提交流程

执行脚本命令
启动CliFrontend(客户端前段) ,在其中解析参数,选择模式(FlinkYarnSessionCli),执行用户代码,生成流图
然后在YarnClusterExecutor生成作业图
之后在YarnClusterDescriptor中上传配置到HDFS,并封装提交参数和命令,提交应用提交到Yarn的RsourceMananger
之后RsourceMananger根据提交的应用,找一台NodeManger启动ApplicationMaster
ApplicationMaster(JobManager)在内部启动Dispatcher和YanrRsourceMananger(和Yarn的RsourceMananger不是同一个东西)
Dispatcher启动JobMaster,JobMaster内部有SlotPool,
JobMaster向YanrRsourceMananger的SlotManger申请slot
SlotManger检查是否有足够的slot,如果没有,向RsourceMananger申请
RsourceMananger根据申请,找一台nodemananger启动一个容器来启动YarnTaskExecutorRunner
YarnTaskExecutorRunner通过runTaskManager方法启动TaskManager,在TaskManager内部启动TaskExecutor
TaskExecutor内部生成所需的slot,然后向SlotManger注册slot,
之后SlotManger告知TaskExecutor如何分配slot,
TaskExecutor根据规则向JobMaster的SlotPool提供slot
然后根据JobMaster的DefualtScheduler生成执行图,并传递给TaskExecutor去执行任务
任务提交流程
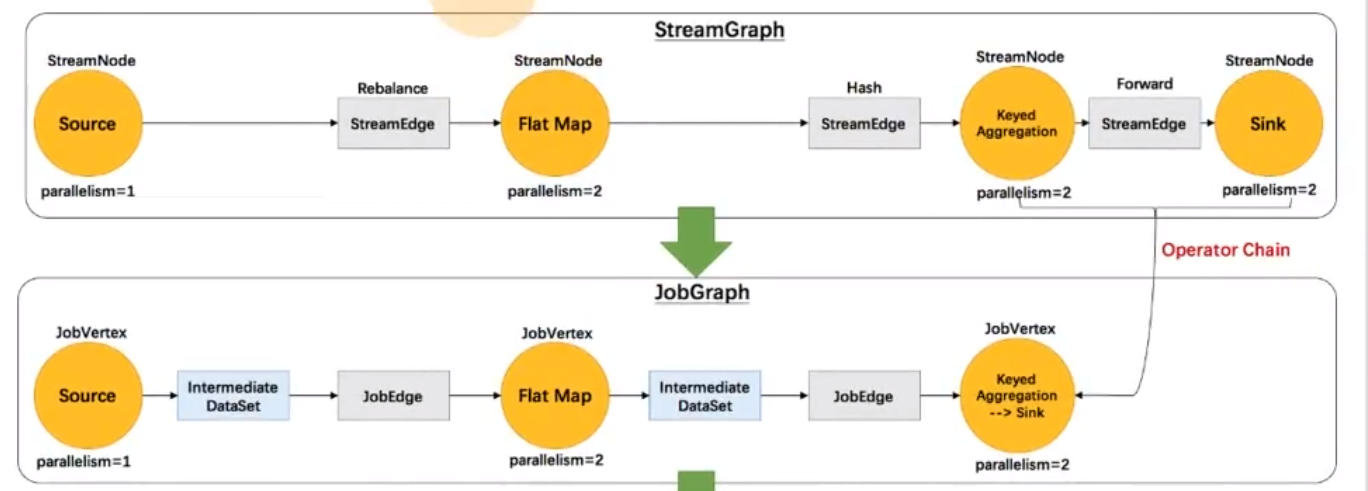
在Clifrontend将我们自己写的算子,挨个添加到流图结构中
