Local模式
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。
安装使用
1)上传并解压Spark安装包
[atguigu@hadoop102 sorfware]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/[atguigu@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2 spark-local
2)官方求PI案例
[atguigu@hadoop102 spark-local]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master local[2] \./examples/jars/spark-examples_2.12-3.0.0.jar \10
可以查看spark-submit所有参数:
[atguigu@hadoop102 spark-local]$ bin/spark-submit
Ø —class:表示要执行程序的主类;
Ø —master local[2]
(1)local: 没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算
(2)local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
20/09/20 09:30:53 INFO TaskSetManager:20/09/15 10:15:00 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)20/09/15 10:15:00 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
(3)local[*]:默认模式。自动帮你按照CPU最多核来设置线程数。比如CPU有8核,Spark帮你自动设置8个线程计算。
20/09/20 09:30:53 INFO TaskSetManager:20/09/15 10:15:58 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)20/09/15 10:15:58 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)20/09/15 10:15:58 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)20/09/15 10:15:58 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)20/09/15 10:15:58 INFO Executor: Running task 3.0 in stage 0.0 (TID 3)20/09/15 10:15:58 INFO Executor: Running task 5.0 in stage 0.0 (TID 5)20/09/15 10:15:59 INFO Executor: Running task 7.0 in stage 0.0 (TID 7)20/09/15 10:15:59 INFO Executor: Running task 6.0 in stage 0.0 (TID 6)
Ø spark-examples_2.12-3.0.0.jar:要运行的程序;
Ø 10:要运行程序的输入参数(计算圆周率π的次数,计算次数越多,准确率越高);
3)结果展示
该算法是利用蒙特·卡罗算法求PI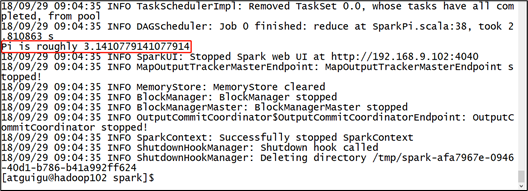
官方WordCount案例
1)需求:读取多个输入文件,统计每个单词出现的总次数。
2)需求分析: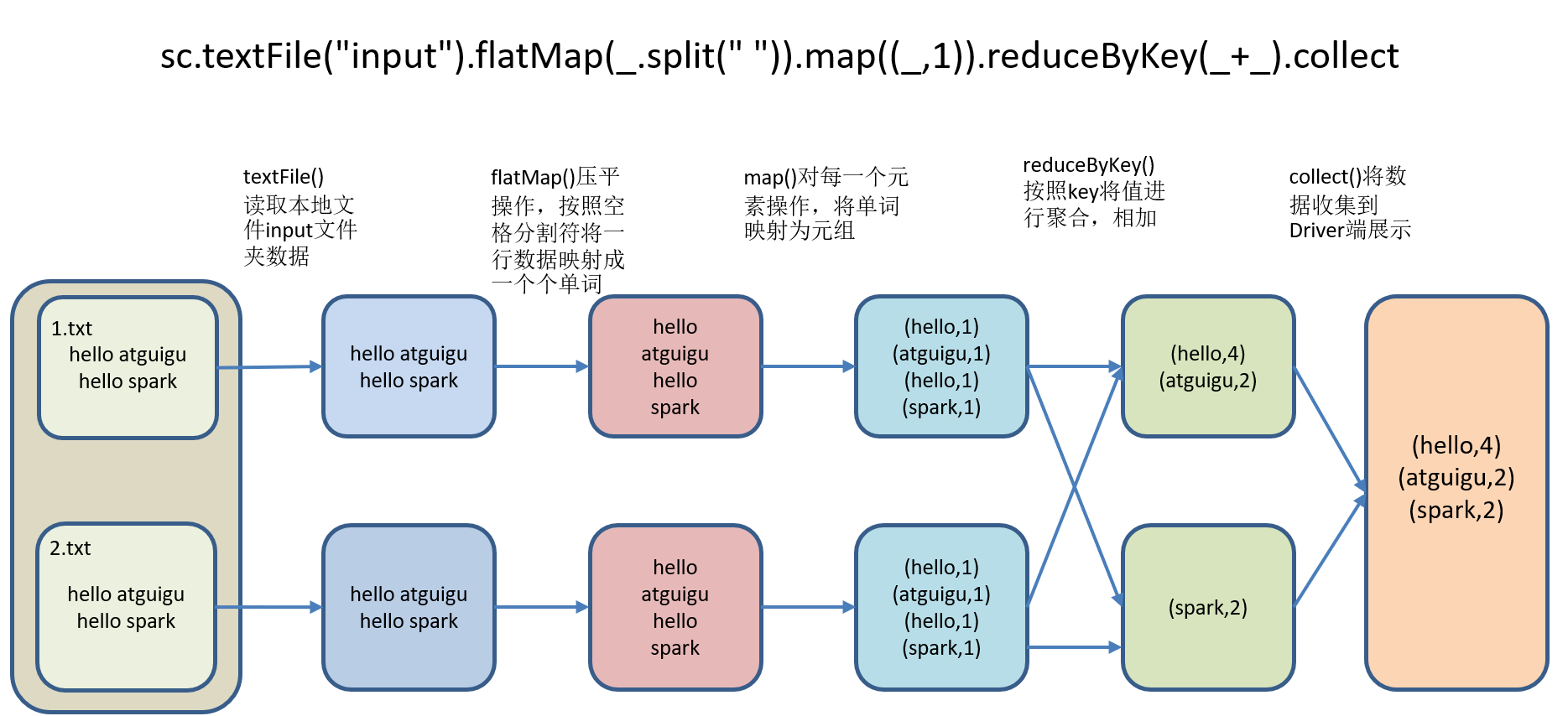
3)代码实现:
(1)准备文件
[atguigu@hadoop102 spark-local]$ mkdir input
在input下创建2个文件1.txt和2.txt,并输入以下内容
hello atguigu
hello spark
(2)启动spark-shell
[atguigu@hadoop102 spark-local]$ bin/spark-shell
20/07/02 10:17:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).Spark context Web UI available at http://hadoop102:4040Spark context available as 'sc' (master = local[*], app id = local-1593656236294).Spark session available as 'spark'.Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.0.0/_/Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)Type in expressions to have them evaluated.Type :help for more information.scala>
注意:sc是SparkCore程序的入口;spark是SparkSQL程序入口;master = local[*]表示本地模式运行。
(3)再开启一个hadoop102远程连接窗口,发现了一个SparkSubmit进程
[atguigu@hadoop102 spark-local]$ jps3627 SparkSubmit4047 Jps
运行任务方式说明:spark-submit,是将jar上传到集群,执行Spark任务;spark-shell,相当于命令行工具,本身也是一个Application。
(4)登录hadoop102:4040,查看程序运行情况(注意:spark-shell窗口关闭掉,则hadoop102:4040页面关闭)
说明:本地模式下,默认的调度器为FIFO。
(5)运行WordCount程序
scala>sc.textFile("/opt/module/spark-local/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collectres0: Array[(String, Int)] = Array((hadoop,6), (oozie,3), (spark,3), (hive,3), (atguigu,3), (hbase,6))
注意:只有collect开始执行时,才会加载数据。
可登录hadoop102:4040查看程序运行结果

若有收获,就点个赞吧
0 人点赞
