Spark概述
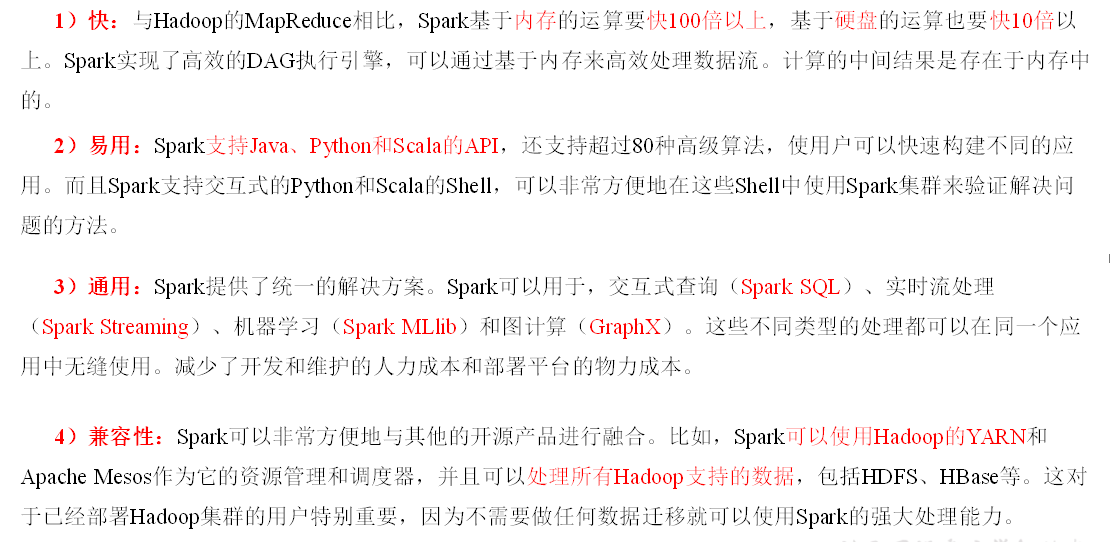
什么是Spark
回顾:Hadoop主要解决,海量数据的存储和海量数据的分析计算。
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark安装地址
1)官网地址:http://spark.apache.org/
2)文档查看地址:https://spark.apache.org/docs/3.0.0/
3)下载地址:https://spark.apache.org/downloads.html
https://archive.apache.org/dist/spark/
MR与Spark框架对比
executor相当于container
Driver相当于ApplicationMaster 都是负责任务调度的
executor相当于 Task+container,
他的资源只给自己用,所以不需要创建container(类似于有些充电器插头一定要与线连接在一起,有些擦头可以与线分离)
container可以给maptask用,也可以给reducetask用。
Mr运行一次落盘2次,spark遇到shuffler才落盘
mr的task的进程级别,spark的task是线程级别,进程的创建和销毁代价比较线程而言更大
mr只适合一次计算,spark适合迭代计算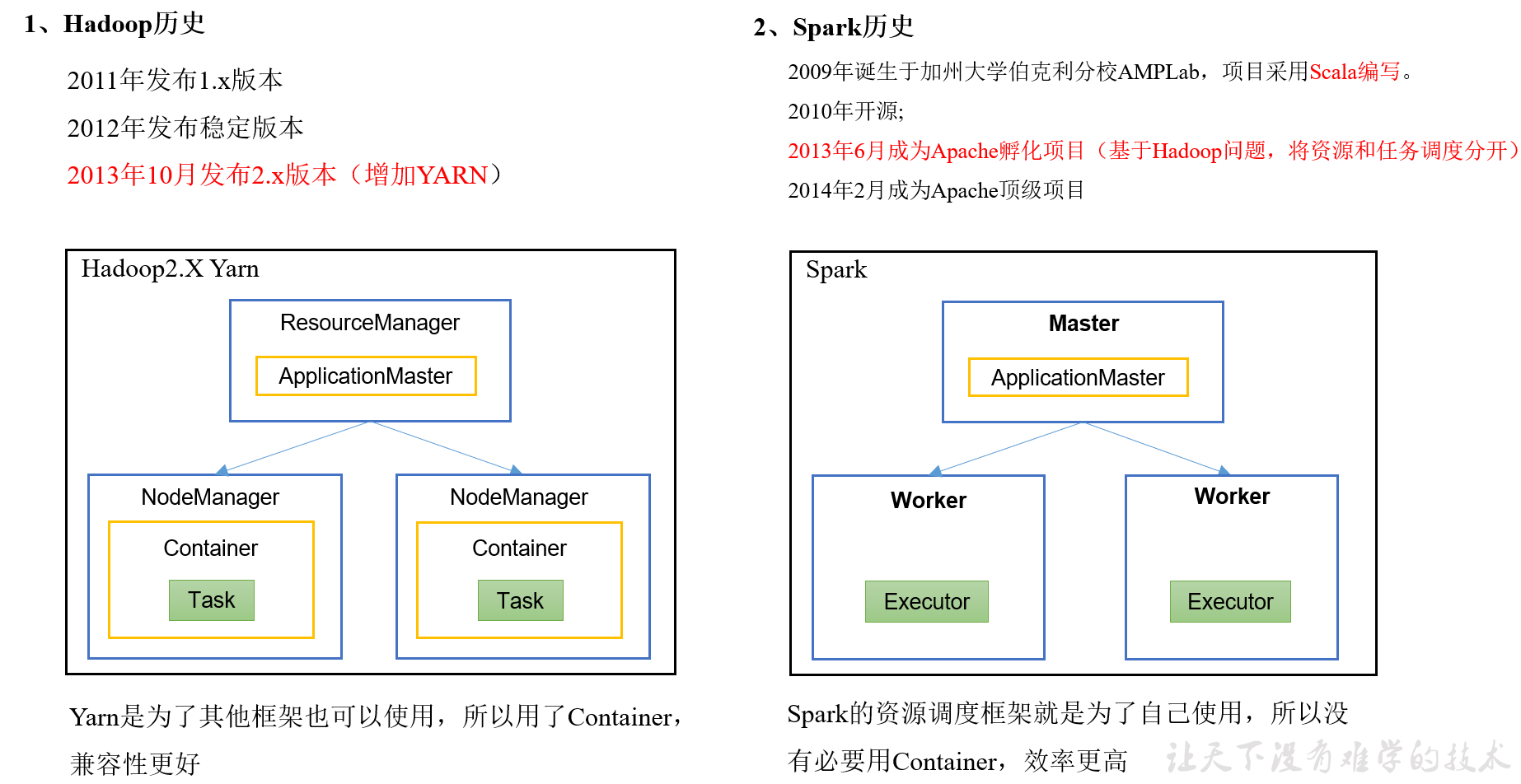
Spark内置模块
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD,弹性分布式数据集)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
Spark特点
几种模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 |
|---|---|---|---|
| Local | 1 | 无 | Spark |
| Standalone | 3 | Master及Worker | Spark |
| Yarn | 1 | Yarn及HDFS | Hadoop |
端口号总结
1)Spark查看当前Spark-shell运行任务情况端口号:4040
2)Spark Master内部通信服务端口号:7077 (类比于Hadoop的8020(9000)端口)
3)Spark Standalone模式Master Web端口号:8080(类比于Hadoop YARN任务运行情况查看端口号:8088)
4)Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888)
指令:
bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master local[2] \./examples/jars/spark-examples_2.12-3.0.0.jar \10

若有收获,就点个赞吧
0 人点赞
