本质:对某个数进行hash算出这个数的索引,然后 mod byte数组长度,然后存放到对应byte数组的位置,不需要存储位置本身,而是索引,相同的数这个索引值就一定相同,判断为已经存在。
判断非更高效,因为如果判断那个位没有,那么说明一定不存在
与存放实际数据相比,布隆过滤器将数据标记为比特位(1或0),这样将大大减小存储量,如64位的数据,用一个位标记则数据量降低64倍
代表数据存在,但是是概率算法。
减少失误概率的方法:
1、加大位数组长度,可以降低hash碰撞的概率
2、增多每个数的hash算法种类,将与算法结果相匹配的比特位置1,
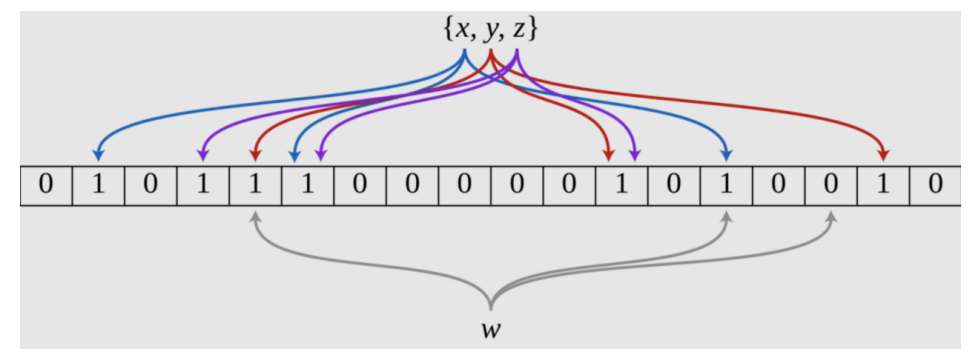
如下图,x,y,z为不同的算法,颜色代表不同的数值,经过不同的hash后,数据去到不同的位置,有可能存在一个算法值相同的情况,但是同时多个算法值组合相同的概率则大大降低

若有收获,就点个赞吧
0 人点赞
