallelize
读取文件创建
sc.textFile(path)<br />总结:写绝对路径不会错:<br />想访问hdfs:sc.textFile("hdfs://hadoop102:8020/..../..")<br />想访问本地文件:sc.textFile("file:///../...")**1、在spark集群中如果有配置HADOOP_CONF_DIR,此时默认读取的是HDFS文件**<br />1)读取HDFS文件的3中方式
sc.textFile("/.../..")sc.textFile("hdfs://hadoop102:8020/..../..")sc.textFile("hdfs:///../..")
2)若配置了此参数,但还想读取本地文件:
sc.textFile("file:///../...")
2、在spark集群中如果没有配置HADOOP_CONF_DIR,此时默认读取的是本地文件
1)读取HDFS文件的时候:
sc.textFile("hdfs://hadoop102:8020/..../..")
2)读取本地文件:
sc.textFile("/.../..")sc.textFile("file:///../...")
通过其他RDD衍生
val rdd2 = rdd1.map/flatMap/..
分区规则
根据集合创建RDD的分区数
*<br /> * 1)numSlices参数没有配置,默认情况下<br /> * 如果有配置spark.default.parallelism,此时RDD的分区数 = spark.default.parallelism的值<br /> * 配置:new SparkConf().set("spark.default.parallelism","1").setMaster("local[4]").setAppName("test")<br /> * 如果没有配置spark.default.parallelism<br /> * 1、local模式<br /> * 如果是local[N]parallelism参数值<br /> * 如果是local[*],此时RDD的分区数 = cpu总核数<br /> * 如果是local, 此时RDD的分区数 = 1<br /> * 如果是standalone,此时RDD的分区数 = math.max(totalCoreCount.get(), 2)<br /> * totalCoreCount = 本次任务CPU总核数<br /> * 2、集群模式,此时RDD分区数 = 本次任务executor总核数<br /> * 2)如果numSlices有设置,此时RDD的分区数 = numSlices<br /> *<br /> */
package tcode.day02import org.apache.spark.{SparkConf, SparkContext}import org.junit.Testclass $02_RddPartition {val sc = new SparkContext(new SparkConf()/*.set("spark.default.parallelism","1")*/.setMaster("local[4]").setAppName("test"))@Testdef createRddByCollectionPartition(): Unit ={val rdd = sc.parallelize(List(1,4,7,2,5,9,10,20,43,55),4)rdd.mapPartitionsWithIndex((index,it) => {println(s"分区号=${index} 分区数据=${it.toList}")it}).collect()println(rdd.partitions.length)}}
源码解释
val slices = ParallelCollectionRDD.slice(data, numSlices).toArray//ParallelCollectionRDD.slice(data, numSlices).toArray//data = List(1,4,7,2,5,9,10,20,43,55)//numSlices = 4//def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = {// if (numSlices < 1) {// throw new IllegalArgumentException("Positive number of partitions required")// }// def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {// //length=10 numSlices=4//// (0 until numSlices)// // Range(0,1,2,3)// .iterator.map { i =>// //第一次执行 i = 0// // start = 0 end = 2// //第一次执行结果: (0,2)// //第二次执行 i = 1// // start = 2 end = 5// // 第二次执行结果: (2,5)// //第三次执行 i = 2// // start = 5 end = 7// // 第三次执行结果: (5,7)// //第四次执行 i = 3// // start = 7 end = 10// // 第四次执行结果: (7,10)// val start = ((i * length) / numSlices).toInt// val end = (((i + 1) * length) / numSlices).toInt// (start, end)// }//// }// seq match {// case _ =>// val array = seq.toArray// // array = Array(1,4,7,2,5,9,10,20,43,55)// //positions(10, 4)// //positions(array.length, numSlices)// //执行结果: Iterator[(0,2),(2,5),(5,7),(7,10)]// .map { case (start, end) =>// //第一次执行: (0,2)// //array.slice(0,2) 结果: Array(1,4)// //第二次执行: (2,5)// //array.slice(2,5) 结果: Array(7,2,5)// //第三次执行: (5,7)// //array.slice(5,7) 结果: Array(9,10)// //第四次执行: (7,10)// //array.slice(7,10) 结果: Array(20,43,55)// array.slice(start, end).toSeq// }//// .toSeq// //执行结果: Seq(Array(1,4),Array(7,2,5),Array(9,10),Array(20,43,55))// }//}//slices = Array(Array(1,4),Array(7,2,5),Array(9,10),Array(20,43,55))slices.indices//0 until slices.length = [0,1,2,3].map(i => new ParallelCollectionPartition(id, i, slices(i))).toArray//第一次: i = 0 new ParallelCollectionPartition(id, 0, Array(1,4))
通过读取文件创建RDD
RDD默认分区数>= math.min(defaultParallelism,2)<br /> 读取文件创建的RDD的分区数 = 文件的切片数
/*** 根据读取文件创建rdd的分区数 >= math.min(defaultParallelism, 2)*/@Testdef createRddByFilePartition(): Unit ={val rdd = sc.textFile("datas/wc.txt",4)// 如果这里不设置是4,则默认是RDD默认分区数>= math.min(defaultParallelism,2)println(rdd.partitions.length)}
源码解释
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],minPartitions)new HadoopRDD(this,confBroadcast,Some(setInputPathsFunc),inputFormatClass,keyClass,valueClass,minPartitions).setName(path)//得到文件所有切片val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)//对文件切片public InputSplit[] getSplits(JobConf job, int numSplits)throws IOException {//获取要读取的所有文件FileStatus[] files = listStatus(job);//统计要读取的所有文件的总大小long totalSize = 0;for (FileStatus file: files) {if (file.isDirectory()) {throw new IOException("Not a file: "+ file.getPath());}totalSize += file.getLen();}// totalSize = 75B// numSplits = 4// goalSize = 75 / 4 = 18 Blong goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);//long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);//minSize = Math.max(0,1) = 1//创建一个装载切片的数组ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);NetworkTopology clusterMap = new NetworkTopology();//遍历要读取的文件for (FileStatus file: