

Checkpoints
- 不能自动提交offset,需要自己维护offset!
如何自己维护?
三种方式:
①Checkpoints
②Kafka itself
③Your own data store
Checkpoints: checkpoint本质是一个持久化的文件系统!
将kafka的偏移量存储在 spark提供的ck目录中,下次程序重启时,会从ck目录获取上次消费的offset,继续消费!
RDD.cache()
RDD.checkpoint——>ReliableRDDCheckpointData
This allows drivers to be restarted on failure with previously computed state.
app允许报错了,但是你设置了ck目录,在异常时,程序会将一部分状态(想保存的数据,例如消费者消费的offset)保存到一个ck目录中,之后
app重启后,driver从ck目录中读取状态,恢复!
操作: ①设置ck目录
streamingContext.checkpoint(“kafkack”)
②设置故障的时候,让Driver从ck目录恢复
def getActiveOrCreate(
checkpointPath: String, //ck目录
creatingFunc: () => StreamingContext // 一个空参的函数,要求返回StreamingContext,函数要求把计算逻辑也放入次函数
): StreamingContext
③取消自动提交offset
“enable.auto.commit” -> “false”
要不要设置发生故障时哪些数据保存到ck目录?
不用设置,也设置不了,spark自动实现!
使用checkpoint 输入端必须是精准一次吗?
输入端精准一次?
Checkpoints的弊端:
①一般的异常,会catch住,继续运行,不给你异常后,从异常位置继续往后消费的机会
②重启后,会从上次ck目录记录的时间戳(每5秒产生的小文件),一直按照 slide时间,提交Job,到启动的时间
③会产生大量的小文件
不推荐使用!
at least once : 不能保证精确一次!
例如:abcdefg 中,abcde 为一个批次,而运行到d的时候报错,那么正确的那部分(abc)已经写到数据库了,宕机后恢复数据则会重复再次执行abcde,此时abc数据就会重复
object KafkaDirectCKTest {val ckPath:String ="kafkack"def main(args: Array[String]): Unit = {def creatingStreamingContextFunc() : StreamingContext={val streamingContext = new StreamingContext("local[2]", "wc", Seconds(5))//设置ck目录streamingContext.checkpoint(ckPath)// 消费者的配置val kafkaParams = Map[String, Object]("bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "0223","auto.offset.reset" -> "latest","enable.auto.commit" -> "false" //!!!!!!!!!!!!取消自动提交)//指定要消费主题val topics = Array("topic2")// 使用提供的API,从kafka中获取一个DSval ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))//程序的运算逻辑val ds1: DStream[String] = ds.map(record => {//模拟异常//if (record.value().equals("d")) throw new UnknownError("故障了!求你婷下来吧!")record.value()})ds1.print()streamingContext}// 要么直接创建,要么从ck目录中恢复一个StreamingContextval context: StreamingContext = StreamingContext.getActiveOrCreate(ckPath, creatingStreamingContextFunc)context.start()context.awaitTermination()}}
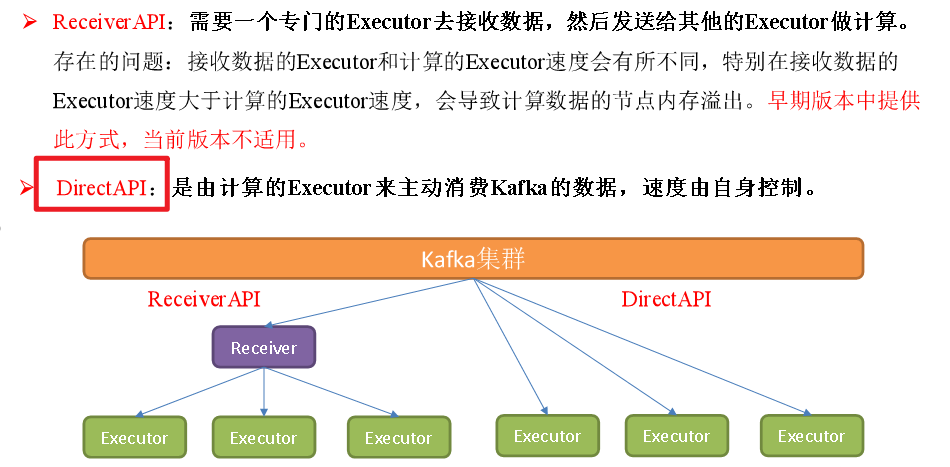
Kafka itself
- 借助kafka提供的api,手动将offset存储到kafka的__consumer_offsets中
核心:
①取消自动提交offset
②获取当前消费到的这批数据的offset信息
③进行计算和输出
④计算和输出完全完成后,再手动提交offset
发生异常时提交offset会不会产生重复?
