FLINK
概述
flink是一个高性能的分布式处理引擎
与SparkStreaming的区别
世界观
sparkstreaming 为批次处理,不是真正的实时
flink 来一条数据处里一次,是真正的流式处理
public class Flink_Stream_1 {public static void main(String[] args) throws Exception {// 1. 获取流的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 2. 从数据源获取一个流SingleOutputStreamOperator<Tuple2<String, Long>> result = env// 3. 对流做各种转换.readTextFile("input/words.txt").flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line,Collector<String> out) throws Exception {for (String word : line.split(" ")) {out.collect(word);}}}).map(new MapFunction<String, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(String word) throws Exception {return Tuple2.of(word, 1L);}}).keyBy(new KeySelector<Tuple2<String, Long>, String>() {@Overridepublic String getKey(Tuple2<String, Long> t) throws Exception {return t.f0;}}).sum(1);// 4. 输出结果result.print();// 5. 启动执行环境env.execute();}}
容错机制
sparkstreaming 的要保证数据的一致性必须借助拥有事务功能的其他数据库来维护offset,他的checkpoint比较鸡肋,会有可能造成数据重复(先写数据到到数据库,在保存offsets)
flink 则可以保证端到端的一致性,使用的是Chandy-Lamport 算法,多并行度下需要设置barrier对齐。
barrier不对齐的情况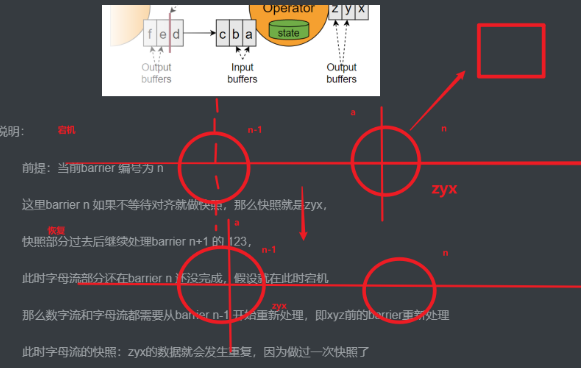
说明:
前提:当前barrier 编号为 a,chickpoint位置为n
