针对键值操作
5种数据类型
string list set hash zset
服务端启动
将配置文件,保留一份副本,进行启动。
命令: redis-server conf
但是这样的话,发现命令窗口被占用了,很不方便。当然你可以再启动一个会话窗口。
解决:修改配置文件,改为守护进程,在后台运行
我们选择后台运行,怎么办?修改配置文件。
daemonize yes
后台启动后,查看服务: netstat –anp|grep 6379
客户端登录
| 命令 | 说明 | 举例 | 备注 |
|---|---|---|---|
| redis-cli | 启动客户端 | redis-cli -h 主机名 –p 端口号 redis-cli -p 端口号,默认本机、 redis-cli —raw 显示原始状态的数据,例如有中文,或者结果出现了转义字符,使用这个指令即可 |
直接执行的话,默认端口号就是6379; |
| ping | 测试联通 | 回复pong代表联通 | |
| exit | 退出客户端 | ||
| shutdown | 停止服务器 | redis-cli -h 127.0.0.1 -p 6379 shutdown 停止指定ip指定端口号的服务器 |
redis是通过客户端发送停止服务器的命令 |
help
connect
@Sever
| select |
切换数据库,默认有16个,0-15 |
|---|---|
| flushdb | 清空当前库 |
| dbsize | 查看数据库数据个数 |
| flushall | 通杀全部库,并做快照 |
| auth | 服务端如果配置密码,客户端第一次发起对应请求的时候,需要通过auth设置密码登录 |
flushall 与 flushdb 的区别
1.flushall 清空数据库并执行持久化操作,也就是rdb文件会发生改变,变成76个字节大小(初始状态下为76字节),所以执行flushall之后数据库真正意义上清空了.
2.flushdb 清空数据库,但是不执行持久化操作,也就是说rdb文件不发生改变.而redis的数据是从rdb快照文件中读取加载到内存的,所以在flushdb之后,如果想恢复数据库,则可以直接kill掉redis-server进程,然后重新启动服务,这样redis重新读取rdb文件,数据恢复到flushdb操作之前的状态.
注意:要直接kill 掉redis-server服务,因为shutdown操作会触发持久化.
、
key操作
@generic
| move | 将一个key的数据移动到另一个库 | move k1 0 移动k1键到0号库 |
|---|---|---|
| KEYS pattern | 查询符合指定表达式的所有key,支持,?等 ?号代表任意一个,代表任意多个 |
|
| TYPE key | 查看key对应值的类型 | map的键只能是string,但value可以是其他如list |
| EXISTS key | 指定的key是否存在,0代表不存在,1代表存在 | |
| DEL key… | 删除指定key,可以多个 | |
| RANDOMKEY | 在现有的KEY中随机返回一个 | |
| EXPIRE key seconds | 为键值设置过期时间,单位是秒,过期后key会被redis移除 | |
| PERSIST key | 移除key的过期时间 | |
| TTL key | 查看key还有多少秒过期,-1表示永不过期,-2表示已过期 | |
| RENAME key newkey | 重命名一个key,NEWKEY不管是否是已经存在的都会执行,如果NEWKEY已经存在则会被覆盖 | |
| RENAMENX key newkey | 只有在NEWKEY不存在时能够执行成功,否则失败 0代表失败,1代表成功 |
|
| NX结尾:代表不存在则成功执行 |
String操作
String类型是Redis中最基本的类型,它是key对应的一个单一值。
二进制安全,不必担心由于编码等问题导致二进制数据变化。所以redis的string可以包含任何数据,比如jpg图片或者序列化的对象。
Redis中一个字符串值的最大容量是512M。
| SET key value | 添加键值对 |
|---|---|
| GET key | 查询指定key的值 |
| APPEND key value | 将给定的value追加到原值的末尾 |
| STRLEN key | 获取值的长度 |
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