其中,将不是对数据做转换的算子转换为流边(StreamEdge) ,而转换算子则为流节点(StreamNode)
在客户端将流图转换为作业图
其中,会将流图中可以优化成操作链的算子都链接起来
其次,将流节点StreamNode转换成作业顶点jobVertex,将流边转换为作业图的边jobedge,同时生成某个顶点的中间数据集(IntermediateDataSet)
之后将:边,顶点,数据集,遍历串联起来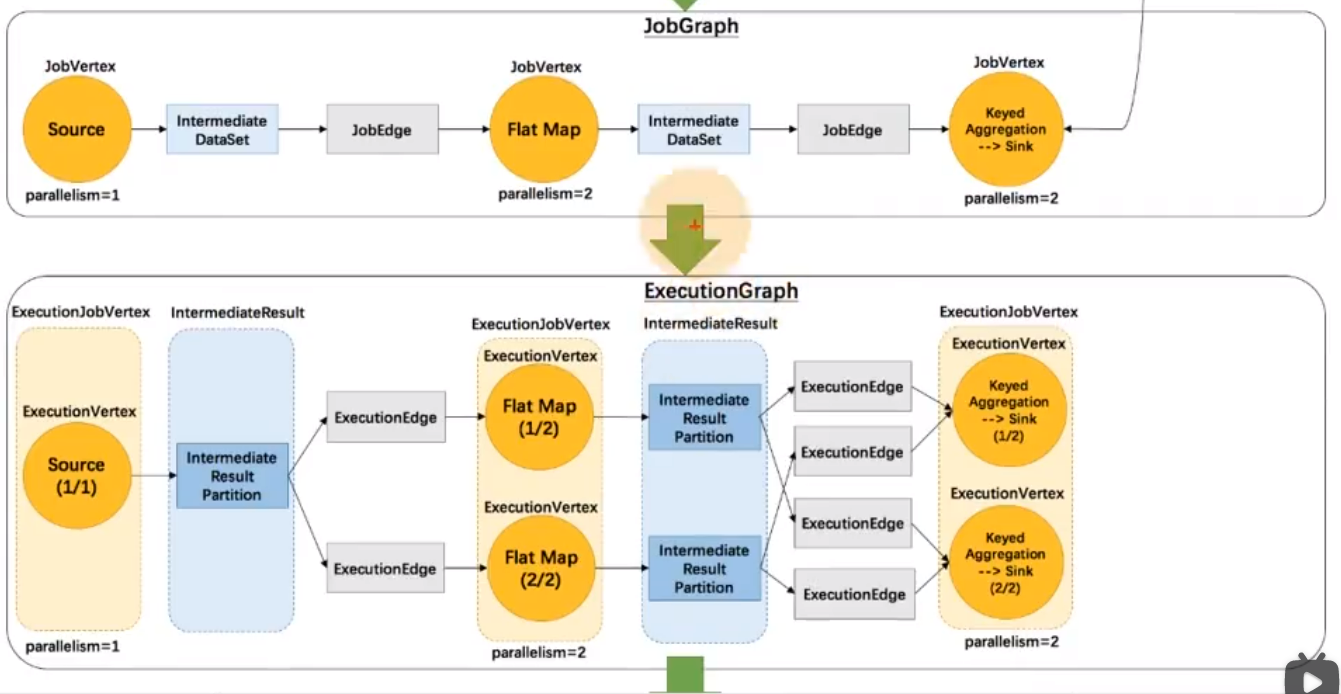
在JonManager 中的DefaultScheduler 中将作业图转化为执行图
将作业图顶点,转换为执行作业顶点,然后将执行作业顶点展开为不同并行度的 执行顶点
然后中间数据集转换为中间结果,然后每个中间结果也会有中间结果分区
和spark不同的是flink的算子是从头到尾的,而spark则相反
执行器有了执行图就开始调度
通过RPC通信后台来远程调度任务
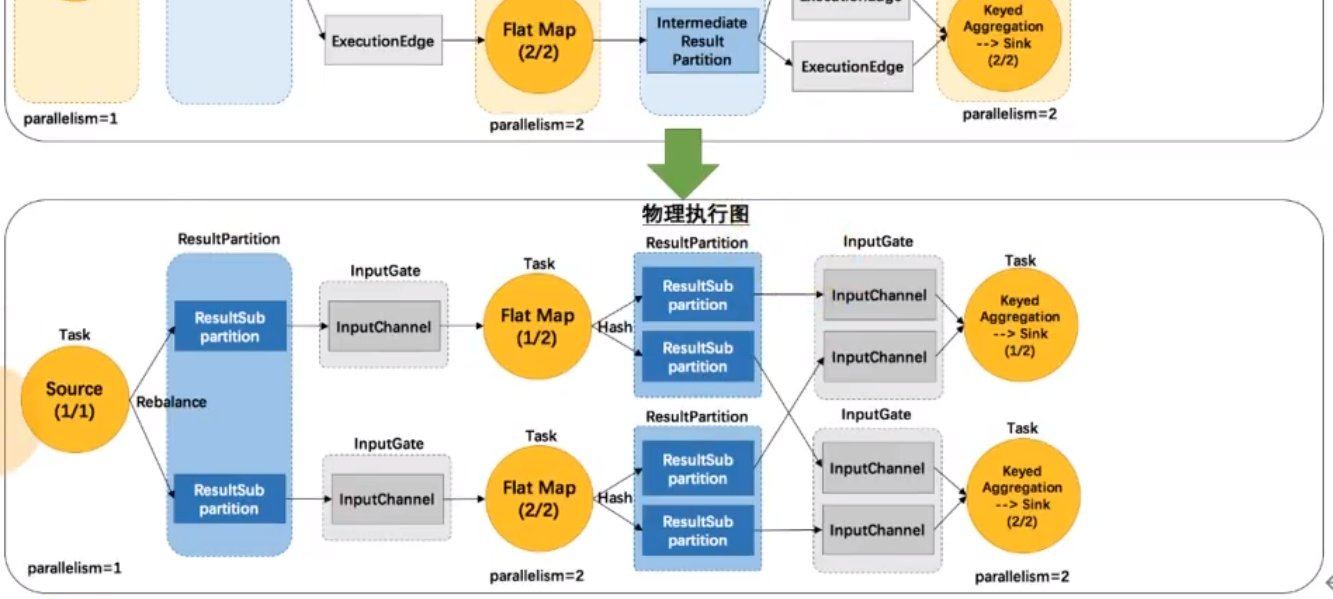
