概述
如果用户需要同时流计算、批处理的场景下,用户需要维护两套业务代码,开发人员也要维护两套技术栈,非常不方便。
Flink 社区很早就设想过将批数据看作一个有界流数据,将批处理看作流计算的一个特例,从而实现流批统一, Flink 社区的开发人员在多轮讨论后,基本敲定了Flink 未来的技术架构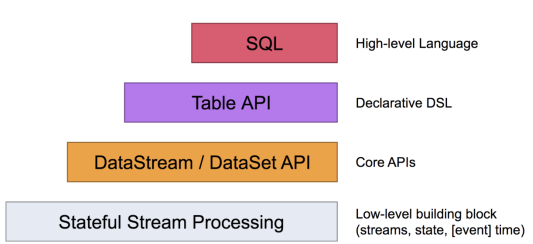
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。
Table API 是用于 Scala 和 Java 语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。
Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。这两种 API 中的查询对于批(DataSet)和流(DataStream)的输入有相同的语义,也会产生同样的计算结果。
Table API 和 SQL 两种 API 是紧密集成的,以及 DataStream 和 DataSet API。你可以在这些 API 之间,以及一些基于这些 API 的库之间轻松的切换。比如,你可以先用 CEP 从 DataStream 中做模式匹配,然后用 Table API 来分析匹配的结果;或者你可以用 SQL 来扫描、过滤、聚合一个批式的表,然后再跑一个 Gelly 图算法 来处理已经预处理好的数据。
注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。
动态表(Dynamic Tables)
连续查询(Continuous Query)。
1. 将流转换为动态表。
2. 在动态表上计算一个连续查询,生成一个新的动态表。
3. 生成的动态表被转换回流。
连接方式总结:
tableAPI+sqlAPI都有:
从流中获取表
从数据源中(connector)获取表
表到流的转换
总结:**(I,U,D)->(insert , upsert ,delete)**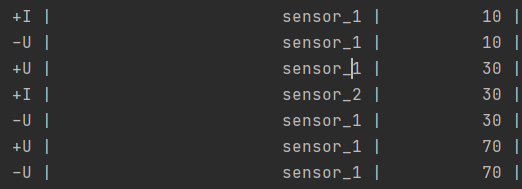
TableAPI 手动调用方法
SQLAPI 自动实现
动态表可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。它可能是一个只有一行、不断更新的表,也可能是一个 insert-only 的表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
Append-only 追加流
调用:**tenv.toAppendStream**_**(**_**t1, Row.class**_**)**_**;**
使用条件:只有insert操作使用,加入你使用了分组,本来流中来了1条sensor_1,1 ,后面再来一条sensor_1,1,此时再分组sum聚合后,数据更新了,则不能使用这种模式
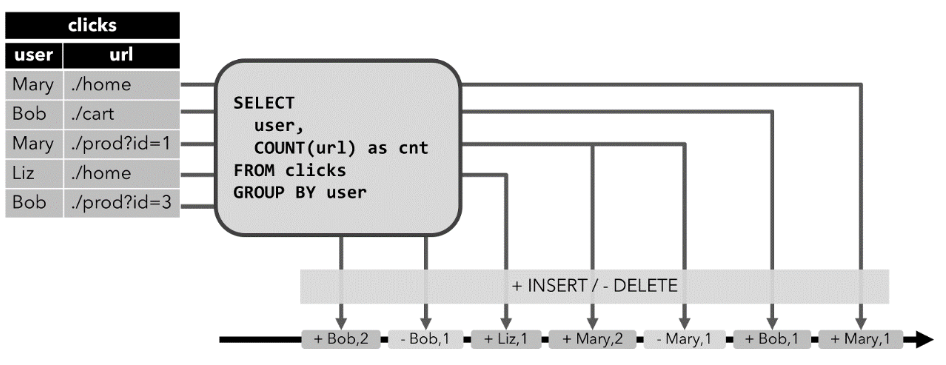
Retract 流,撤回流
调用:**tenv.toRetractStream**_**(**_**t1,Row.class**_**)**_
使用条件:包含insert、delete、update的操作,一般产生这些操作的算子是聚合操作算子
原理:
retract 流包含2种类型的 message:
add message+ retract message
将INSERT 操作编码为 add message、
将 DELETE 操作编码为 retract message、
将 UPDATE 操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,
效果:因为有了先把原先重复数据删除再添加的操作,会让数据不出现重复的效果
Upsert 流
参考:https://www.yuque.com/cheng-rtxtv/kb/nzg4yf#LrZvN
调用:**在将动态表转换为 DataStream 时,只支持 append 流和 retract 流**
upsert 流包含两种类型的 message:
upsert messages 和delete messages。
转换为 upsert 流的动态表需要(可能是组合的)唯一键。
将 INSERT 和 UPDATE 操作编码为 upsert message,
将 DELETE 操作编码为 delete message ,
将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。
与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。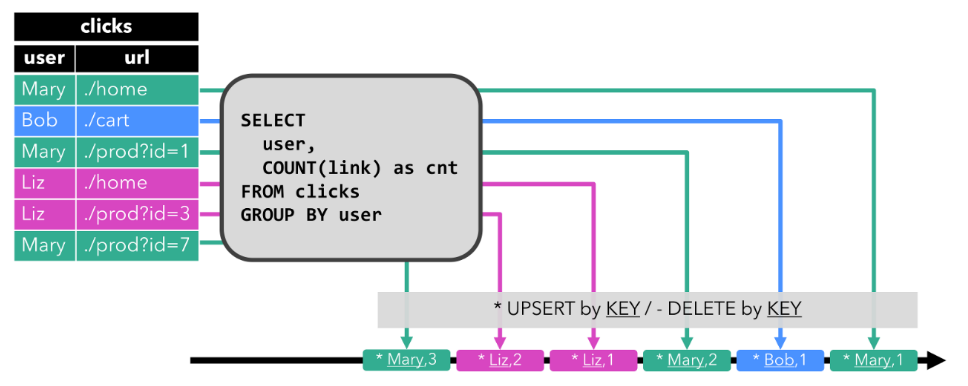
效果:
数据会重复,最后的数据才是全局的数据
以上属于流操作

若有收获,就点个赞吧
0 人点赞