| INCR key | 指定key的值自增1,只对数字有效 |
| DECR key | 指定key的值自减1,只对数字有效 |
| INCRBY key num | 自增num |
| DECRBY key num | 自减num |
| MSET key1 value1 key2 value2… | 同时设置多个key-value对 |
| MGET key1 key2 | 同时获取一个或多个value |
| MSETNX key1 value1 key2 value2 | 当key不存在时,设置多个key-value对 |
| GETRANGE key起始索引 结束索引 | 获取指定范围的值,都是闭区间 |
| SETRANGE key起始索引 value | 从起始位置开始覆写指定的值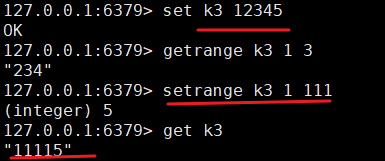 |
| GETSET key value | 以新换旧,同时获取旧值 |
| SETEX key 过期时间 value | 设置键值的同时,设置过期时间,单位秒 |
list操作
在Java中list 一般是单向链表,如常见的Arraylist,只能从一侧插入。
在Redis中,list是双向链表。可以从两侧插入。
list 角标范围:[0,-1]
可以简单理解为两端开口的,两端都可以进出。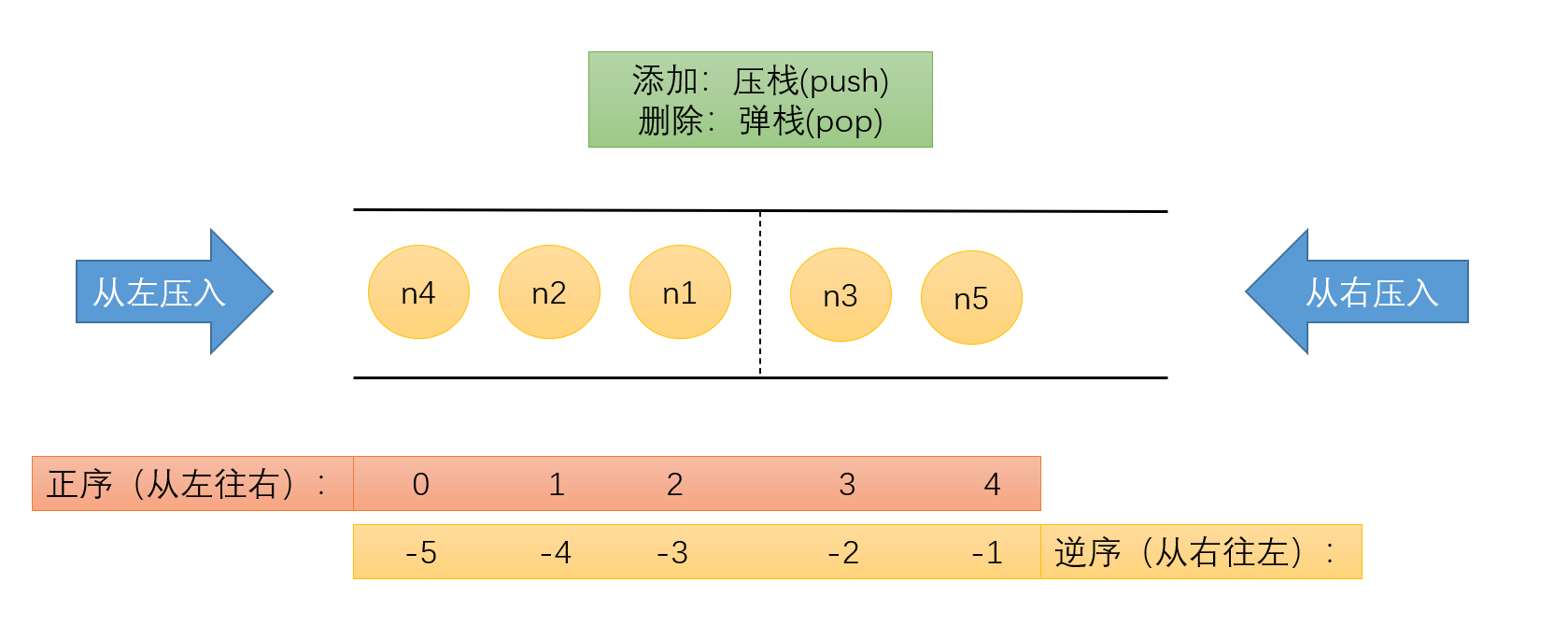
常见操作:
遍历:遍历的时候,是从左往右取值;
删除:弹栈,POP;
添加:压栈,PUSH ;
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
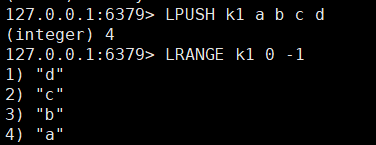
| LPUSH/RPUSH key value1 value2… | 从左边/右边压入一个或多个值 rpush比较顺眼 头尾效率高,中间效率低 |
lpush a b c d result:d c b a rpush a b c d result:a b c d |
|---|---|---|
| LPOP/RPOP key | 从左边/右边弹出一个值 值在键在,值光键亡 弹出=返回+删除 |
|
| LRANGE key start stop | 查看指定区间的元素 正着数:0,1,2,3,… 倒着数:-1,-2,-3,… |
 |
| LINDEX key index | 按照索引下标获取元素(从左到右) | |
| LLEN key | 获取列表长度 | |
| LINSERT key BEFORE|AFTER value newvalue | 在指定value的前后插入newvalue | |
| LREM key n value | 从左边删除n个value的值 | 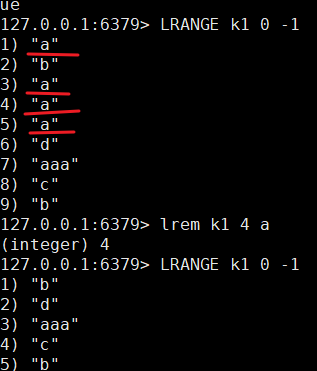 |
| LSET key index value | 把指定索引位置的元素替换为另一个值 | |
| LTRIM key start stop | 仅保留指定区间的数据 | |
| RPOPLPUSH list1 list2 | 从list1右边弹出一个值,左侧压入到list2 | 如果list2不存在则创建List2 |
set操作
set是无序的,且是不可重复的。
| SADD key member [member …] | 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。 |
|---|---|
| SMEMBERS key | 取出该集合的所有值 |
| SISMEMBER key value | 判断集合 |
| SCARD key | 返回集合中元素的数量 |
| SREM key member [member …] | 从集合中删除元素 |
| SPOP key [count] | 从集合中随机弹出count个数量的元素,count不指定就弹出1个 |
| SRANDMEMBER key [count] | 从集合中随机返回count个数量的元素,count不指定就返回1个 |
| SINTER key [key …] | 将指定的集合进行“交集”操作 |
| SINTERSTORE dest key [key …] | 取交集,另存为一个set,如果key存在值,则对原有值进行覆盖操作 |
| SUNION key [key …] | 将指定的集合执行“并集”操作 |