这里checkpoint n 如果不等待对齐就做快照,那么快照就是zyx,
此时字母流部分还没到达chickpoint n ,假设就在此时宕机
那么数字流和字母流都需要从chickpoint n-1 开始重新处理
此时对于checkpoint n来说,zyx的数据就会发生重复,因为做过一次快照了
两阶段提交实现一致性: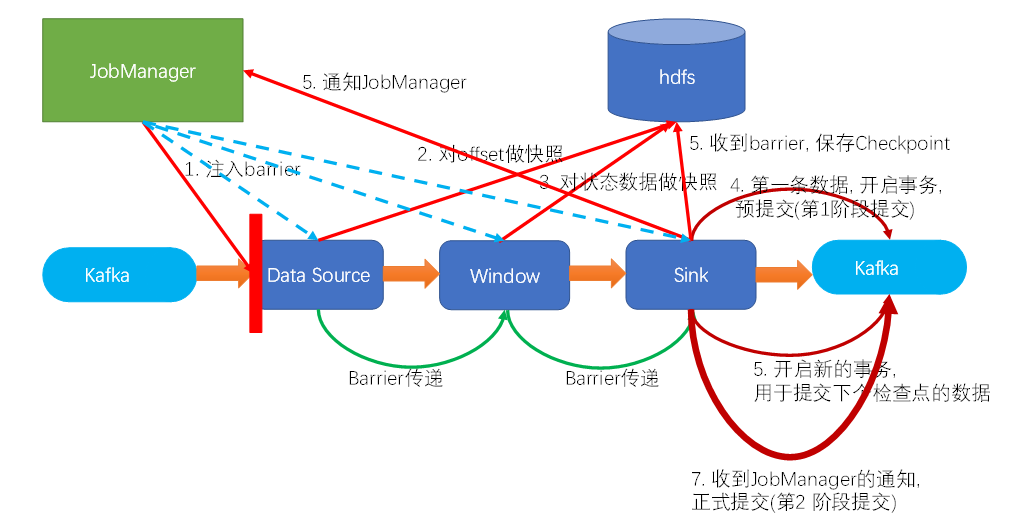
说明:
前提:barrier可以看做是一条特殊的数据,算子遇到一个barrier就会做一次快照,快照的是被算子处理过的数据
流程:
- jm的协调器注入barrier到source
- source遇到barrier做快照
- barrier向后传递并对齐
- 对状态做快照。。。
- 预提交:sink在遇到barrier时,将数据第一次预写到kafka,同时开始下一波写到kafka的事务,并进行本波checkpoint,等待checkpoint完成(这里容易忽略的是事务这个特性,因为在第一次预写前就已经处在事务当中了,遇到barrier后是开启新一轮事务,之后sink每遇到一个新的barrier都会开启下一轮的新事务)。预提交的左右就是为了保证数据能先做完checkpoint才真正提交
- 当sink的checkpoint完成,此时jm认为所有操作都完成,通知所有算子,已经完成
- 第二阶段提交: 此时sink提交事务,完成第二阶段提交
资源管理
sparkstreaming使用 指定cpu数,executor数等参数后,不能共享给其他job
flink 的slot空闲的情况下,比如申请了2个slot,只用到1个,那么另一个slot是可以共享给其他job的(slot是用来计算的资源,包含cpu,内存),使用更加灵活驱动
sparkstreaming 是一个批次一个job,不管有没有数据都要启job,浪费资源
flink 是事件驱动的,有数据才计算,没数据不会计算状态管理
sparkstreaming 的状态通常需要借助外部存储如redis
flink 有自己的内存管理,可存储在状态后端上,不需要借助外部时间语义
sparkstreaming 只有处理时间
> flink 会有事件时间,处理时间,注入时间核心概念
主要成员
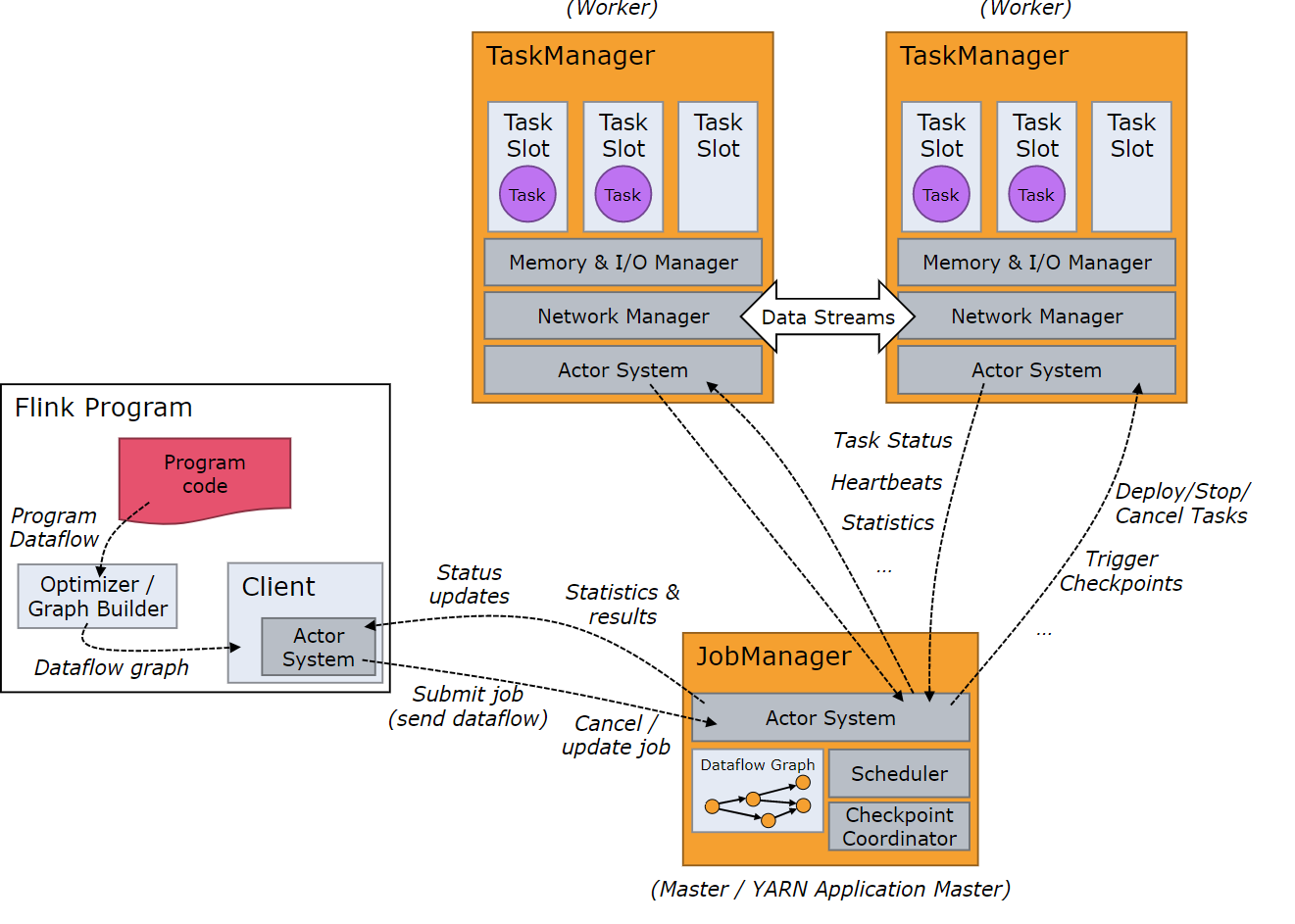
- 客户端:提交作业,生成流图、作业图
- jobmanger:接收申请,处理为执行图,然后部署到taskmanager上执行,相当于yarn的applicationmaster