* 发生了异常,是提交不了offset的!
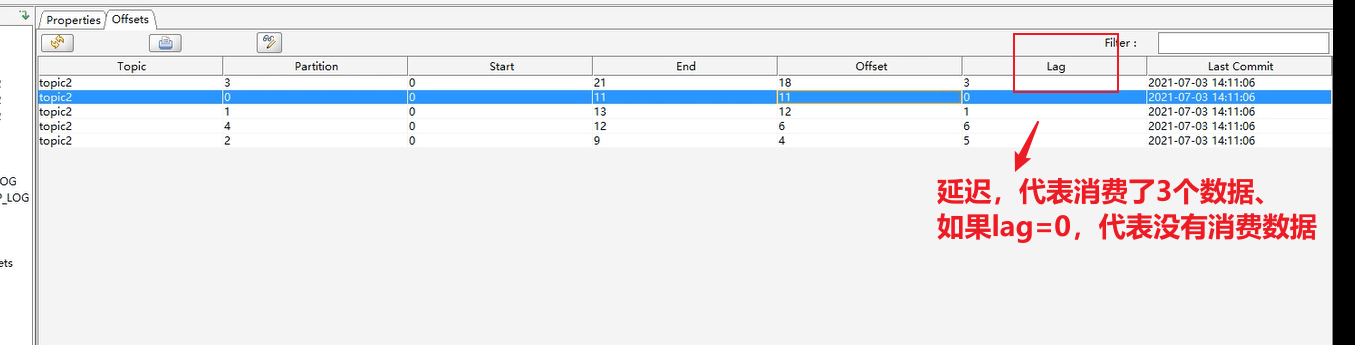
下图是消费数据的结果和offset
例如0号partition,从end到offset之间有6条数据没有被提交,
当offset提交后19就会变成25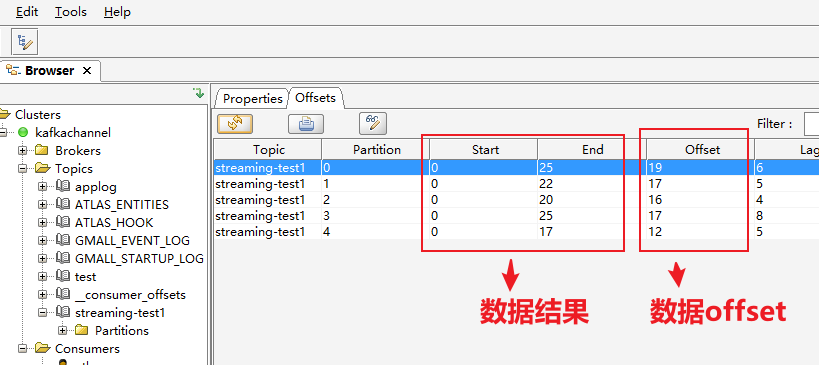
package kafkatestimport org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.SparkContextimport org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribeimport org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, KafkaUtils, LocationStrategies}import org.apache.spark.streaming.{Seconds, StreamingContext}import org.junit.Testclass kafkaStoreOffsetTokafka {@Testdef test()={val context = new StreamingContext("local[*]", "toKfa", Seconds(5))val kafkaParams = Map[String, Object]("bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "kfk-streaming-test",// 每次消费者从哪个位置开始消费,上一次数据的offset"auto.offset.reset" -> "latest","enable.auto.commit" -> "false"//!!!!!!!!!!!!!取消自动提交offset)// 指定要消费的主体val topics: Array[String] = Array("streaming-test1")val ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](context,LocationStrategies.PreferBrokers,Subscribe[String, String](topics, kafkaParams))ds.foreachRDD { rdd =>val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges// some time later, after outputs have completed///*for(offset<-offsetRanges){println(offset)}*/rdd.map(x=>{// if (x.value().equals("d") ) 1/0(x.value(),1)}).reduceByKey(_+_).collect().foreach(println(_))// 手动提交offset,上面的逻辑一部分成功,一部分失败,那会事先提交成功部分,ds.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)}context.start()context.awaitTermination()}}
Your own data store(mysql)
- 自己维护offset!
