安装使用
0)停止Standalone模式下的spark集群
[atguigu@hadoop102 spark-standalone]$ sbin/stop-all.sh[atguigu@hadoop102 spark-standalone]$ zk.sh stop[atguigu@hadoop103 spark-standalone]$ sbin/stop-master.sh
1)为了防止和Standalone模式冲突,再单独解压一份spark
[atguigu@hadoop102 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
2)进入到/opt/module目录,修改spark-3.0.0-bin-hadoop3.2名称为spark-yarn
[atguigu@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-yarn
3)修改hadoop配置文件/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml,添加如下内容
因为测试环境虚拟机内存较少,防止执行过程进行被意外杀死,做如下配置
[atguigu@hadoop102 hadoop]$ vi yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
4)分发配置文件
[atguigu@hadoop102 conf]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
5)修改/opt/module/spark-yarn/conf/spark-env.sh,添加YARN_CONF_DIR配置,保证后续运行任务的路径都变成集群路径
[atguigu@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh[atguigu@hadoop102 conf]$ vi spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
6)启动HDFS以及YARN集群
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
7)执行一个程序
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \./examples/jars/spark-examples_2.12-3.0.0.jar \10
参数:—master yarn,表示Yarn方式运行;—deploy-mode表示客户端方式运行程序
8)如果运行的时候,抛出如下异常ClassNotFoundException:com.sun.jersey.api.client.config.ClientConfig
-原因分析:Spark2中jersey版本是2.22,但是yarn中还需要依赖1.9,版本不兼容
-解决方式:在yarn-site.xml中,添加
<property><name>yarn.timeline-service.enabled</name><value>false</value></property>
9)查看hadoop103:8088页面,点击History,查看历史页面
思考:目前是Hadoop的作业运行日志展示,如果想获取Spark的作业运行日志,怎么办? 
配置历史服务
由于是重新解压的Spark压缩文件,所以需要针对Yarn模式,再次配置一下历史服务器。
1)修改spark-default.conf.template名称
[atguigu@hadoop102 conf]$ mv spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(写)
[atguigu@hadoop102 conf]$ vi spark-defaults.confspark.eventLog.enabled truespark.eventLog.dir hdfs://hadoop102:9820/sparklog
3)修改spark-env.sh文件,添加如下配置:
[atguigu@hadoop102 conf]$ vi spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080-Dspark.history.fs.logDirectory=hdfs://hadoop102:9820/sparklog-Dspark.history.retainedApplications=30"# 参数1含义:WEBUI访问的端口号为18080# 参数2含义:指定历史服务器日志存储路径# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
配置Yarn与Spark历史服务器关联
为了从Yarn上关联到Spark历史服务器,需要配置关联路径。
1)修改配置文件/opt/module/spark-yarn/conf/spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080spark.history.ui.port=18080
2)重启Spark历史服务
[atguigu@hadoop102 spark-yarn]$ sbin/stop-history-server.sh[atguigu@hadoop102 spark-yarn]$ sbin/start-history-server.sh
3)提交任务到Yarn执行
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \./examples/jars/spark-examples_2.12-3.0.0.jar \10
4)Web页面查看日志:http://hadoop103:8088/cluster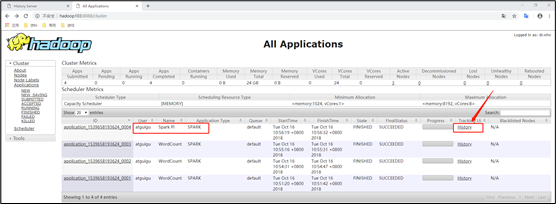
点击“history”跳转到http://hadoop102:18080/

若有收获,就点个赞吧
0 人点赞
