flow-job成员
flow:工作流,即工作流程
job:每个工作
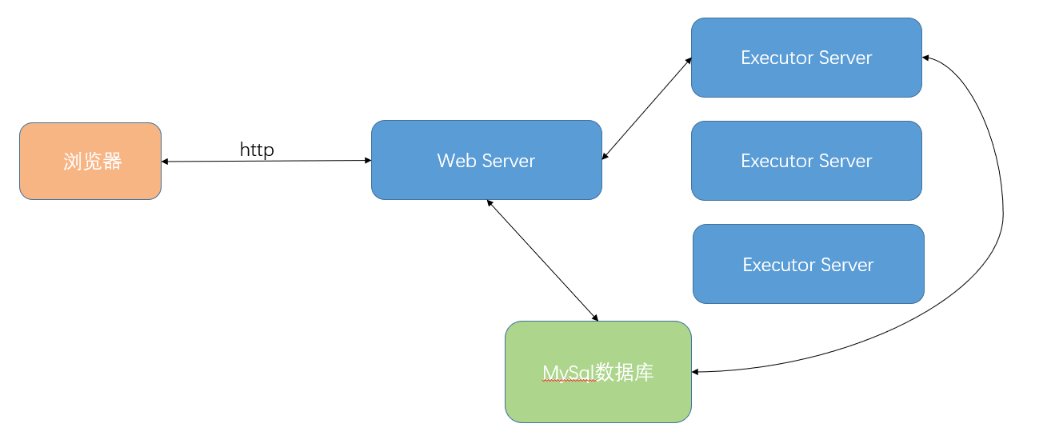
web server(一台、进程) 对接客户端,调度任务
executorserver(多台、进程) 负责工作流的计算与执行
指令
说明:安装完成之后,每次启动executor-server时,必须在 executor-server家目录启动,因为在配置文件中有大量的相对路径,只有在家目录启动,才能正确匹配相对路径!
executor启动、激活
每台机器上:
bin/start-exec.sh
executor停止
每台机器上:
bin/shutdown-exec.sh
web 启动
安装了web server的服务器上:
bin/start-web.sh
web 关闭
bin/start-web.sh
启动脚本az.sh
参数:start、stop
#!/bin/bash#azkaban的一键启动脚本,只接收单个start或stop参数if(($#!=1))thenecho 请输入单个start或stop参数!exitfi#对传入的单个参数进行校验,且执行相应的启动和停止命令if [ $1 = start ]then#启动executorxcall "cd /opt/module/azkaban/azkaban-exec ; bin/start-exec.sh "sleep 5s#激活executorfor i in hadoop102 hadoop103 hadoop104docurl -G $i:12321/executor?action=activate && echodone#启动web-servercd /opt/module/azkaban/azkaban-webbin/start-web.shelif [ $1 = stop ]thencd /opt/module/azkaban/azkaban-webbin/shutdown-web.shxcall /opt/module/azkaban/azkaban-exec/bin/shutdown-exec.shelseecho 请输入单个start或stop参数!fixcall jps
xcall
#!/bin/bash#校验是否传入了命令if(($#==0))thenecho 请输入要执行的命令!exit;fiecho "要执行的命令是:$@"#使用ssh登录到目标机器执行命令for((i=102;i<=104;i++))doecho "--------------------hadoop$i--------------------"ssh hadoop$i $@done
流程说明
浏览器可访问webserver(进程),上传数据,通过web server将数据存储在mysql,
之后web server让executor server对mysql中的数据进行查询并计算。
后续executor server执行的一些信息(进度、状态)也会被存储在mysql
浏览器通过webserver可以查询executor server计算后的数据
可构建多个executor server集群,web server会将数据分配给某个executor server去执行
之后用户通过浏览器再通过web server去查询数据库中的信息
注意事项
2.0 azkaban支持 properties配置文件,也支持yml配置文件!
3.0 azkaban默认支持yml配置文件!
安装完成之后,每次启动executor-server时,必须在 executor-server家目录启动,因为在配置文件中有大量的相对路径,只有在家目录启动,才能正确匹配相对路径!
az.sh 放在webserver安装的机器上!
Job的参数可以直接在web界面修改!
Flow的配置,只能在配置文件中修改!无法在web界面修改!
azkaban调度脚本时:
①执行权限
②executor Server找到脚本
配置到PATH ,直接调用脚本
或
绝对路径
③如果脚步在特定的机器,需要指定特定机器的executor,使用 useExecutor=executorID
④在执行脚本时,如果希望传入参数,可以在命令后,使用${参数名},设置占位符,如果设置了占位符,必须需要传入参数,如果无需传参,只能使用传入空参数的方式。
制作脚本时:
①如果使用了SFTP工具,注意字符集,选择UTF-8无BOM
②将sql中 ` 全部删除
③将 str_to_map, split等函数中,分隔符为 \ \ 的,转换为 \ \ \
配置说明
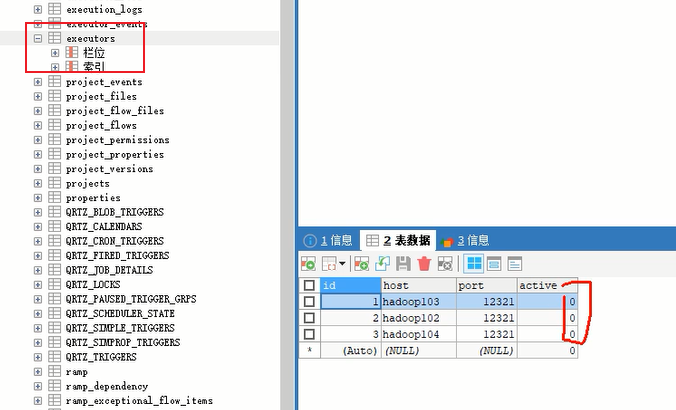
executor 查看激活状态
executor选择机制配置
/opt/module/azkaban/**azkaban-web**/conf/azkaban.properties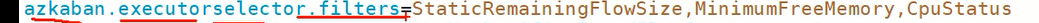
azkaban.executorselector.filters: 当有多个Executor同时启动的时候,需要从中选择一个Executor去执行任务,这里设置一组过滤器的种类,不满足要求的Executor就不会被分配任务
StaticRemainingFlowSize:正在排队的任务数,工作流越多,就越不可能被选上;
#CpuStatus:CPU占用情况,cpu占用月多越不可能被选上
#MinimumFreeMemory:最小剩余内存。测试环境,必须将MinimumFreeMemory删除掉,否则它会认为集群资源不够,不执行,**配置了的话,默认最小剩余内存为8个G,我们每个虚拟机内存为4G,不够**。

若有收获,就点个赞吧
0 人点赞