- taskmanager:里面会根据申请的资源生成对应数量的slot,在槽中执行相对应的task,相当于yarn的Container中运行 的task
- task:任务,一个算子就是一个task
- subtask : 子任务,一个task会有多个subtask,这个概念与并行度有关
- 并行度:作用:提高并发
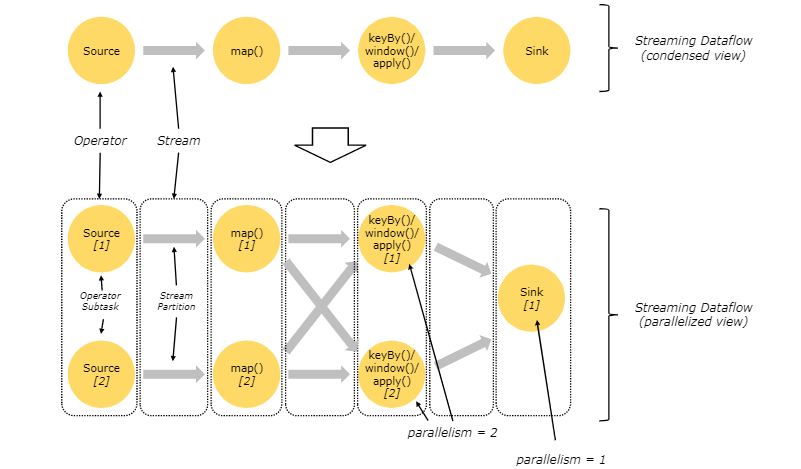
- 可以理解为分区,同一个算子,不同的subtask代表不同的并行度
- 同一个job中,不同算子的并行度可以不一致
- 不同的task(不考虑操作链)会在不同slot中,不同的并行度也一定在不同的slot中
- 给算子设置并行度(优先级越来越高,4最高):
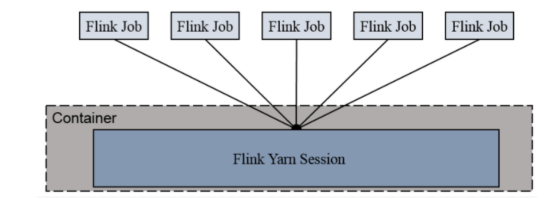
per-job-cluster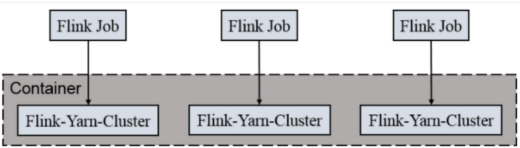
特性:
一个job启动一个yarn集群,
job完成后关闭集群
job之间不会争抢资源
main函数在客户端
适用:
适合规模大,长时间运行的job
Application mode
特性:
和per-job-cluster一样
main函数在yarn的nodemanager(appmastar)上,也就是在集群上
区别:
用户的main函数是在集群中(job manager)执行的
主要特性
状态
作用:用来存储当前数据结果,用以后续数据计算的使用
种类:
算子状态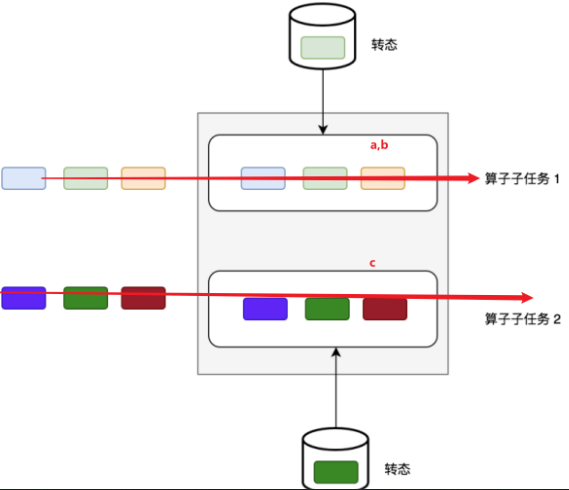
算子状态,只和并行度有关,不同key有可能在不同的并行度中,同一并行度不同的key都可以访问同一个状态,按并行度进行隔离
种类:列表状态,联合列表状态,广播状态(可用以动态分流)
键控状态:
只能用在keyby后面的流上,
状态和并行度无关,只和key有关系,有多少个不同的key就有多少个状态
种类:
valuestate 单值
liststate 列表
ReducingState不可改变类型,传入一个值聚合
AggregatingState 可改变类型,传入多个值聚合
MapState 去重
以上5中都不是,那么用getState方法,这个是通用的
状态的一致性问题:如何保证故障后状态数据的一致性。
source端:需要可以指定offset,从source端重新消费宕机前的数据
flink端:通过checkpoint恢复数据
sink端:支持事务或者幂等写入
状态后端
①存储状态
②存储checkpoint(恢复数据)
| 存储位置 | 状态 | ck |
|---|---|---|
| 内存 | TM的堆内存 | JM的堆内存 |