核心: ①取消自动提交offset
②在程序开始计算之前,先从 mysql中读取上次提交的offsets
③基于上次提交的offsets,构造一个DS,这个DS从上次提交的offsets位置向后消费的数据流
def SubscribePatternK, V: ConsumerStrategy[K, V]
④需要将结果,收集到Driver端,和offsets信息,组合为一个事务,一起写入数据库
成功,提交,失败,就回滚!
通过mysql的事务回顾,实现精准一次
Mysql中表的设计:
运算的结果: 单词统计
result(单词 varchar, count int)
offsets:
offsets(group_id varchar, topic varchar, partition int , offset bigint)
* 精准一次!借助事务!
在一个事务中,写入结果和偏移量<br /> 当前是有状态的计算!<br /> 第一批: (a,2)第二批: a,a<br /> 输出(a,4)语句?<br /> insert<br /> update
如果存在(通过主键来判断)就更新,如果不存在就插入 a-2 —-> a—>4 ,b-4
#VALUES(COUNT) 代表读取当前传入的count列的值 COUNT代表当前表中的count列的值
INSERT INTO wordcount VALUE(‘b’,4) ON DUPLICATE KEY UPDATE count= COUNT + VALUES(COUNT);
发生错误前:
kafka:
mysql: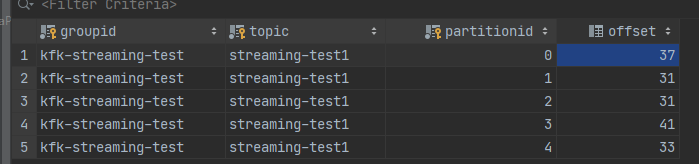
发生错误后:
kafka:
mysql:
offset不变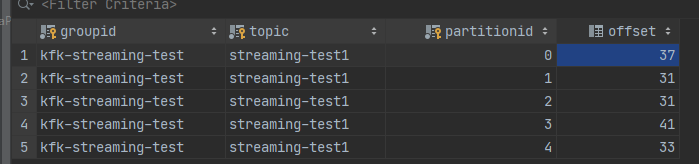
代码
思路:
1、连接kafka
配置消费者
指定主题
2、基于上次offset,创造一个ds
①上次offset:在mysql中找
②注意:
val ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](comsumerRecord键值对,
中的key只是为了分区,不存数据,value才是存数据的
3、根据上面的ds,消费数据,并创建ds.foreachRDD计算逻辑
设置mysql的事务回滚,实现精准一次,将result,offsetRanges一起传进mysql的事务回滚方法中
0、mysql的连接
1)Connection
2)PreparedStatement,传入sql,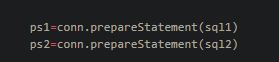
①需要写sql语句
需要用到占位符 ?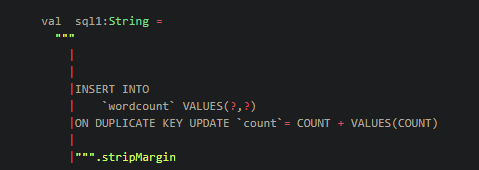
②需要用到setSxx(占位符索引,字段名)来设置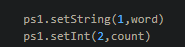
3)ResultSet(查询用,因为查询会将多个结果以结果集的形式返回)
4)事务的设置:
在catch中实现
5)在finally关流!