files) {//获取当前文件的大小long length = file.getLen();if (length != 0) {FileSystem fs = path.getFileSystem(job);BlockLocation[] blkLocations;//获取文件块位置if (file instanceof LocatedFileStatus) {blkLocations = ((LocatedFileStatus) file).getBlockLocations();} else {blkLocations = fs.getFileBlockLocations(file, 0, length);}//if (isSplitable(fs, path)) {//获取当前文件块的大小 【HDFS文件块大小=128M,本地文件块的大小=32M】long blockSize = file.getBlockSize();// 计算切片大小long splitSize = computeSplitSize(goalSize, minSize, blockSize);//splitSize = Math.max(1, Math.min(18, 32)) = 18B//循环切片long bytesRemaining = length;while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {// 因为goalSize是整除求出来的,而这里循环用的是double,所以会有5个切片// 第一次循环: 75/18 = 4.12 >1.1// 第一个切片: 从0B开始切18B// bytesRemaining = 75-18 = 57// 第二次循环: 57/18 = 3.2 >1.1// 第二个切片: 从18B开始切18B// bytesRemaining = 57-18 = 39// 第三次循环: 39/18 = 2.25 >1.1// 第三次切片: 从36B开始切18B// bytesRemaining = 39-18 = 21// 第四次循环: 21/18 = 1.16 >1.1// 第四次切片: 从54B开始切18B// bytesRemaining = 21-18 = 3String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,length-bytesRemaining, splitSize, clusterMap);splits.add(makeSplit(path, length-bytesRemaining, splitSize,splitHosts[0], splitHosts[1]));bytesRemaining -= splitSize;}//获取最后一个切片if (bytesRemaining != 0) {String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length- bytesRemaining, bytesRemaining, clusterMap);//第五个切片: 从72B开始切3Bsplits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,splitHosts[0], splitHosts[1]));}} else {String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));}} else {//Create empty hosts array for zero length filessplits.add(makeSplit(path, 0, length, new String[0]));}}sw.stop();if (LOG.isDebugEnabled()) {LOG.debug("Total # of splits generated by getSplits: " + splits.size()+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));}return splits.toArray(new FileSplit[splits.size()]);}
通过其他RDD衍生的RDD
衍生出的RDD的分区数 = 父RDD的分区
/*** 根据rdd创建的rdd的分区数默认 = 依赖的rdd的分区数*/@Testdef createRddByRddPartition(): Unit ={val rdd = sc.parallelize(List(1,4,7,2,5,9,10,20,43,55),20)val rdd2 = rdd.map(x=>x*x)println(rdd2.partitions.length)}
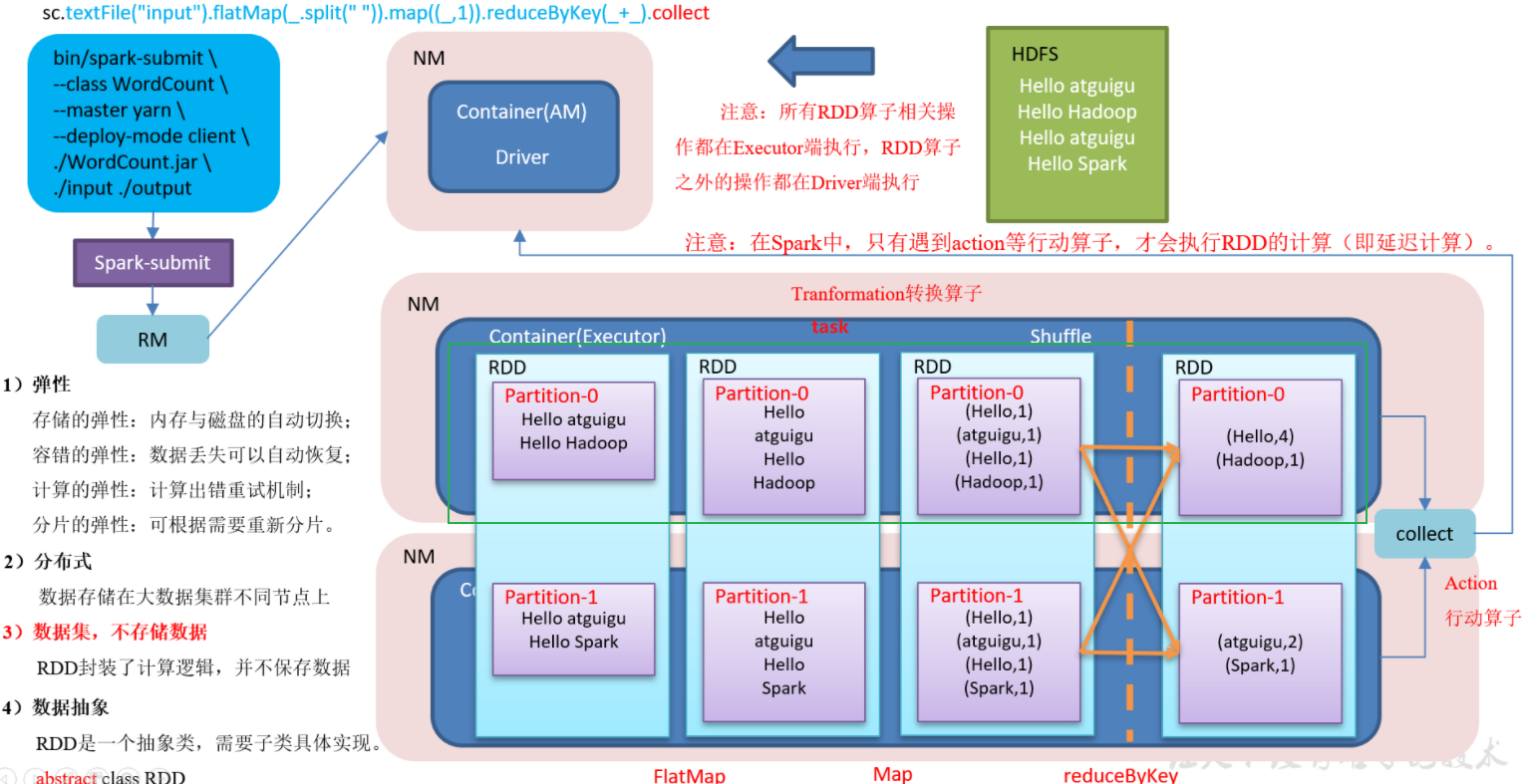
//spark中算子中的函数是在executor中执行的,算子外面的代码是在Driver中执行的
分区种类
shuffle前分区

shuffle后分区(reduce)
默认使用hashPartitioner进行分区: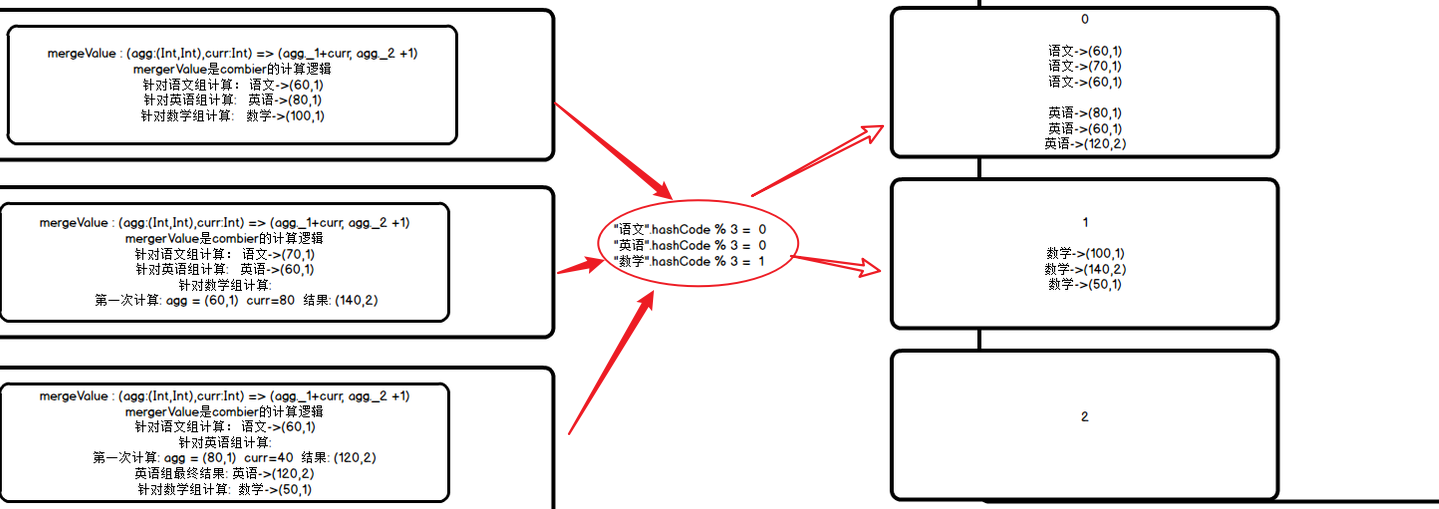

若有收获,就点个赞吧
0 人点赞