| SUNIONSTORE dest key [key …] | 取并集,另存为set |
| SDIFF key [key …] | 将指定的集合执行“差集”操作,取出A集合中不包含B集合的不分 |
| SDIFFSTORE dest key [key …] | 取差集,另存为set |
zset操作
zset是一种特殊的set(sorted set),在保存value的时候,为每个value多保存了一个score信息。根据score信息,可以进行排序。
结合了list(有序)和set(不重复)的特点。
可以用[ 0,-1 ]表示所有防范
这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了
| ZADD key [score member …] | 添加 |
|---|---|
| ZSCORE key member | 返回指定值的分数 |
| ZRANGE key start stop [WITHSCORES] | 返回指定区间的值,可选择是否一起返回scores |
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] | 在分数的指定区间内返回数据,从小到大排列 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] | 在分数的指定区间内返回数据,从大到小排列 |
| ZCARD key | 返回集合中所有的元素的数量 |
| ZCOUNT key min max | 统计分数区间内的元素个数 |
| ZREM key member | 删除该集合下,指定值的元素 |
| ZRANK key member | 返回该值在集合中的排名,从0开始 |
| ZINCRBY key increment member | 为元素的score加上增量 |
hash操作
相当于嵌套map
Hash数据类型的键值对中的值是“单列”的,不支持进一步的层次结构。
| key | field:value |
|---|---|
| “k01”:”v01” “k02”:”v02” “k03”:”v03” “k04”:”v04” “k05”:”v05” “k06”:”v06” “k07”:”v07” |
从前到后的数据对应关系
n JSON
stu:{"stu_id":10,"stu_name":"tom","stu_age":30}
n Java
public class Student {private Integer stuId;//10private String stuName;//"tom"private Integer stuAge;//30...}Student stu=new Student()’stu.setStuId=10;stu.setStuName=”tom”;stu.setStuAge=30;
n Redis hash
| key | value(hash) | |
|---|---|---|
| stu | stu_id | 10 |
| stu_name | tom | |
| stu_age | 30 |
常用操作:
| HSET key field value | 为key中的field赋值value(kv键值对) | |
|---|---|---|
| HMSET key field value [field value …] | 为指定key批量设置field-value(kv键值对) | |
| HSETNX key field value | 当指定key的field不存在时,设置其value | |
| HGETALL key | 获取指定key的所有信息(field和value):kv | 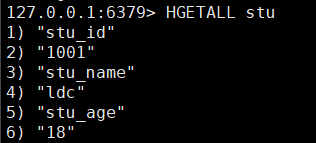 |
| HKEYS key | 获取指定key的所有field:k | |
| HVALS key | 获取指定key的所有value:v | |
| HLEN key | 指定key的field个数 | |
| HGET key field | 从key中根据field取出value | |
| HMGET key field [field …] | 为指定key获取多个filed的值 | |
| HEXISTS key field | 指定key是否有field | |
| HINCRBY key field increment | 为指定key的field加上增量increment |

若有收获,就点个赞吧
0 人点赞
