/*
RDD的持久化:
原因: RDD不存储数据,所以如果多个job中rdd重复使用的时候每个job都会自动重新计算得到数据,所以可能导致数据重复计算
场景: RDD重复使用的时候
两种RDD:
1)缓存: 将数据保存在本机内存/磁盘中
1、rdd.cache: 数据只保存在内存中
2、rdd.persist(存储级别): 可以指定存储级别,默认是级别: MEMORY_ONLY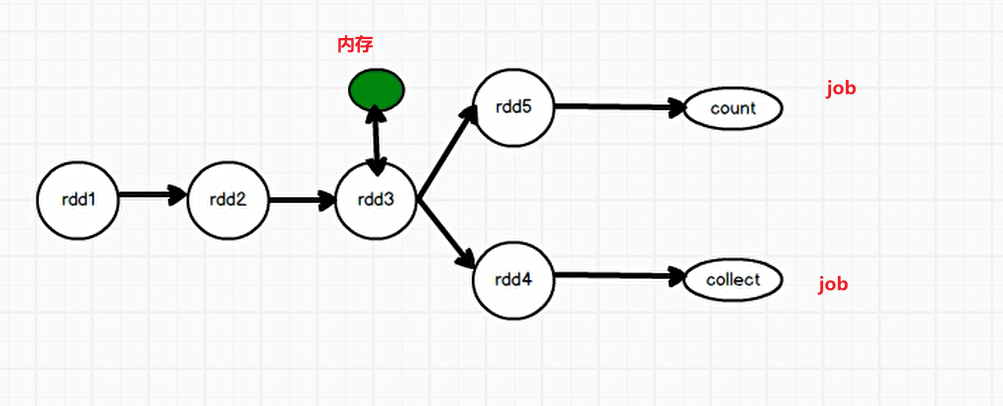
2) checkpoint: 将数据保存在HDFS中
如何使用:
1、设置checkpoint路径: sc.setCheckpointDir(..)
2、rdd持久化:rdd.checkpoint
说明:
一个job执行完成之后如果job中有rdd使用checkpoint此时会额外执行一个job,这个job会把前面的rdd再执行一遍以确保数据安全
所以在工作中checkpoint一般是结合cache使用,减少数据重复计算的次数。使用cache后就不会再执行rdd前面的rdd,减少了重复计算次数
意义:
!由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。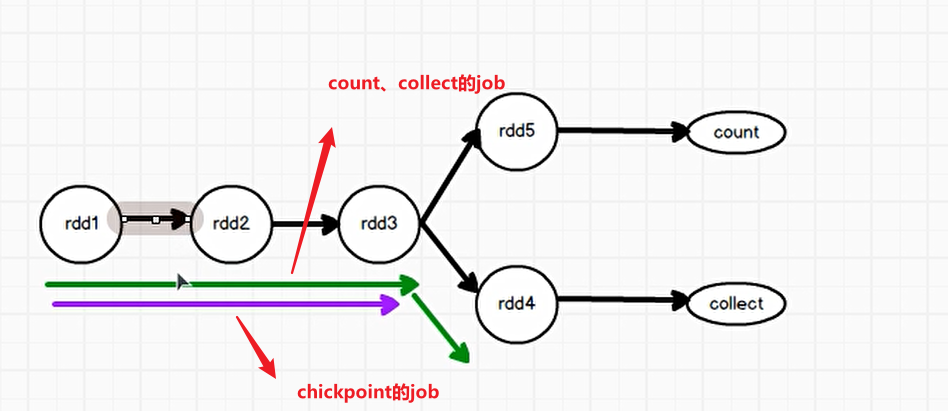
cache与checkpoint的区别:
1、数据存储位置不一样:
缓存将数据保存在本机内存/磁盘中
checkpoint将数据保存在HDFS中
2、RDD依赖关系是否保留不一样:
缓存因为是将数据保存在本机内存/磁盘中,所以如果服务器宕机,此时数据丢失,需要通过rdd的依赖关系重新计算得到数据
* checkpoint是将数据保存在HDFS中,数据不会丢失,RDD依赖关系会切除
* shuffle算子数据会落盘,相当于自带cache操作。
* 存储级别:<br /> * NONE: 不存储<br /> * DISK_ONLY : 只保存在磁盘中<br /> * DISK_ONLY_2: 只保存在磁盘中,保存两份<br /> * MEMORY_ONLY : 只保存在内存中<br /> * MEMORY_ONLY_2 : 只保存在内存中,保存两份<br /> * MEMORY_ONLY_SER: 只保存在内存中,数据序列化存储<br /> * MEMORY_ONLY_SER_2 : 只保存在内存中,数据序列化存储,保存两份<br /> * MEMORY_AND_DISK : 数据保存在内存中,如果内存不足自动保存到磁盘中<br /> * MEMORY_AND_DISK_2 : 数据保存在内存中,如果内存不足自动保存到磁盘中,保存两份<br /> * MEMORY_AND_DISK_SER : 数据保存在内存中,如果内存不足自动保存到磁盘中,数据序列化存储,<br /> * MEMORY_AND_DISK_SER_2: 数据保存在内存中,如果内存不足自动保存到磁盘中,数据序列化存储,保存两份<br /> * OFF_HEAP : 数据保存在堆外内存<br /> * 工作中常用的存储级别: MEMORY_ONLY【用于小数据量场景】、MEMORY_AND_DISK【用于大数据量场景】<br /> */
package tcode.day05import org.apache.spark.{SparkConf, SparkContext}object $05_Persist {def main(args: Array[String]): Unit = {val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test"))val rdd1 = sc.textFile("datas/wc.txt")val rdd2 = rdd1.flatMap(line=>{println("------------------------------------")line.split(" ")})val rdd3 = rdd2.map((_,1))val rdd4 = rdd3.reduceByKey(_+_)val rdd6 = rdd4.map(_._2)val rdd5 = rdd4.glom()rdd5.collect()rdd6.collect()Thread.sleep(1000000)}/*def main(args: Array[String]): Unit = {val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test"))sc.setCheckpointDir("checkpoint")val rdd1 = sc.textFile("datas/wc.txt")val rdd2 = rdd1.flatMap(line=>{println("------------------------------------")line.split(" ")})val rdd3 = rdd2.map((_,1))// rdd3.cacherdd3.checkpoint()println(rdd3.toDebugString)val rdd4 = rdd3.glom()val rdd5 = rdd3.coalesce(2)rdd4.collect().toListprintln(rdd3.toDebugString)rdd5.count()Thread.sleep(1000000)}*/}

若有收获,就点个赞吧
0 人点赞
