💉系统内置函数
1)查看系统自带的函数
show functions;show functions like '*concat*';
2)显示自带的函数的用法
hive> desc function upper;
3)详细显示自带的函数的用法
hive> desc function extended upper;
🩸空字段赋值
🧬NVL:
给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。
主要作用:为空值的表格赋值为0
查询:如果员工的comm为NULL,则用-1代替
hive (default)> select comm,nvl(comm, -1) from emp;
OK
comm _c1
NULL -1.0
300.0 300.0
500.0 500.0
NULL -1.0
1400.0 1400.0
NULL -1.0
NULL -1.0
4)查询:如果员工的comm为NULL,则用领导id代替
hive (default)> select comm, nvl(comm,mgr) from emp;
OK
comm _c1
NULL 7902.0
300.0 300.0
500.0 500.0
NULL 7839.0
1400.0 1400.0
NULL 7839.0
NULL 7839.0
NULL 7566.0
NULL NULL
0.0 0.0
NULL 7788.0
NULL 7698.0
NULL 7566.0
NULL 7782.0
🧬coalesce 函数
处理多行的NVL,如果前一列不为空则看下一列看是否为空,如果为空,则赋值为指定值,如果不为空,则赋值最后一列的值
🩸字符串相关函数
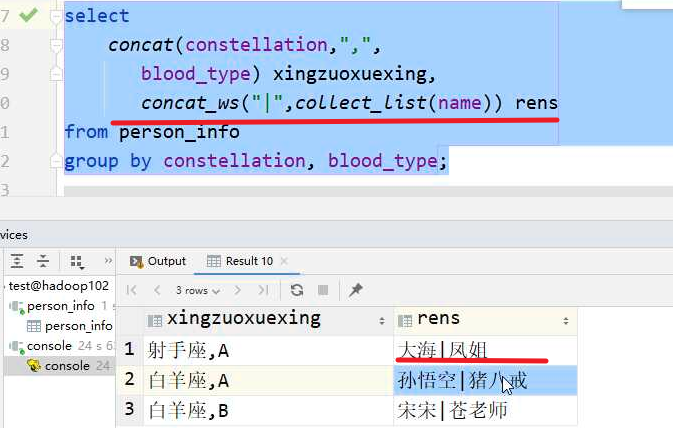
🧬concat
🧬concat_wc
concat_ws:拼接任意集合、字符,
隐含作用:将集合拆成字符串,并且可以去除null值concat_wc('|',**[**{a},{b},{c},null**]**) ==>{a}|{b}|{c}
深入应用请看str_to_map
 —>
—>
🧬substring(field,n,m)
🧬get_json_object函数使用
作用: 从一个json串中抽取 指定path下的 json str
核心: path怎么写?
$: 根json 对象
.: 子元素操作符
[]: 数组子元素操作符
* : 通配符
举例:
--取47 $ [] . *-- path 不存在的,返回null , 传入的不是JSON字符串,也返回nullselect get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]', '$[1].age');--取47 { [{},{age:47}] }select get_json_object('{"husbud":[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]}','$.husbud[1].age');-- 取iPhone Xselect get_json_object('{"common":{"ar":"110000","ba":"iPhone","ch":"Appstore","is_new":"0","md":"iPhone X","mid":"mid_215806","os":"iOS 