物力执行图是上帝视角,不属于代码
Actor System是RPC终端,通信终端
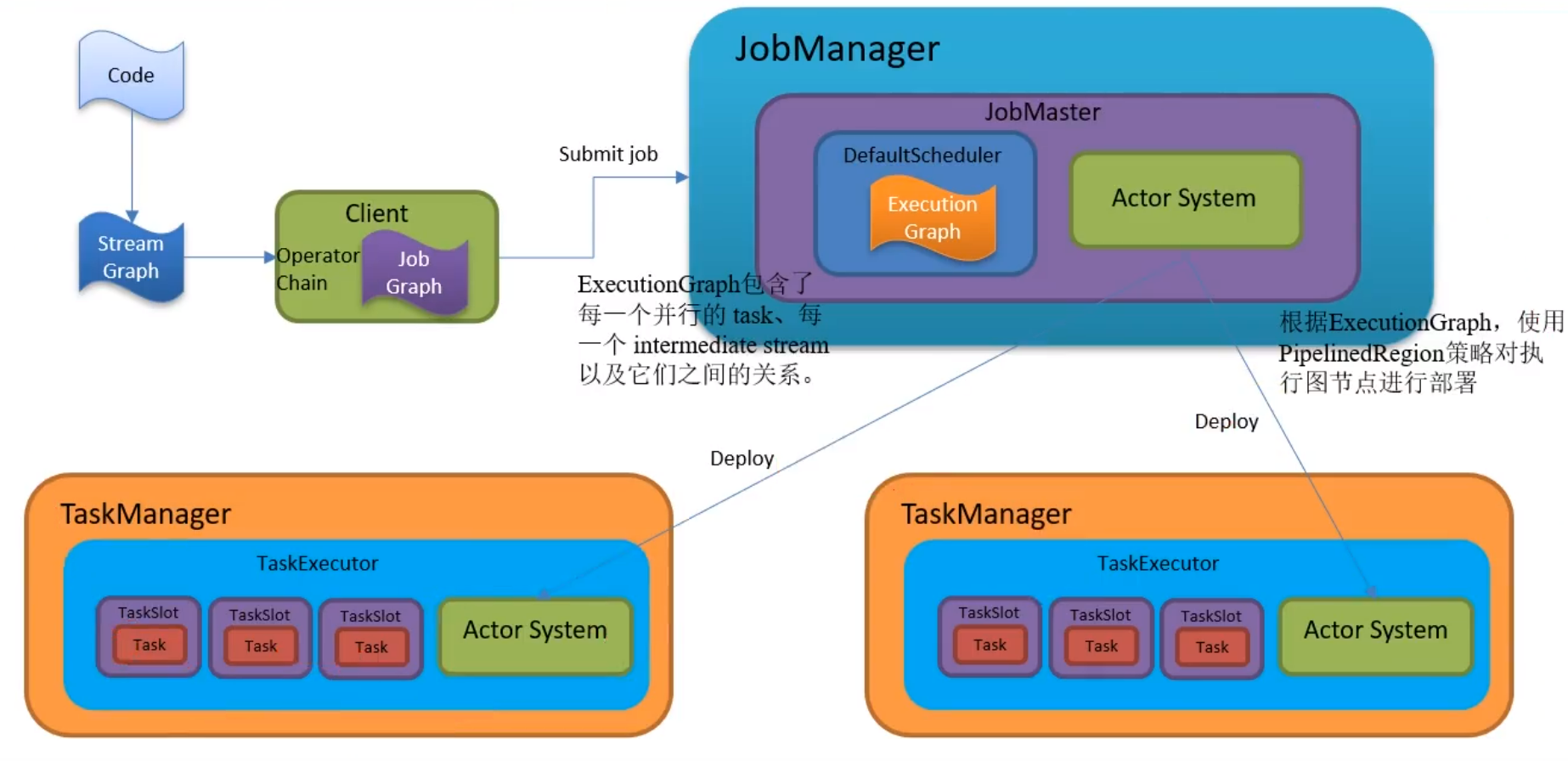
执行用户main方法,生成流图,在客户端内部经过操作链优化生成作业图
之后客户端提交作业到HDFS,ApplicationMaster下载后就相当于,客户端submit到ApplicationMaster(其他模式都是直接submit)
之后DefaultScheduler拿到作业图,开始生成执行图,
然后根据执行图使用PipelinedRegion策略对执行图节点进行部署,通过RPC通信后台远程调度,部署消息给TaskManager然后执行任务
内存管理机制
JVM内存管理的不足
1、java对象存储密度低,会有填充字节

2、FullGC 阻塞进程

3、OOM影响性能
4、缓存未命中
cpu计算是通过缓存获取数据的,而jvm在堆上的存储不是连续的,导致cpu缓存也不是连续的,所以会出现未命中cache miss的情况,效率会很慢