| FS | TM的堆内存 | HDFS |
| RocksDB | RocksDB | HDFS |
时间语义
水印
什么是水印:水印就是用来描述事件时间的特殊数据,机器是不认识事件时间的,只能依靠水印来告知。
水印的作用:
1、处理乱序数据 ,flink认为只要数据时间小于水印时间,就认为该数据已经被处理过,再有比水印时间小的数据都不会进入下游
2、用来触发:窗口关闭,定时器关闭,触发join结束等
水印特性:单调增(因为时间不会回头)
水印值计算:等于遇到的最大事件时间-乱序程度
另外:flink设置了3重方法来处理乱序、迟到数据:
水印
允许迟到时间(窗口),设置了水印后,还可以设置一段时间来存储迟到数据
测输出流,如果允许迟到时间内都没来,那么可以考虑将没来的数据放到测输出流中
窗口
flink是实时处理数据的,生产环境下,数据是无限的,不肯能等到所有数据来完才进行计算,此时我们需要统计某段时间内的结果,这个时候我们就要使用开窗来实现<br />种类:<br />时间窗口<br />滚动时间窗口,需求:每xx时间统计一次数据<br />滑动时间窗口,需求: 统计每隔xx时间统计,统计xx时间内的数据<br />会话时间窗口,<br /> 需求:每隔xx时间没有数据结束这个窗口<br /> 原理:每条数据开一个窗口,如果两条数据创建的两个窗口在设置的时间间隔内生成,那么两个窗口融合,以此类推,直到上个窗口的创建时间与下个窗口的创建时间大于设置的时间间隔<br />个数窗口<br /> 少用
定时器
注册一个定时器,当水印时间大于定时器时间,则会触发定时器,执行定时器中的逻辑
API
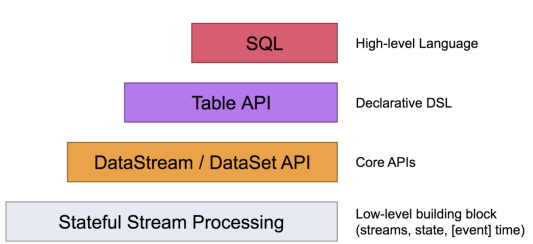
你可以在这些 API 之间,以及一些基于这些 API 的库之间轻松的切换。比如,你可以先用 CEP 从 DataStream 中做模式匹配,然后用 Table API 来分析匹配的结果CEP编程
CEP编程
类似于正则表达式的思想
用来匹配数据关系的,例如计算首页跳转率,那么需要上一页为空,下一页为首页,此时匹配上的数据才能进入下游。或者考虑匹配超时数据,只有超时的数据能进入下游
案例
求每日访客数
思路:按照键分组,然后去重
去重:取每天第一个窗口的一条数据
第一个窗口:利用状态存储日期,如果事件日期大于状态日期则更新状态日期为当前日期,并且此时的日期为今天的第一个窗口的数据
sourceStream
.map(JSON::parseObject)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.