13.2.3","uid":"335","vc":"v2.1.134"},"displays":[{"display_type":"query","item":"11","item_type":"sku_id","order":1,"pos_id":4},{"display_type":"query","item":"27","item_type":"sku_id","order":2,"pos_id":3},{"display_type":"promotion","item":"16","item_type":"sku_id","order":3,"pos_id":1},{"display_type":"query","item":"9","item_type":"sku_id","order":4,"pos_id":4},{"display_type":"query","item":"26","item_type":"sku_id","order":5,"pos_id":1},{"display_type":"promotion","item":"31","item_type":"sku_id","order":6,"pos_id":2}],"page":{"during_time":14537,"item":"32",' ||'"item_type":"sku_id","last_page_id":"good_list","page_id":"good_detail","source_type":"promotion"},' ||'"ts":1623134229000}','$.common.md')
🧬str_to_map
将字符串封装成map
例子:
str_to_map(concat_ws(',',collect_list(concat(order_status,':',operate_time))))
map_keys
取出map的key
concat_ws('|',map_keys(str_to_map( concat_ws('|',collect_list(brand)),'\\|')))
🩸行列函数
特别地:
聚合函数可以不跟group by 一起用
这样的聚合就是统计整张表的结果:
select count(*)from (select user_id, max(age) agefrom user_agegroup by user_id) t1
统计前: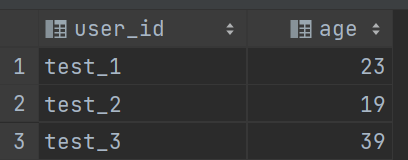
统计后: 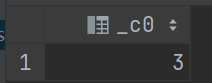
1)求总行数(count)
count(字段名)不统计包括null值的行
count()统计包括null值的行
count(任意数,字包括0)效果和count()一样,计数值为行数
count(null)计数值为0
hive (default)> select count(*) cnt from emp;
2)求工资的最大值(max)
hive (default)> select max(sal) max_sal from emp;
3)求工资的最小值(min)
hive (default)> select min(sal) min_sal from emp;
4)求工资的总和(sum)
统计包括null值的行,null值为0(和不包括null效果一致)
hive (default)> select sum(sal) sum_sal from emp;
5)求工资的平均值(avg)
统计不包括null值,因为分母不能为0;
hive (default)> select avg(sal) avg_sal from emp;
🩹行转列(UDAF)
| name | constellation | blood_type |
|---|---|---|
| 孙悟空 | 白羊座 | A |
| 大海 | 射手座 | A |
| 宋宋 | 白羊座 | B |
| 猪八戒 | 白羊座 | A |
| 凤姐 | 射手座 | A |
| 苍老师 | 白羊座 | B |
🧬collect_list/collect_set
行转列,将多行数据用list或set封装,转化为一行数据,list不去重,set去重
需要结合group by使用
但是也能通过collect_list(xx)[0]等加上下标来选择输出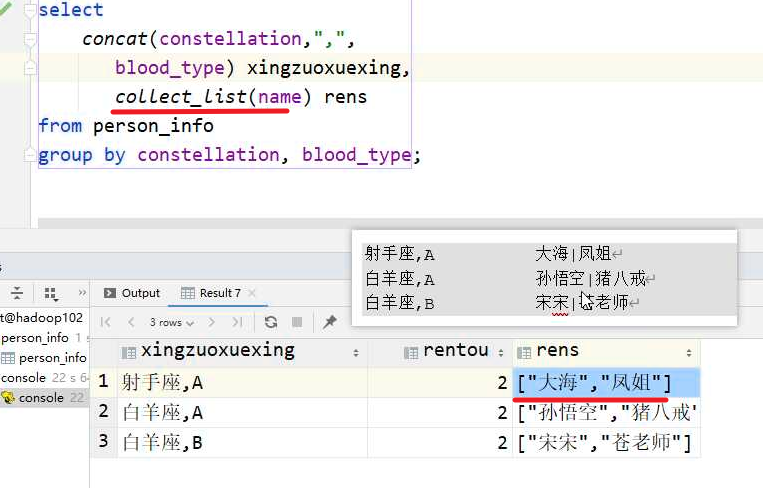
