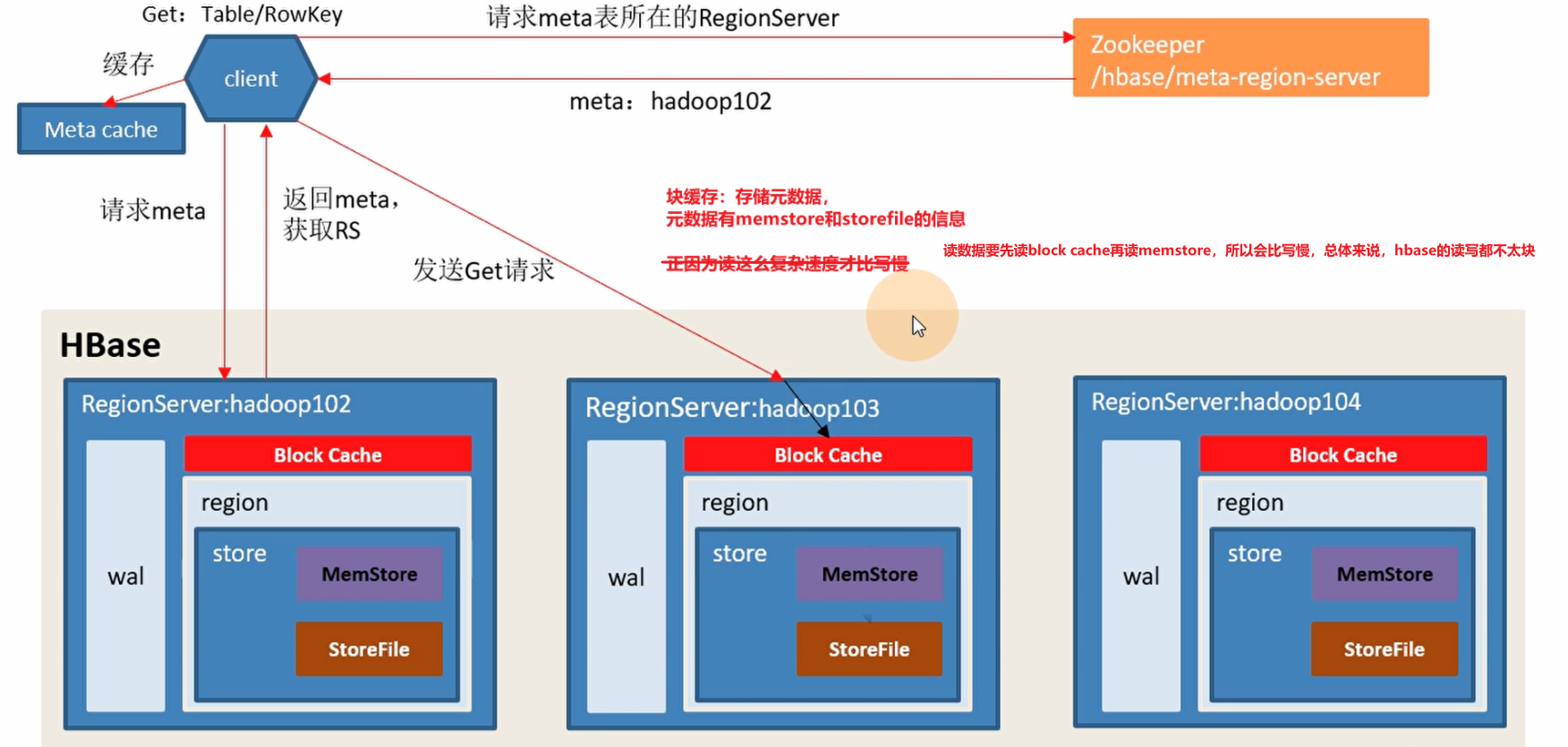
读流程
1、client向zookeeper发起获取元数据表所在regionserver的请求
2、zookeeper向client返回元数据表所在regionserver信息
3、client向元数据表所在的regionserver发起获取元数据的请求
4、regionserver返回元数据信息给client,client会缓存元数据,后续需要元数据的时候可以直接从缓存中获取
5、client通过元数据得知数据应该写入哪个region,region处于哪个regionserver,向region所在的regionserver发起数据读取请求
6、首先从读缓存(block Cache)中查询数据
7、再从memstore、storeFile中查询数据
如何快速从storeFile中查询到数据?