.withTimestampAssigner((log, ts) -> log.getLong(“ts”))
)
.keyBy(obj -> obj.getJSONObject(“common”).getString(“mid”))
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction
private SimpleDateFormat sdf;
private ValueState
// 状态,存储日期,用来判断是否跨天
@Override
public void open(Configuration parameters) throws Exception {
firstVisitState = getRuntimeContext().getState(new ValueStateDescriptor
sdf = new SimpleDateFormat(“yyyy-MM-dd”);
}
@Override
public void process(String key,
Context ctx,
Iterable
Collector
String today = sdf.format(ctx.window().getEnd());
String yesterday = sdf.format(firstVisitState.value() == null ? 0L : firstVisitState.value());
// 如果日期不相等,证明是新的一天,跨天了,清空状态
if (!today.equals(yesterday)) {
firstVisitState.clear();
}
// 如果为状态为空,那么开始收集第一个窗口最小时间的数据,并更新状态
if (firstVisitState.value() == null) {
List
JSONObject min = Collections.min(list, Comparator.comparing(o -> o.getLong(“ts”)));
out.collect(min);
firstVisitState.update(min.getLong(“ts”));
}
}
})
.map(JSONAware::toJSONString)
.addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWM_UV));
求跳转率
思路:超时,不从首页进入下一页的数据则为跳出数据
利用CEP编程,
匹配:上一页面为空,当前页面为首页,然后下一页不为空的数据为不跳出的数据,而超时数据则为跳出数据
// 1. 有个流
KeyedStream
.map(JSON::parseObject)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.
.withTimestampAssigner((log, ts) -> log.getLong(“ts”))
)
.keyBy(obj -> obj.getJSONObject(“common”).getString(“mid”));
// 2. 定义模式: 开始是入口, 然后紧跟着一个页面 正常
// 跳出:
Pattern
.
.where(new SimpleCondition
@Override
// 入口的条件
public boolean filter(JSONObject value) throws Exception {
String lastPageId = value.getJSONObject(“page”).getString(“last_page_id”);
return lastPageId == null || lastPageId.isEmpty();
}
})
.next(“nextPage”)
.where(new SimpleCondition
@Override
public boolean filter(JSONObject value) throws Exception {
JSONObject page = value.getJSONObject(“page”);
String pageId = page.getString(“page_id”);
String lastPageId = page.getString(“last_page_id”);
return pageId != null && lastPageId != null && !lastPageId.isEmpty();
}
})
.within(Time.seconds(5));
// 3. 把模式应用到流上
PatternStream
// 4. 取出满足模式数据(或者超时数据)
SingleOutputStreamOperator
new OutputTag
new PatternTimeoutFunction
@Override
public JSONObject timeout(Map
long timeoutTimestamp) throws Exception {
// 超时数据, 就是跳出明细
return pattern.get(“entry”).get(0);
}
},
new PatternSelectFunction
@Override
public JSONObject select(Map
return null; // 满足正常访问的数据, 不用返回<br /> }<br /> }<br /> );<br /> normal.getSideOutput(new OutputTag<JSONObject>("timeout") {}).print("jump");
求TOP 10
需求:只能求一段时间内的Top10,例如每隔10秒统计一次1小时内商品top10
思路:使用flinkSQL ,分组,聚合,求和,倒序排列,limit10
说明:FlinkSQL暂时不支持desc,只是专门为topN做了优化
