全局二级索引
详细原理请看视频
Global Index是默认的索引格式,创建全局索引时,会在HBase中建立一张新表。也就是说索引数据和数据表是存放在不同的表中的,因此全局索引适用于多读少写的业务场景。
写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
读数据的时候Phoenix会选择索引表来降低查询消耗的时间。
总结:本质上就是另外一张表
1)创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);
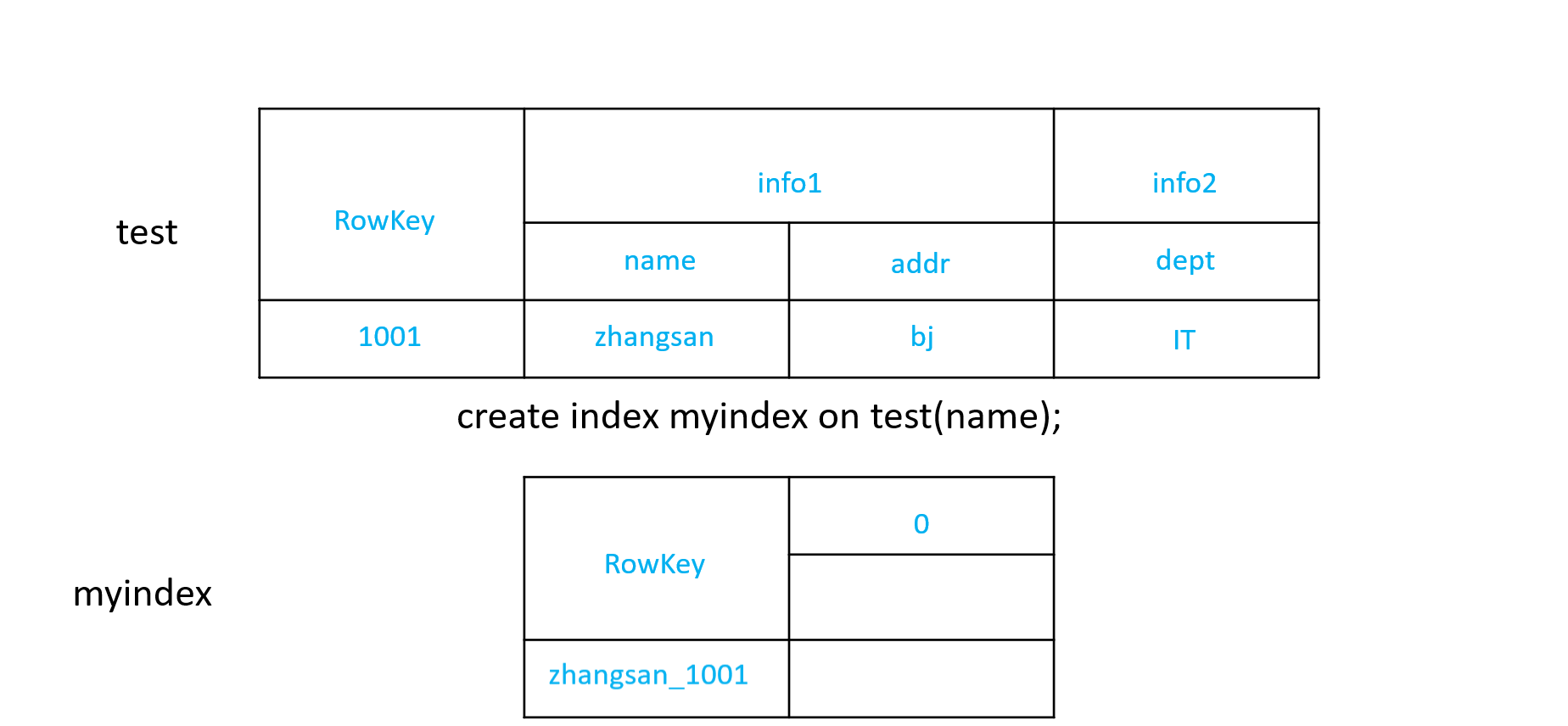
如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。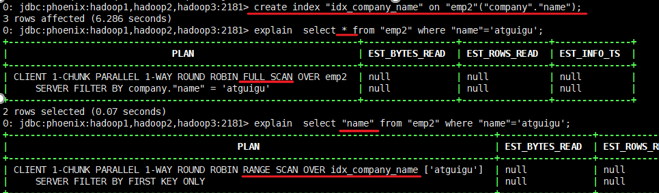
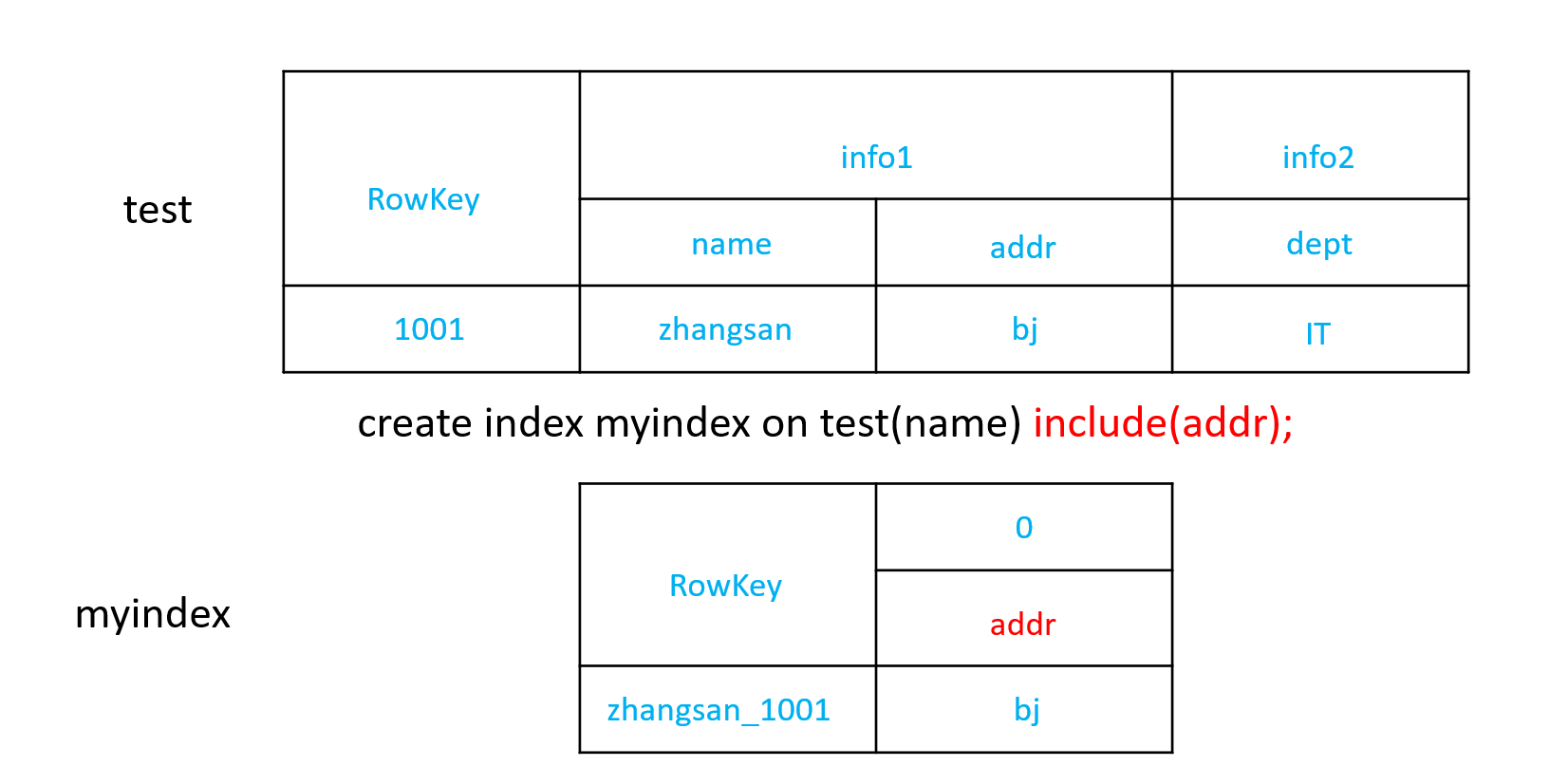
2)创建组合索引
include带的字段作为新表的列簇
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);
本地二级索引
1、Local Index适用于写操作频繁的场景。
索引数据和数据表的数据是存放在同一张表中(且是同一个Region),避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。
2、查询速度的提升:查询的字段不是索引字段索引表也会被使用
原理:
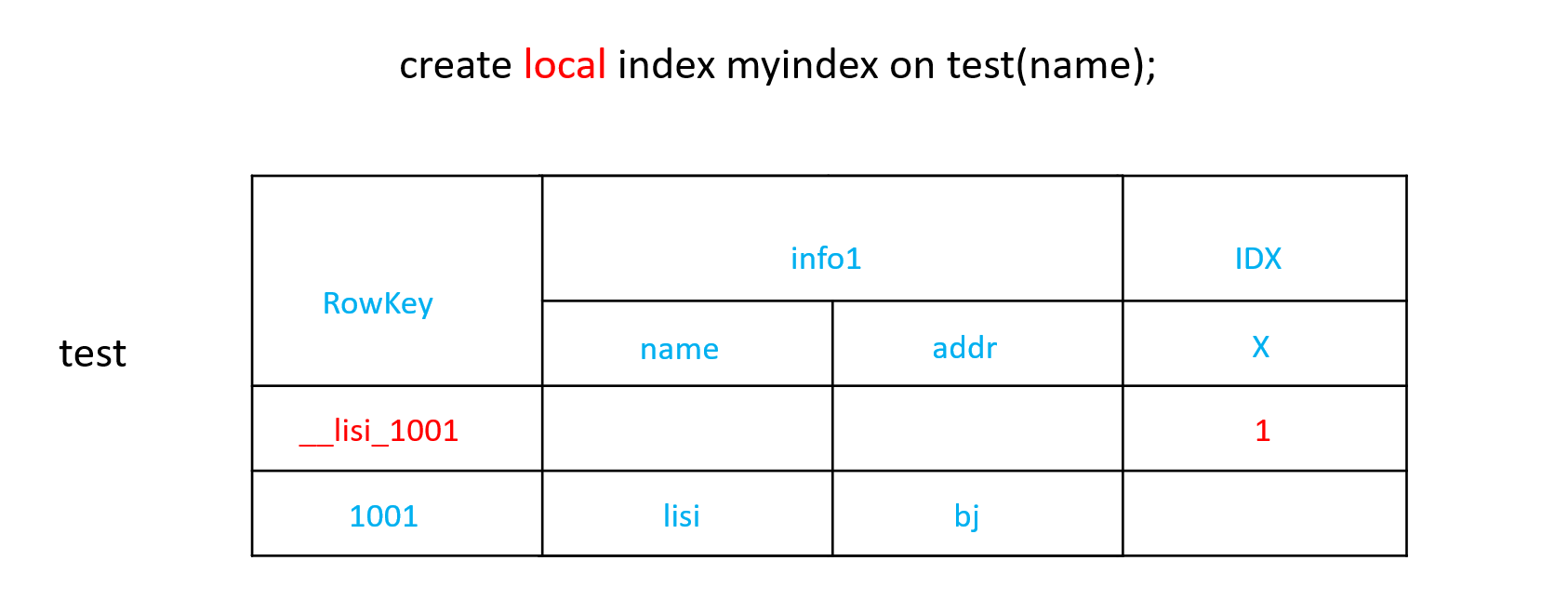
索引插在同一张表中。
在逻辑表上位于第一个region中(因为索引含有下划线,如:__name_age_key)
查询的时候,索引所在region,找到对应字段的key再到其他region中寻找对应数据,这样索引就被应用了两层
CREATE LOCAL INDEX my_index ON my_table (my_column);
二级索引配置文件