🩹列转行(UDTF)
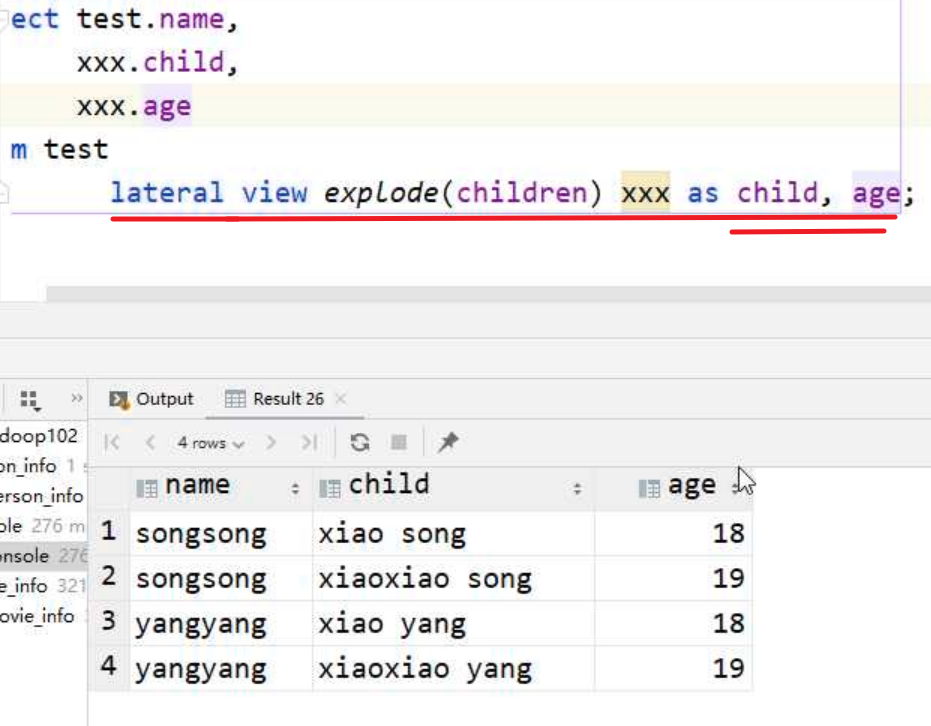
🧬语法
| select
baseTable.col,
(,columnAlias)
`FROM baseTable LATERAL VIEW udtf(expression) tableAlias AS (,columnAlias)`
—-
select
baseTable.col,
(,columnAlias)
`FROM baseTable LATERAL VIEW OUTER udtf(expression) tableAlias AS (,columnAlias)`
*这个outer的作用是在UDTF转换列的时候将其中的空也给展示出来,UDTF默认是忽略输出空的,加上outer之后,会将空也输出,显示为NULL。这个功能是在Hive0.12是开始支持的。
|
| —- |
🧬split
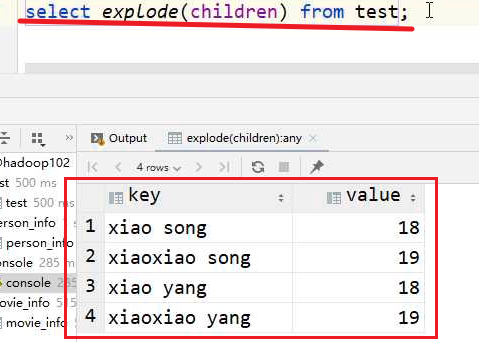
🧬explode,
将数组炸开为不同行,
1.对象可以是数组可以是map
explode(ARRAY) 列表中的每个元素生成一行
explode(MAP) map中每个key-value对,生成一行,key为一列,value为一列
2.限制
1、No other expressions are allowed in SELECT
SELECT pageid, explode(adid_list) AS myCol... is not supported
2、UDTF’s can’t be nested
SELECT explode(explode(adid_list)) AS myCol... is not supported
3、GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY is not supported
SELECT explode(adid_list) AS myCol ... GROUP BY myCol is not supported
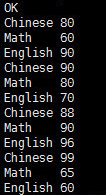
3、示例
select explode(score) from student_score;select explode(score) as (key,value) from student_score;
🧬lateral view
FROM baseTabel``lateral view udtf(expression) tableAlias as columnAlias : 相当于用udtf临时表与 原表进行join,会产生笛卡尔积
- lateral view是Hive中提供给UDTF的结合,它可以解决UDTF不能添加额外的select列的问题。
[x] lateral view会将UDTF生成的结果放到一个虚拟表中,然后这个虚拟表会和输入行进行join来达到连接UDTF外的select字段的目的。
侧写前:<br />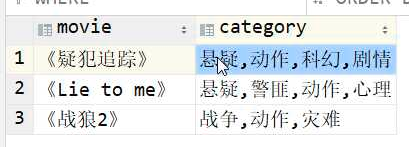<br />侧写后:
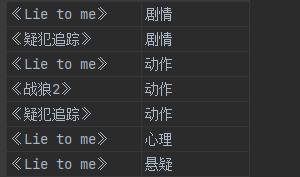
对于map:
explode可以將map的鍵和值打散分開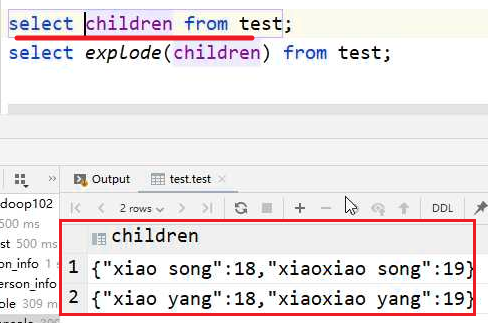
🩹缩列
🧬name_struct
name_struct(名字1,值1,名字2,值2,名字3,值3)==> [{名字1,值1},{名字2,值2},{名字3,值3}]
主要将列数据转换为一列来显示
🩸CASE WHEN (UDF)
格式:
case xx(可省略) when xxx then xxx else xxx end
| —匹配模式:
case 列
when 值1 then xxx
….
