FileInputFormat中切片:
进入summit()方法去到:
jobsummiter类中:
进入:input.getSplits(job)方法去到:
FileInputFormat类中
**
整个切片流程都在getSplits(job)方法中完成。
1)切片原则:按照文件单独切片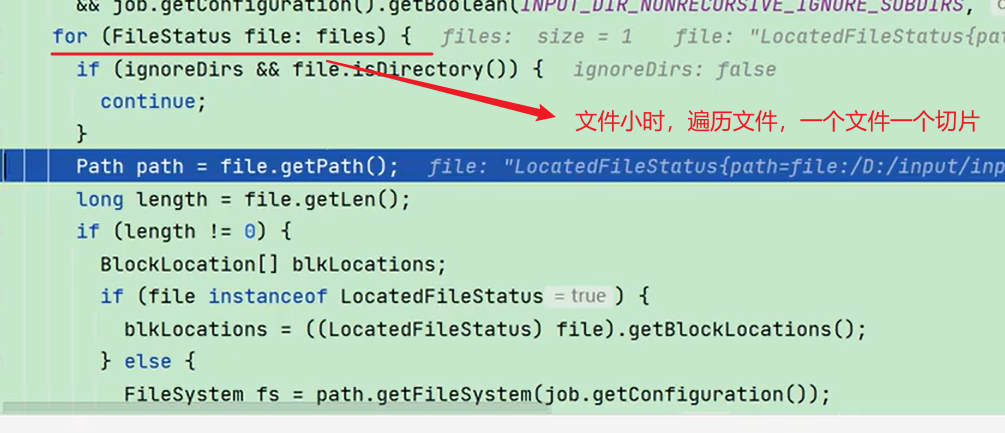
2)切片调整:通过调整minsize和maxsize来调整切片大小,块大小是不可更改的:
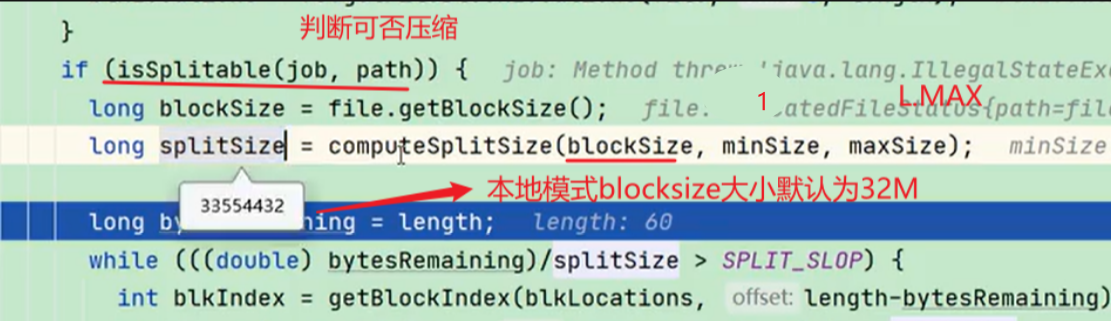
computesplitsize方法:
调整:
minsize比blocksize大则调大切片
maxsize比blocksize小则调小切片
切片参数: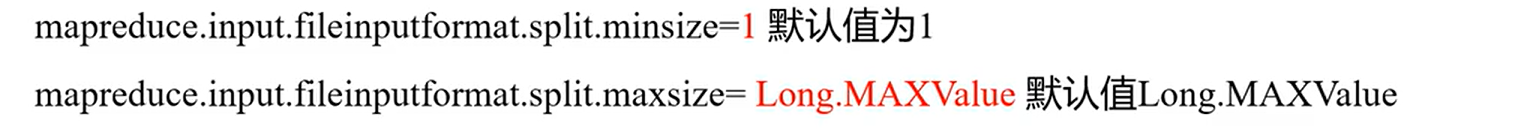
3)文件大小是切片大小的1.1倍就切割。
4)切好后写入临时路径,作为切片规划文档
5)InputFormat只记录了切片的元数据信息,比如起始位置、长度以及节点列表等,只是逻辑上的计算
真正切片交给MRAppMaster,根据切片规划文件计算开启mapTask个数
所以:
切片的目的就是规划maptask个数即:切片数=maptask数
*获取切片api
CombineInputFormat中切片
点击查看【bilibili】
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1)应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job,4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。
(1)虚拟存储过程:
文件按文件名字典排序,之后根据大小进行存储。
(2)切片过程:
将存储好的切片进行合并
CombineTextInputFormat案例实操
1)需求
将输入的大量小文件合并成一个切片统一处理。
(1)输入数据
准备4个小文件
(2)期望
期望一个切片处理4个文件
2)实现过程
(1)不做任何处理,运行1.6节的WordCount案例程序,观察切片个数为4。
(2)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为3。
(a)驱动类中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.classjob.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置4mCombineTextInputFormat.setMaxInputSplitSize(job,4194304);
(b)运行如果为3个切片。
(3)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为1。
(a)驱动中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.classjob.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置20mCombineTextInputFormat.setMaxInputSplitSize(job,20971520);
(b)运行如果为1个切片。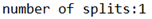

若有收获,就点个赞吧
0 人点赞