package com.atguigu.sparksteaming.kafka
import java.sql.{Connection, PreparedStatement, ResultSet}
import com.atguigu.sparksteaming.utils.JDBCUtil
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object KafkaDirectStoreOffsetToMysql {
val groupId:String ="0223"
val streamingContext = new StreamingContext("local[2]", "wc", Seconds(5))
def main(args: Array[String]): Unit = {
// 消费者的配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> "false"
)
// 查询之前已经在mysql中保存的offset
val offsetsMap: Map[TopicPartition, Long] = readHitoryOffsetsFromMysql(groupId)
//指定要消费主题
val topics = Array("topic2")
// 基于上次提交的offsets,构造一个DS,这个DS从上次提交的offsets位置向后消费的数据流
val ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams,offsetsMap)
)
ds.foreachRDD { rdd =>
//消费到了数据
if (!rdd.isEmpty()){
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach(println)
//计算逻辑
val result: Array[(String, Int)] = rdd.map(record => (record.value(), 1)).reduceByKey(_ + _).collect()
// 开启事务,和offsets一起写入mysql
writeResultAndOffsetsToMysql(result,offsetRanges)
}
}
streamingContext.start()
streamingContext.awaitTermination()
}
//从Mysql读取历史偏移量
def readHitoryOffsetsFromMysql(groupId: String) : Map[TopicPartition, Long] = {
val offsetsMap: mutable.Map[TopicPartition, Long] = mutable.Map[TopicPartition, Long]()
var conn:Connection=null
var ps:PreparedStatement=null
var rs:ResultSet=null
val sql:String=
"""
|
|SELECT
| `topic`,`partitionid`,`offset`
|FROM `offsets`
|WHERE `groupid`=?
|
|
|""".stripMargin
try {
conn=JDBCUtil.getConnection()
ps=conn.prepareStatement(sql)
ps.setString(1,groupId)
rs= ps.executeQuery()
while(rs.next()){
val topic: String = rs.getString("topic")
val partitionid: Int = rs.getInt("partitionid")
val offset: Long = rs.getLong("offset")
val topicPartition = new TopicPartition(topic, partitionid)
offsetsMap.put(topicPartition,offset)
}
}catch {
case e:Exception =>
e.printStackTrace()
throw new RuntimeException("查询偏移量出错!")
}finally {
if (rs != null){
rs.close()
}
if (ps != null){
ps.close()
}
if (conn != null){
conn.close()
}
}
//将可变map转为不可变map
offsetsMap.toMap
}
def writeResultAndOffsetsToMysql(result: Array[(String, Int)], offsetRanges: Array[OffsetRange]): Unit = {
val sql1:String =
"""
|
|
|INSERT INTO
| `wordcount` VALUES(?,?)
|ON DUPLICATE KEY UPDATE `count`= COUNT + VALUES(COUNT)
|
|""".stripMargin
val sql2:String =
"""
|INSERT INTO
| `offsets` VALUES(?,?,?,?)
| ON DUPLICATE KEY UPDATE `offset`= VALUES(OFFSET)
|
|
|""".stripMargin
var conn:Connection=null
var ps1:PreparedStatement=null
var ps2:PreparedStatement=null
try {
conn=JDBCUtil.getConnection()
//取消事务的自动提交 ,只有取消了自动提交,才能将多次写操作组合为一个事务,手动提交
conn.setAutoCommit(false)
ps1=conn.prepareStatement(sql1)
ps2=conn.prepareStatement(sql2)
// 模式匹配
for ((word, count) <- result) {
ps1.setString(1,word)
ps1.setInt(2,count)
ps1.addBatch()
}
//一批insert执行一次
ps1.executeBatch()
//模拟异常
//1 / 0
for (offsetRange <- offsetRanges) {
ps2.setString(1,groupId)
ps2.setString(2,offsetRange.topic)
ps2.setInt(3,offsetRange.partition)
ps2.setLong(4,offsetRange.untilOffset)
ps2.addBatch()
}
ps2.executeBatch()
//手动提交事务
conn.commit()
}catch {
case e:Exception =>
e.printStackTrace()
//回滚事务
conn.rollback()
//重启app ,暂时以停止代替
streamingContext.stop(true)
}finally {
if (ps1 != null){
ps1.close()
}
if (ps2 != null){
ps2.close()
}
if (conn != null){
conn.close()
}
}
}
}

若有收获,就点个赞吧
0 人点赞