when 值N then xxx
else xxxx
end
—示例
SELECT
user_id ,
case user_id
when 1 then ‘1号’
WHEN 2 then ‘2号’
else ‘其他’
END
from ods_coupon_use
limit 10
—判斷模式,相当于加强版if
case
when 条件判断1 then xxx
….
when 条件判断2 then xxx
else xxxx
end
—示例
SELECT
user_id ,
case when user_id = 1 then ‘1号’
WHEN user_id =2 then ‘2号’
else ‘其他’
END
from ods_coupon_use
limit 10 |
| —- |
一般用在聚合函数中
1)数据准备
| name | dept_id | sex |
|---|---|---|
| 悟空 | A | 男 |
| 大海 | A | 男 |
| 宋宋 | B | 男 |
| 凤姐 | A | 女 |
| 婷姐 | B | 女 |
| 婷婷 | B | 女 |
2)需求
求出不同部门男女各多少人。结果如下:
dept_Id 男 女
A 2 1
B 1 2
3)创建本地emp_sex.txt,导入数据
[atguigu@hadoop102 datas]$ vi emp_sex.txt
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 B 女
婷婷 B 女
4)创建hive表并导入数据
create table emp_sex(name string,dept_id string,sex string)row format delimited fields terminated by "\t";load data local inpath '/opt/module/hive/datas/emp_sex.txt' into table emp_sex;
**5
selectdept_id,sum(case sex when '男' then 1 else 0 end) male_count,sum(case sex when '女' then 1 else 0 end) female_countfromemp_sexgroup bydept_id;
count要计算0需要count(null),
count(0)效果和count(1)一致
selectdept_id,count(case sex when '男' then 1 else null end) male_count,count(case sex when '女' then 1 else null end) female_countfromemp_sexgroup bydept_id;
🩸窗口函数over
细节:
窗口函数一般用where进行赛选过滤而不是limit,