添加如下配置到HBase的HRegionserver节点的hbase-site.xml
<!-- phoenix regionserver 配置参数--><property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value></property><property><name>hbase.region.server.rpc.scheduler.factory.class</name><value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property><property><name>hbase.rpc.controllerfactory.class</name><value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property>
HBase协处理器(扩展)
案例需求
编写协处理器,实现在往A表插入数据的同时让HBase自身(协处理器)向B表中插入一条数据。
实现步骤
1)创建一个maven项目,并引入以下依赖。
/
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.0.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.0.5</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2)定义FruitTableCoprocessor类并继承BaseRegionObserver类
package com.atguigu;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import java.io.IOException;
public class FruitTableCoprocessor implements RegionObserver, RegionCoprocessor {
@Override
public Optional<RegionObserver> getRegionObserver() {
return Optional.of(this);
}
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
//获取连接
Connection connection = ConnectionFactory.createConnection(HBaseConfiguration.create());
//获取表对象
Table table = connection.getTable(TableName.valueOf("fruit"));
//插入数据
table.put(put);
//关闭资源
table.close();
connection.close();
}
}
3)打包放入HBase的lib目录下
4)分发jar包并重启HBase
5)建表时指定注册协处理器
在4.1.2节基础上添加如下语句
tableDescriptorBuilder.setCoprocessor("com.atguigu.FruitTableCoprocessor");
注意: 还可以通过不重启的方式动态加载协处理器
1) 给hbase-site.xml中添加配置,防止协处理器异常导致集群停机
<property>
<name>hbase.coprocessor.abortonerror</name>
<value>false</value>
</property>
2) 打成jar包上传hdfs,比如存放路径为 hdfs://hadoop102:9820/c1.jar
3) 禁用表: disable ‘A’
4) 加载协处理器:
alter ‘表名’, METHOD => ‘table_att’, ‘Coprocessor’=>’jar所处HDFS路径| 协处理器所在的全类名|优先级|参数’
5) 启动表: enable ‘A’
6) 向A表插入数据,观察B表是否同步有数据插入

若有收获,就点个赞吧
0 人点赞
