WordCount案例实操
Spark Shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDEA中编制程序,然后打成Jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理Jar包的依赖。
编写程序
1)创建一个Maven项目WordCount
2)在项目WordCount上点击右键,Add Framework Support=》勾选scala
3)在main下创建scala文件夹,并右键Mark Directory as Sources Root=>在scala下创建包名为com.atguigu.spark
4)输入文件夹准备:在新建的WordCount项目名称上右键=》新建input文件夹=》在input文件夹上右键=》分别新建1.txt和2.txt。每个文件里面准备一些word单词。
5)导入项目依赖
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.0</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals><configuration><args><arg>-dependencyfile</arg><arg>${project.build.directory}/.scala_dependencies</arg></args></configuration></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass></mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
注意:如果maven版本为3.2.x,插件下载报错,那么修改插件版本为3.3.2<br />6)创建伴生对象WordCount,编写代码
package com.atguigu.sparkimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf = new SparkConf().setAppName("WC").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc = new SparkContext(conf)//3.读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input")//4.读取的一行一行的数据分解成一个一个的单词(扁平化)(hello)(atguigu)(atguigu)val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))//5. 将数据转换结构:(hello,1)(atguigu,1)(atguigu,1)val wordToOneRdd: RDD[(String, Int)] = wordRdd.map(word => (word, 1))//6.将转换结构后的数据进行聚合处理 atguigu:1、1 =》1+1 (atguigu,2)val wordToSumRdd: RDD[(String, Int)] = wordToOneRdd.reduceByKey((v1, v2) => v1 + v2)//7.将统计结果采集到控制台打印val wordToCountArray: Array[(String, Int)] = wordToSumRdd.collect()wordToCountArray.foreach(println)//一行搞定//sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile(args(1))//8.关闭连接sc.stop()}}
7)打包插件
<plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><archive><manifest><mainClass>com.atguigu.spark.WordCount</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin>
8)打包到集群测试
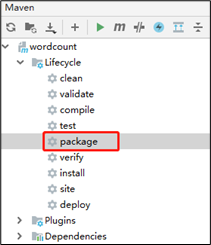
(1)点击package打包,然后,查看打完后的jar包
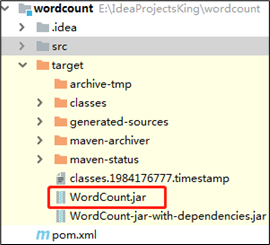
(2)将WordCount.jar上传到/opt/module/spark-yarn目录
(3)在HDFS上创建,存储输入文件的路径/input
[atguigu@hadoop102 spark-yarn]$ hadoop fs -mkdir /input
(4)上传输入文件到/input路径
[atguigu@hadoop102 spark-yarn]$ hadoop fs -put /opt/module/spark-local/input/1.txt /input
(5)执行任务
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \--class com.atguigu.spark.WordCount \--master yarn \WordCount.jar \/input \/output
注意:input和ouput都是HDFS上的集群路径。
(6)查询运行结果
[atguigu@hadoop102 spark-yarn]$ hadoop fs -cat /output/*
9)注意:如果运行发生压缩类没找到
(1)原因
Spark on Yarn会默认使用Hadoop集群配置文件设置编码方式,但是Spark在自己的spark-yarn/jars 包里面没有找到支持lzo压缩的jar包,所以报错。
(2)解决方案一:拷贝lzo的包到/opt/module/spark-yarn/jars目录
[atguigu@hadoop102 common]$cp /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar /opt/module/spark-yarn/jars
(3)解决方案二:在执行命令的时候指定lzo的包位置
[atguigu@hadoop102 spark-yarn]$bin/spark-submit \--class com.atguigu.spark.WordCount \--master yarn \--driver-class-path /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar \WordCount.jar \/input \/output
本地调试
本地Spark程序调试需要使用Local提交模式,即将本机当做运行环境,Master和Worker都为本机。运行时直接加断点调试即可。如下:
1)代码实现
package com.atguigu.sparkimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf = new SparkConf().setAppName("WC").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc = new SparkContext(conf)//3.读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input")//4.读取的一行一行的数据分解成一个一个的单词(扁平化)(hello)(atguigu)(atguigu)val wordRdd: RDD[String] = lineRdd.flatMap(_.split(" "))//5. 将数据转换结构:(hello,1)(atguigu,1)(atguigu,1)val wordToOneRdd: RDD[(String, Int)] = wordRdd.map((_, 1))//6.将转换结构后的数据进行聚合处理 atguigu:1、1 =》1+1 (atguigu,2)val wordToSumRdd: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)//7.将统计结果采集到控制台打印wordToSumRdd.collect().foreach(println)//8.关闭连接sc.stop()}}
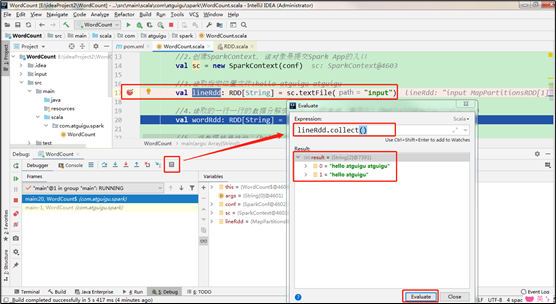
关联源码
1)按住ctrl键,点击RDD
2)提示下载或者绑定源码
3)解压资料包中spark-3.0.0.tgz到非中文路径。例如解压到:E:\02_software
4)点击Attach Sources…按钮,选择源码路径E:\02_software\spark-3.0.0
异常处理
如果本机操作系统是Windows,如果在程序中使用了Hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常: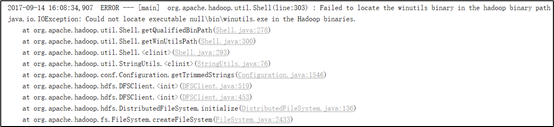
出现这个问题的原因,并不是程序的错误,而是用到了Hadoop相关的服务,解决办法
1)配置HADOOP_HOME环境变量
2)在IDEA中配置Run Configuration,添加HADOOP_HOME变量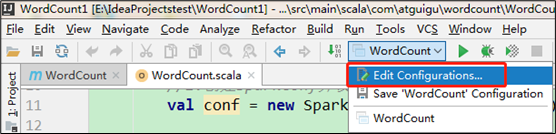

若有收获,就点个赞吧
0 人点赞