如rank函数有人并列第10名,则出来的结果是11个人,但是用limit的话则出来的是10人。
理解:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
语法: 函数() over( partition by 分组 order by 排序 [window子句(定义函数运算的范围)] )
| window子句语法: (ROWS | RANGE) BETWEEN 上边界 AND 下边界 上边界: **(UNBOUNDED | [num]) PRECEDING**下边界: **[num] PRECEDING** | **CURRENT ROW** | ** (UNBOUNDED | [num]) FOLLOWING** |
|---|
哪些函数可以开窗:
①标准的聚合函数:SUM,MIN,MAX,AVG,COUNT
②特定的函数:
LEAD: 取窗口中指定列,当前列之后N列的值
LAG: 取窗口中指定列,当前列之前N列的值
FIRST_VALUE: 传入两个参数,第一个是列名,第二个默认为FLASE,如果为true,代表自动跳过NULL值。 取窗口中 的指定列第一行的值。
LAST_VALUE: 传入两个参数,第一个是列名,第二个默认为FLASE,如果为true,代表自动跳过NULL值 取窗口中指定列 的最后一行的值。
③排名函数(不支持使用window句子)
- RANK- ROW_NUMBER- DENSE_RANK- CUME_DIST- PERCENT_RANK- NTILE
优劣!:
优势:效率比group by 高
劣势:①group by 后能过滤,窗口不能过滤,无论having、where
②不能像group by 那样连续group,如果连续partiton by 那么因为窗口不可闭性,会产生重复数据 :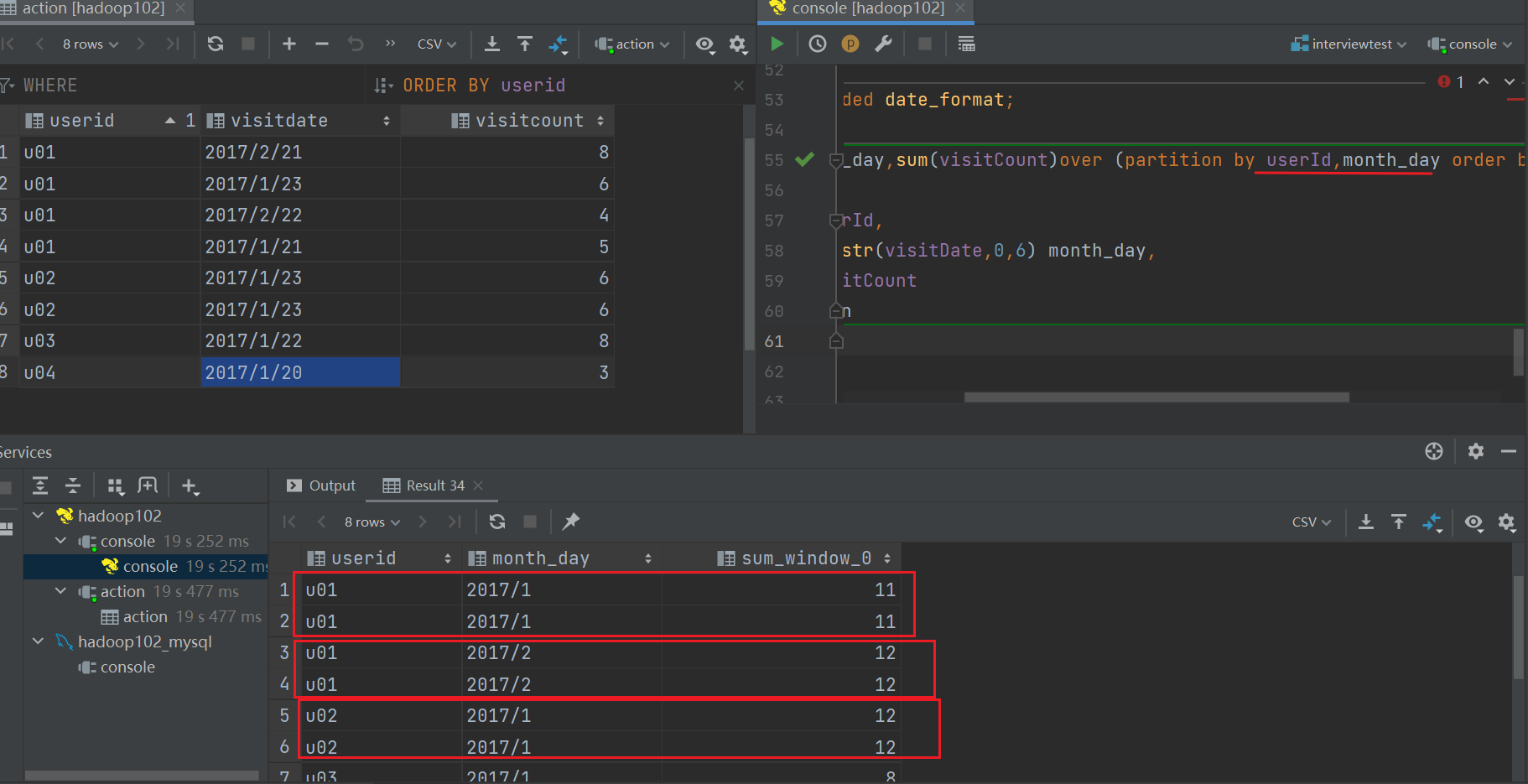
关于窗口函数的partition by , order by:
记忆即可
形式1:
partition by xx order by yy // partition by 后 和order by 后不相同
形式2:
partition by zz order by zz // partition by 后 和order by 后相同或者不加orderpartition by zz // 效果和上面一致
形式1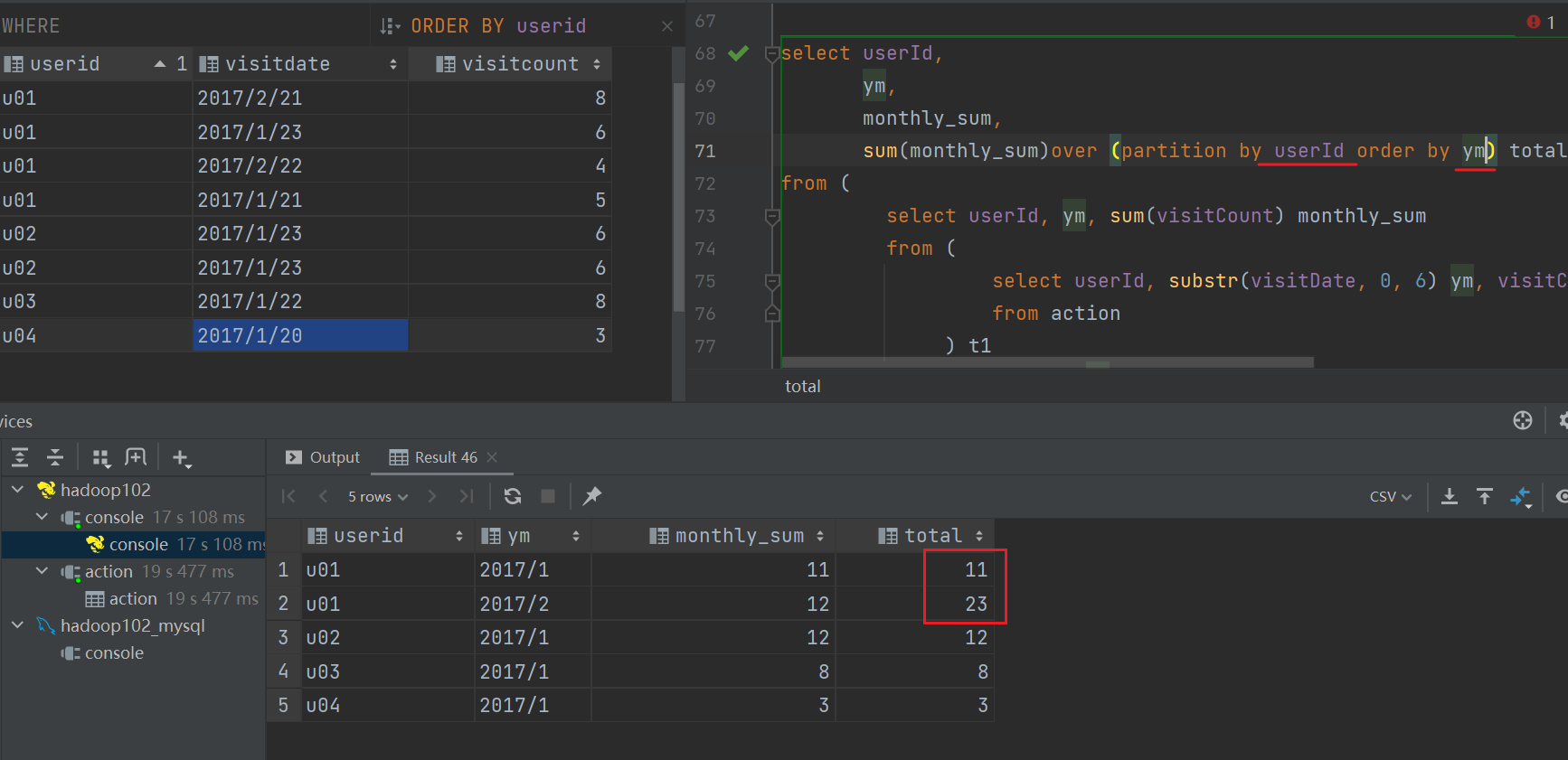
形式2
解釋:
因為order by 如果也和 partition by 相同的話
因為order by的值是相同的,所以無法排序,聚合結果都是以最終結果來確定。
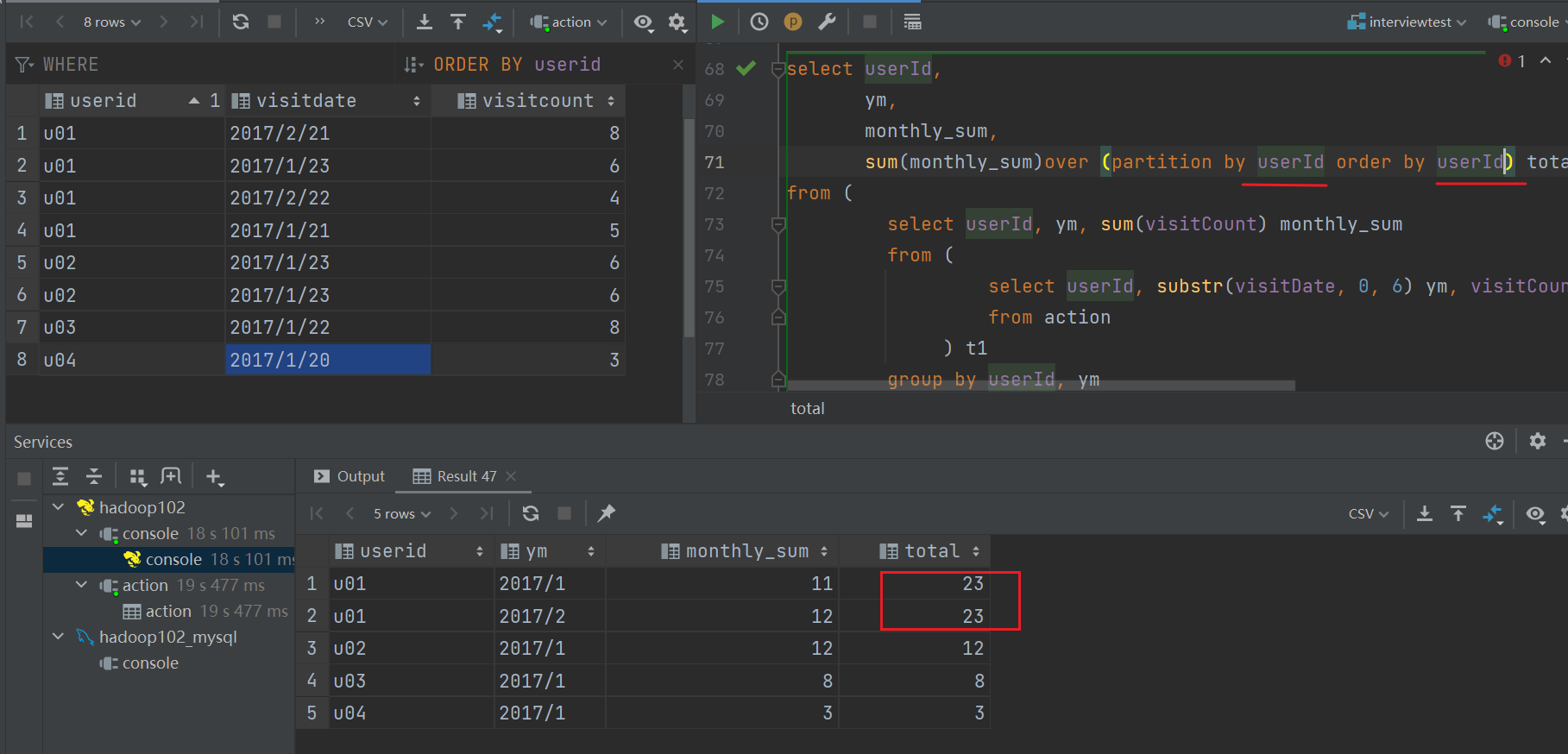
注:和distribution by 、sort by 效果一样,但原理不一样(一般不用)
partition by 是在reduce分区后的分组,将相同的元素进行分组