1、通过布隆过滤器判断数据大概处于哪些storeFile文件中
布隆过滤器特性: 如果判断存在则不一定存在,如果判断不存在则一定不存在
2、对布隆过滤器筛选的storeFile再次进行查询,通过HFile文件格式中的数据索引查询数据是否真实存在于storeFile文件中,如果存在则通过索引得到数据
8、将查询结果合并之后返回给client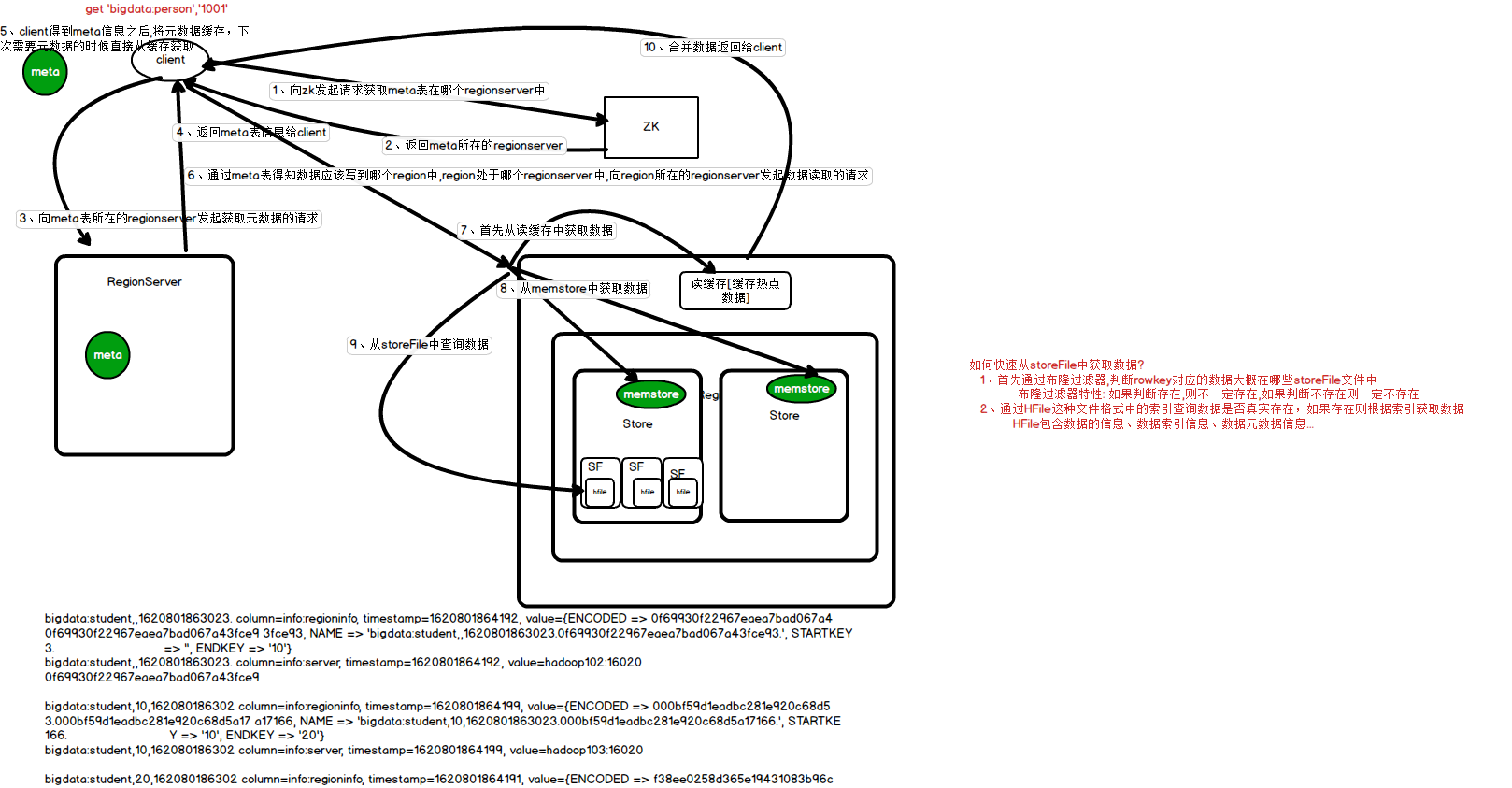
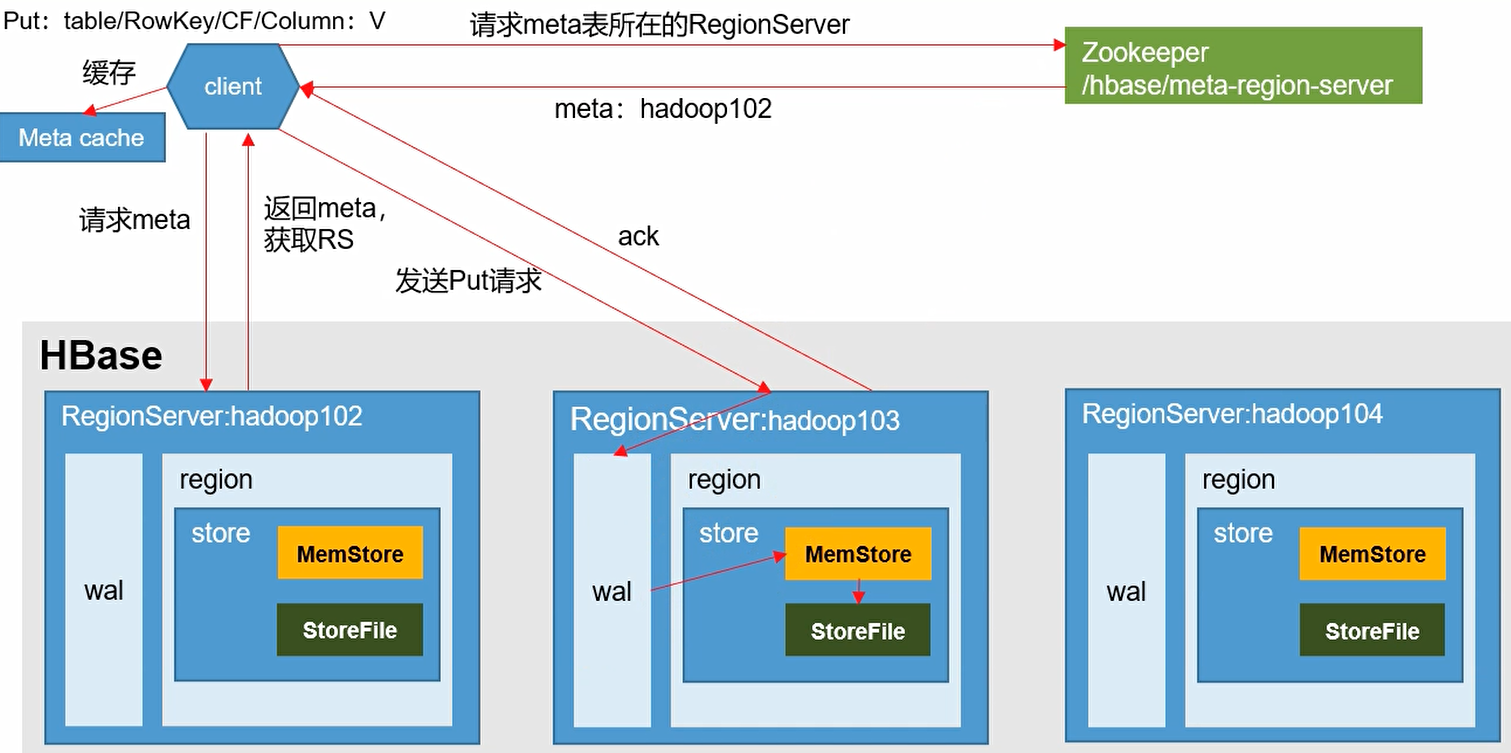
写流程
1、client向zookeeper发起获取元数据表所在regionserver的请求
2、zookeeper向client返回元数据表所在regionserver信息
3、client向元数据表所在的regionserver发起获取元数据的请求
4、regionserver返回元数据信息给client,client会缓存元数据,后续需要元数据的时候可以直接从缓存中获取
5、client通过元数据得知数据应该写入哪个region,region处于哪个regionserver,向region所在的regionserver发起数据写入请求
