提交job的指令参数
-m 指定提交的jobmanager
-c 指令运行的全类名、jar包
-d 提交完立即退出客户端
部署
yarn
session-Cluster模式
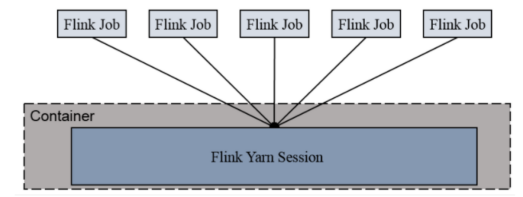
特性:
只有一个yarn集群,
一直开启,直到手动停止
多个job争抢资源
main函数在客户端
适用:
任务执行时间少,频繁提交的小job
适合离线操作
指令
先启动会话
bin/yarn-session.sh -d
执行:
不需要添加-m,自动找到启动的节点
bin/flink run -c <全类名> <要执行的jar包所在路径>
per-job-cluster
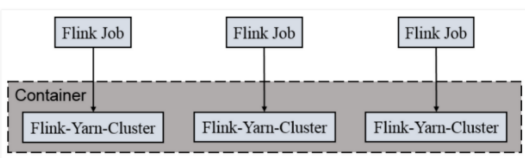
特性:
一个job启动一个yarn集群,
job完成后关闭集群
job之间不会争抢资源
main函数在客户端
适用:
适合规模大,长时间运行的job
指令
bin/flink run -d -t yarn-per-job -c <全类名> <要执行的jar包所在路径>
Application mode
特性:
和per-job-cluster一样
main函数在yarn的nodemanager(appmastar)上,也就是在集群上
区别:
用户的main函数是在集群中(job manager)执行的
指令
bin/flink run-application -t yarn-application -c <全类名> <要执行的jar包所在路径>
高可用
flink 高可用,
无论是否让leader提交,还是给worker提交,都一样,因为worker会转发给leader
standalone:
启动多个jobmanager,zk选举
配置:
1. 在yarn-site.xml中配置
<property><name>yarn.resourcemanager.am.max-attempts</name><value>4</value><description>The maximum number of application master execution attempts.</description></property>
注意: 配置完不要忘记分发, 和重启yarn
2. 在flink-conf.yaml中配置
yarn.application-attempts: 3high-availability: zookeeperhigh-availability.storageDir: hdfs://hadoop162:8020/flink/yarn/hahigh-availability.zookeeper.quorum: hadoop162:2181,hadoop163:2181,hadoop164:2181high-availability.zookeeper.path.root: /flink-yarn

若有收获,就点个赞吧
0 人点赞