distribution by 则是分区,如果用在窗口函数就是对每个元素进行分区
🧬FIRST_VALUE (col,true/false):
🧬LAST_VALUE (col,true/false):
🧬LAG(col,n,default_val):
往上第n行数据,结合窗口函数使用且,必须有序
default_val 是第一个值,不设置则为null
select id,ts,lag(ts,1,ts) over(partition by id order by ts) as last_tsfrom grp
🧬LEAD(col,n, default_val):
往下第n行数据,结合窗口函数使用且,必须有序
(4)查询顾客购买明细以及上次的购买时间和下次购买时间
selectname,orderdate,cost,lag(orderdate,1,'1970-01-01') over(PARTITION by name order by orderdate) prev_time,lead(orderdate,1,'1970-01-01') over(PARTITION by name order by orderdate) next_timefrom business;
(5)查询顾客每个月第一次的购买时间 和 每个月的最后一次购买时间
selectname,orderdate,cost,FIRST_VALUE(orderdate) over(partition by name,month(orderdate) order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) first_time,LAST_VALUE(orderdate) over(partition by name,month(orderdate) order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) last_timefrom business;
🧬NTILE(n):
把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型
(5)查询前20%时间的订单信息(100/5=20,所以ntile(5))
select * from (select name,orderdate,cost, ntile(5) over(order by orderdate) sortedfrom business) twhere sorted = 1;
🩹排名窗口函数:
🧬rank
相同排名,下一个排名数值不连续
🧬row numb
按行排序
🧬dense_rank
相同排名,下一个排名数值连续