JobManager内存管理
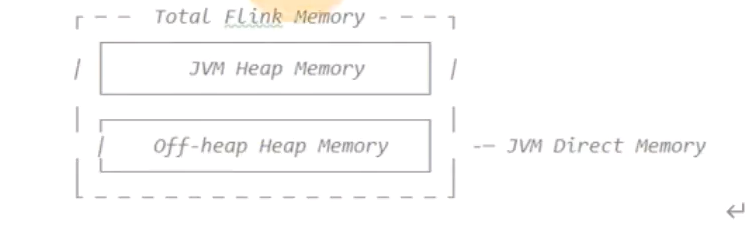
分为堆内内存和堆外内存
其中jvm本身运行就需要内存,其次是其他开销使用的内存
TaskManager内存管理

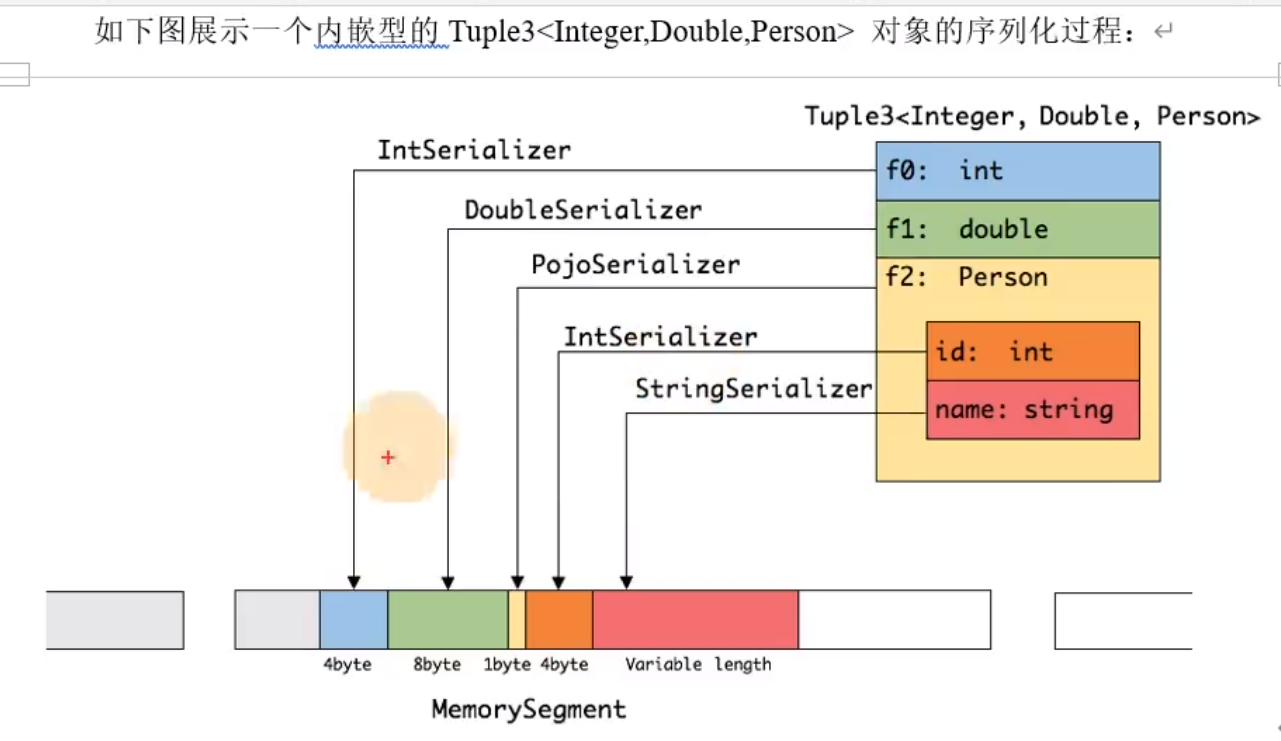
内存段MemorySegment
与jvm内存不同,他很紧凑,很紧密
内存页,有很多内存段
为了方便管理内存段,
Buffler 网络缓冲内存
实现类NetWorkBuffler,一个Buffler对应一个内存段MemorySegment
BufflerPool 资源池
类似于连接池,管理Buffler的申请释放销毁
实现类是LocalBufflerPool
每个Task会有一个自己的LocalBufflerPool
内存管理器
1.10版本前,管理的是TaskManager的内存
1.10后版本,管理slot内存
网络传输中的内存管理
输入