6、首先通过Hlog将数据以日志的形式写入HDFS
7、再讲数据写入region所在store的memstore中
8、regionserver向client返回信息告知写入完成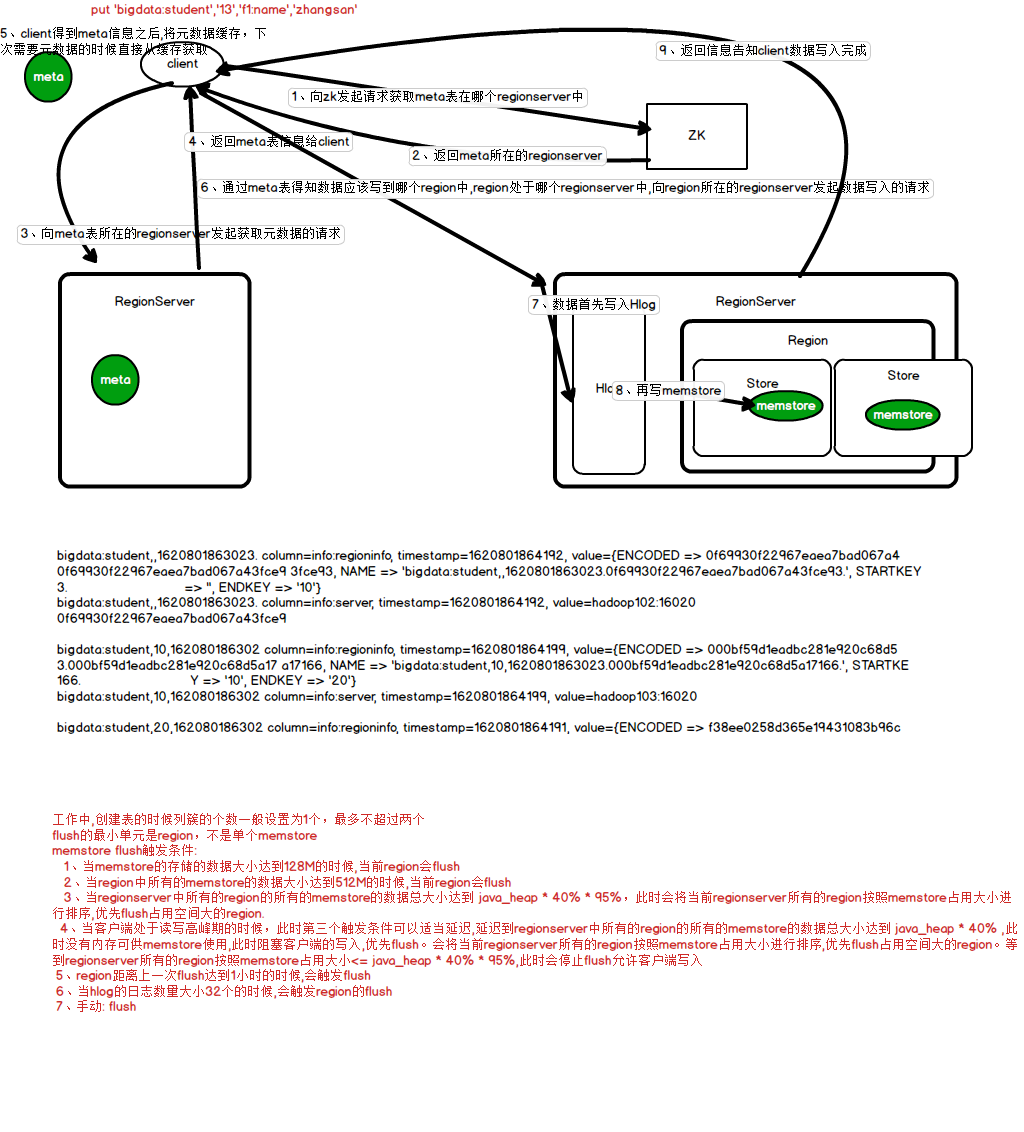
memstore flush的触发条件
实际工作中,创建表的时候列簇的个数一般为1个,最多不超过两个【原因: 避免在flush的时候产生大量的小文件】
hbase在flush的时候是flush整个region而不是当个memstore
| 1、region中某个memstore的数据量达到128M的时候,region会flush |
|---|
| 2、region中所有的memstore的总数据量达到512M的时候,region会flush |
| 3、regionserver中所有的region的所有的memstore的总数据量达到 java_heap 40% 95%,此时会触发flush,在flush之前会将regionserver中所有region按照memstore占用的空间大小进行排序,优先flush占用空间多的region |
| 4、如果处于写高峰期的时候,没有足够线程提供给flush,此时第三个触发条件可以适当延迟,等到regionserver中所有的region的所有的memstore的总数据量达到java_heap 40%,此时会阻塞client写入,优先flush。 在flush之前会regionserver中所有region按照memstore占用的空间大小进行排序,优先flush占用空间多的region,每次flush完一个region就会判断当前regionserver中所有的region的所有的memstore的总数据量<=java_heap 40% * 95%,如果满足条件则会停止flush允许client继续写入 |
| 5、region距离上一次flush如果达到1小时,此时触发region flush |
| 6、regionserver的预写日志的文件数达到32的时候,会触发region flush |
| 7、手动flush: flush ‘表名’ |

若有收获,就点个赞吧
0 人点赞