select name,subject,score,rank() over(partition by subject order by score desc) r,dense_rank() over(partition by subject order by score desc) dr,row_number() over(partition by subject order by score desc) rmfrom score;name subject score r dr rm孙悟空 数学 95 1 1 1宋宋 数学 86 2 2 2婷婷 数学 85 3 3 3大海 数学 56 4 4 4宋宋 英语 84 1 1 1大海 英语 84 1 1 2婷婷 英语 78 3 2 3孙悟空 英语 68 4 3 4大海 语文 94 1 1 1孙悟空 语文 87 2 2 2婷婷 语文 65 3 3 3宋宋 语文 64 4 4 4
🧬percent_rank
插排排名占前百分之几
这个函数是有后会有误差,需要在上面拼接一行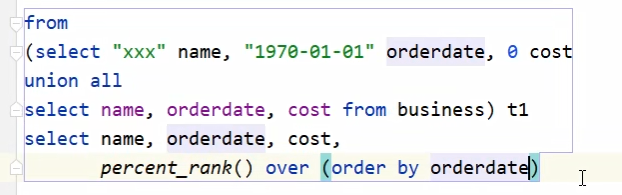
拼接前: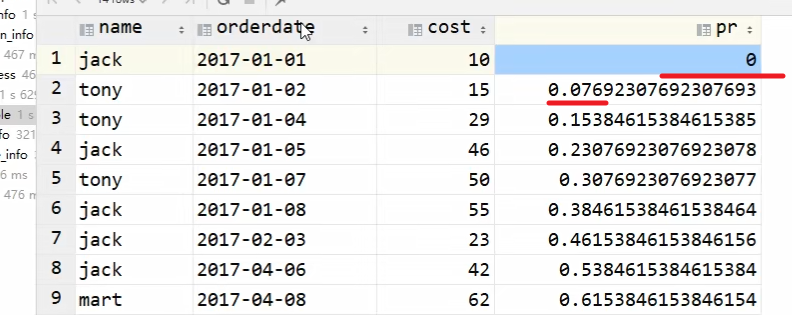
拼接后: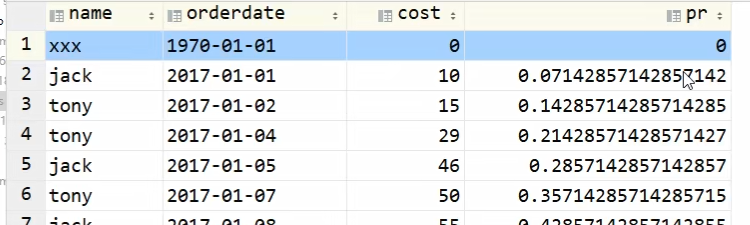
select name,subject,score,rank() over(partition by subject order by score desc) r,dense_rank() over(partition by subject order by score desc) dr,row_number() over(partition by subject order by score desc) rmfrom score;name subject score r dr rm孙悟空 数学 95 1 1 1宋宋 数学 86 2 2 2婷婷 数学 85 3 3 3大海 数学 56 4 4 4宋宋 英语 84 1 1 1大海 英语 84 1 1 2婷婷 英语 78 3 2 3孙悟空 英语 68 4 3 4大海 语文 94 1 1 1孙悟空 语文 87 2 2 2婷婷 语文 65 3 3 3宋宋 语文 64 4 4 4
示例
数据准备:
name,orderdate,costjack,2017-01-01,10tony,2017-01-02,15jack,2017-02-03,23tony,2017-01-04,29jack,2017-01-05,46jack,2017-04-06,42tony,2017-01-07,50jack,2017-01-08,55mart,2017-04-08,62mart,2017-04-09,68neil,2017-05-10,12mart,2017-04-11,75neil,2017-06-12,80mart,2017-04-13,94
需求
(1)查询在2017年4月份购买过的顾客及总人数
(2)查询顾客的购买明细及月购买总额
(3)上述的场景, 将每个顾客的cost按照日期进行累加
(4)查询每个顾客上次的购买时间
(5)查询前20%时间的订单信息