输入门IG(InputGate)向LocalBufflerPool申请内存段,LocalBufflerPool向NetworkBufflerPool申请内存段
NetworkBufflerPool返回给LocalBufflerPool再返回给IG
之后IG传递给Task算子,然后再传递给ResultPartition,
输出
RS(ResultPartition)再将数据输出到LocalBufflerPool,再输出到NetworkBufflerPool
之后再被其他Task算子调用,来实现跨节点,跨网络的数据传输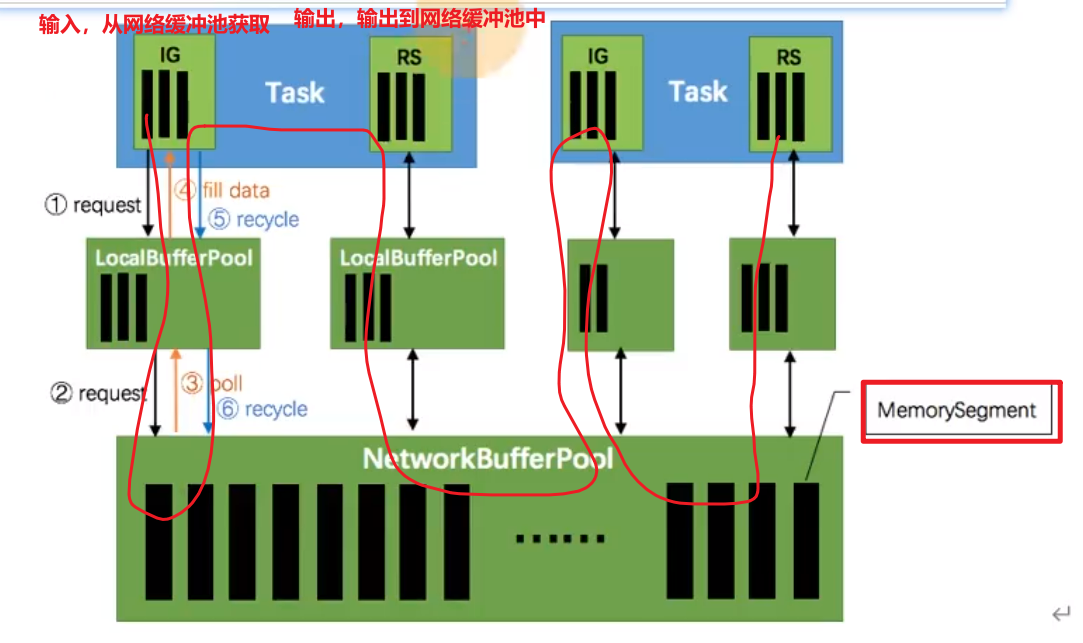
反压基于信用机制(credit)
spark的反压是手动开启的
flink的则是内部自己优化好
场景:
数据从一个Task到另一个Task,如果产生反压
塞满了证明信用度低,信用度低就不会向前发送数据,就会造成反压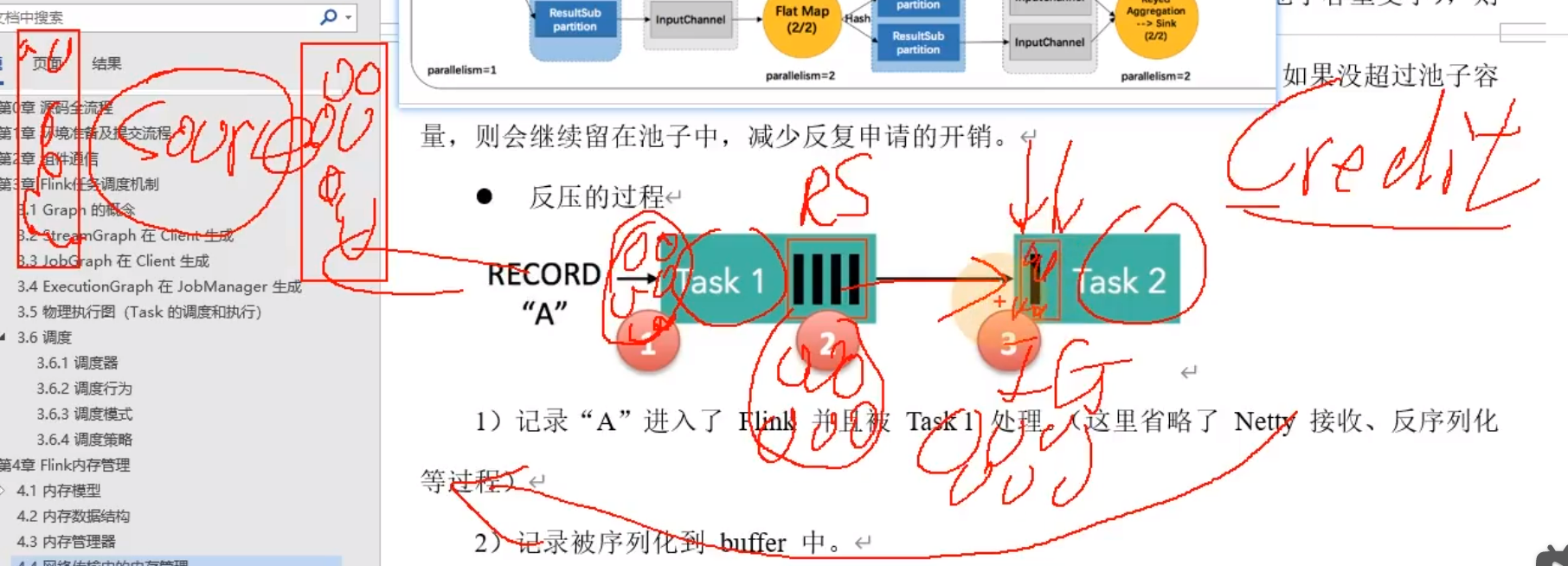

若有收获,就点个赞吧
0 人点赞
