集群介绍
- 扩容
- 提高读写并发
- 提高可靠性、可用性
什么是集群:
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
创建集群
安装ruby环境:
本身redis集群的安装是很麻烦了,通过ruby工具,可以非常方便的将一系列命令打包为一个脚本!
依次执行在安装光盘下的Package目录(/media/CentOS_6.8_Final/Packages)下的rpm包:
| rpm -ivh compat-readline5-5.2-17.1.el6.x86_64.rpm |
|---|
| rpm -ivh ruby-libs-1.8.7.374-4.el6_6.x86_64.rpm |
| rpm -ivh ruby-1.8.7.374-4.el6_6.x86_64.rpm |
| rpm -ivh ruby-irb-1.8.7.374-4.el6_6.x86_64.rpm |
| rpm -ivh ruby-rdoc-1.8.7.374-4.el6_6.x86_64.rpm |
| rpm -ivh rubygems-1.3.7-5.el6.noarch.rpm |
也可以在联网状态下,执行yum安装,执行yum -y install ruby;
之后安装rubygem,rubygem是ruby的包管理框架。yum -y install rubygems
安装redis gem
redis-3.2.0.gem是一个通过ruby操作redis的插件!
拷贝redis-3.2.0.gem到/opt目录下,在opt目录下执行 gem install —local redis-3.2.0.gem;
制作6个redis配置文件
端口号分别是:6379,6380,6381,6389,6390,6391
注意:每个配置文件中需要指定
daemonize yes: 服务在后台运行port:端口号pidfile:pid保存文件logfile:日志文件(如果没有指定的话,就不需要)dump.rdb: RDB备份文件的名称appendonly关掉,或者是更改appendonly文件的名称。cluster-enabled yes 打开集群模式cluster-config-file nodes-6379.conf 设定节点配置文件名cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
样例:
include /usr/local/myredis/rediscluster/redis_base.confpidfile "/var/run/redis_6379.pid"port 6379dbfilename "dump_6379.rdb"cluster-enabled yescluster-config-file nodes-6379.confcluster-node-timeout 15000
注意在创建集群的时候,初始化的时候,把所有节点的dump文件全部删掉。
开启集群
①首先依次启动6个节点,启动后,会在当前文件夹生成nodes-xxxx.conf文件<br /><br /> ②配置集群<br /> 在/opt/redis-3.2.5/src目录下,执行命令:
./redis-trib.rb create --replicas 1\192.168.1.102:6379 \192.168.1.102:6380 \192.168.1.102:6381 \192.168.1.102:6389 \192.168.1.102:6390 \192.168.1.102:6391
注意,此处不要用127.0.0.1,请用真实IP地址!

③之后登录到客户端,通过 cluster nodes 命令查看集群信息
④6个节点,为什么是三主三从?
配置机器,至少需要6个节点,否则会报错:
命令create,代表创建一个集群。参数—replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
一个集群至少要有三个主节点,分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
slot
进入集群后,如果我们,直接写入数据,可能会看到报错信息:<br /><br /> 这是因为,集群中多了slot(插槽)的设计。一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。<br />集群中的每个节点负责处理一部分插槽。举个例子, 如果一个集群可以有主节点, 其中:<br /> 节点 A 负责处理 0 号至 5500 号插槽。<br /> 节点 B 负责处理 5501 号至 11000 号插槽。<br /> 节点 C 负责处理 11001 号至 16383 号插槽。<br />
集群中写入数据
客户端重定向
①在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器插槽,redis会报错,并告知应前往的redis实例地址和端口。
②redis-cli客户端提供了–c 参数实现自动重定向。如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。
③每个slot可以存储一批键值对。
mset等多键操作
采用哈希算法后,会自动地分配slot,而不在一个slot下的键值,是不能使用mget,mset等多键操作。
如果有需求,需要将一批业务数据一起插入呢?
解决:可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。
集群中读取数据
Ø CLUSTER KEYSLOT 
Ø CLUSTER COUNTKEYSINSLOT
Ø CLUSTER KEYSLOT 
Ø CLUSTER GETKEYSINSLOT 
集群中故障恢复
问题1:如果主节点下线?从节点能否自动升为主节点?
答:主节点下线,从节点自动升为主节点。
redis-cli -h 192.168.4.128 -p 6380 shoudown

问题2:主节点恢复后,主从关系会如何?
主节点恢复后,主节点变为从节点!
问题3:如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
答:服务是否继续,可以通过redis.conf中的cluster-require-full-coverage参数(默认关闭)进行控制。
主从都宕掉,意味着有一片数据,会变成真空,没法再访问了!
如果无法访问的数据,是连续的业务数据,我们需要停止集群,避免缺少此部分数据,造成整个业务的异常。此时可以通过配置cluster-require-full-coverage为yes.
如果无法访问的数据,是相对独立的,对于其他业务的访问,并不影响,那么可以继续开启集群体提供服务。此时,可以配置cluster-require-full-coverage为no。
集群的优缺点
优点:
l 实现扩容
l 分摊压力
l 无中心配置相对简单
缺点:
l 多键操作是不被支持的
l 多键的Redis**事务是**不被支持的。lua脚本不被支持。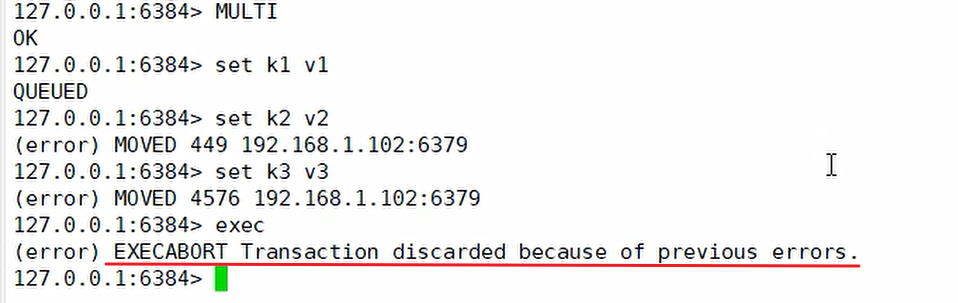
l 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。

若有收获,就点个赞吧
0 人点赞