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1. 建立一个表与source关联<br /> tenv.executeSql("create table ub(" +<br /> " user_id bigint, " +<br /> " item_id bigint, " +<br /> " category_id int, " +<br /> " behavior string, " +<br /> " ts bigint, " +<br /> " et as to_timestamp(from_unixtime(ts)), " +<br /> " watermark for et as et - interval '5' second " +<br /> ")with(" +<br /> " 'connector' = 'filesystem', " +<br /> " 'path' = 'input/UserBehavior.csv', " +<br /> " 'format' = 'csv') ");<br />// tenv.sqlQuery("select * from ub").execute().print();// 2 开窗聚合,计算每个商品在每个窗口的点击量<br /> Table t1 = tenv.sqlQuery("select item_id," +<br /> "hop_start(et,interval '10' minute,interval '1' hour) w_start," +<br /> "hop_end(et,interval '10' minute,interval '1' hour) w_end," +<br /> "count(*) as item_count" +<br /> " from ub " +<br /> "where behavior = 'pv' " +<br /> "group by item_id,hop(et,interval '10' minute,interval '1' hour)");<br /> // 注册动态表<br /> tenv.createTemporaryView("t1",t1);<br />// tenv.sqlQuery("select * from " + t1).execute().print();// 3 根据聚合结果,使用over窗口进行排名,统计每个窗口的排名,所以按窗口结束时间分区<br /> Table t2 = tenv.sqlQuery("select w_end," +<br /> "item_id," +<br /> "item_count," +<br /> "row_number() over(partition by w_end order by item_count desc) as rk" +<br /> " from t1");//注册动态表<br /> tenv.createTemporaryView("t2",t2);<br /> // 4 过滤出来 名次小于等于3的<br /> Table t3 = tenv.sqlQuery("select * " +<br /> "from t2" +<br /> " where t2.rk <=3");
// tenv.sqlQuery(“select * from “ + t3).execute().print();
// 5 数据写入mysql中
// 5.1 创建动态表与mysql关联
tenv.executeSql(“create table hot_item(“ +
“w_end timestamp(3),” +
“ item_id bigint,” +
“item_count bigint,” +
“rk bigint,” +
“PRIMARY KEY (w_end,rk) Not enforced” +
“) with(“ +
“ ‘connector’ = ‘jdbc’,” +
“ ‘url’ = ‘jdbc:mysql://hadoop162:3306/flink_sql?useSSL=false’,” +
“ ‘table-name’ = ‘hot_item’ ,” +
“ ‘username’ = ‘root’ ,” +
“ ‘password’ = ‘aaaaaa’ )”);
t3.executeInsert("hot_item");
常见问题
内存不足
主要是应对高峰期,资源不足的情况
解决方案:加资源,加并行度
最佳并行度:QPS(实际)/单并行度QPS(测试)= 并行度
背压
大部分情况是数据倾斜产生
解决方法:先断操作链,然后打开web ui 查看背压项,然后会看到很多标记为high的红色标签,找到显示为ok的那个task,去更改这个位置的代码
数据倾斜
数据倾斜分为分组前和分组后
keyBy前:没分组就已经数据倾斜,此时使用重分区算子分区以下即可
keyBy后:因为是流式数据,如果使用两次mr的思想,有多少条数据那么最后输出的也是这么多条数据,没办法解决数据倾斜问题。
除非开窗,开窗,保证这个窗口的结果是正确的。开窗后使用两次1mr思想,第一次mr添加随机数,第二次mr消除随机数。
相关依赖
<build><br /> <plugins><br /> <plugin><br /> <groupId>org.apache.maven.plugins</groupId><br /> <!--官方推荐的打包依赖--><br /> <artifactId>maven-shade-plugin</artifactId><br /> <version>3.2.4</version><br /> <executions><br /> <execution><br /> <phase>package</phase><br /> <goals><br /> <goal>shade</goal><br /> </goals><br /> <configuration><br /> <artifactSet><br /> <excludes><br /> <exclude>com.google.code.findbugs:jsr305</exclude><br /> <exclude>org.slf4j:*</exclude><br /> <exclude>log4j:*</exclude><br /> </excludes><br /> </artifactSet><br /> <filters><br /> <filter><br /> <!-- Do not copy the signatures in the META-INF folder.<br /> Otherwise, this might cause SecurityExceptions when using the JAR. --><br /> <artifact>*:*</artifact><br /> <excludes><br /> <exclude>META-INF/*.SF</exclude><br /> <exclude>META-INF/*.DSA</exclude><br /> <exclude>META-INF/*.RSA</exclude><br /> </excludes><br /> </filter><br /> </filters><br /> <transformers combine.children="append"><br /> <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"><br /> </transformer><br /> </transformers><br /> </configuration><br /> </execution><br /> </executions><br /> </plugin><br /> </plugins><br /> </build>

若有收获,就点个赞吧
0 人点赞