创建本地business.txt,导入数据
[atguigu@hadoop102 datas]$ vi business.txt
创建hive表并导入数据
create table business(name string,orderdate string,cost int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';load data local inpath "/opt/module/datas/business.txt" into table business;
按需求查询数据
(1)查询在2017年4月份购买过的顾客及总人数
select name,count(*) over ()from businesswhere substring(orderdate,1,7) = '2017-04'group by name;
(2)查询顾客的购买明细及月购买总额
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
(3)上述的场景,将每个顾客的cost按照日期进行累加
select name,orderdate,cost,sum(cost) over() as sample1,--所有行相加 !!!!!!!!!sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and 1 PRECEDING) as sample8, --上无边界到前一行sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行from business;
🩸日期相关函数
🧬current_date
返回当前日期
select current_date();
🧬date_add, date_sub
日期的加减
—今天开始90天以后的日期
用负数效果和date_sub一致
select date_add(current_date(), 90);=select date_sub(current_date(), -90);
—今天开始90天以前的日期
select date_sub(current_date(), 90);=select date_add(current_date(), -90);
🧬datediff
两个日期之间的日期差
—今天和1990年6月4日的天数差,把括号内的内容看成区间即可
1990-06-04-current_date()
SELECT datediff(CURRENT_DATE(), "1990-06-04");
🧬data_format
修改日期格式
data_format(CURRENT_DATE,"yy-MM-dd")//只能识别‘-’这种格式 -_-|||
🧬year,month,day
年月日:将一个日期转化为单独的年月日
year()
month()
day()
select s_name,s_birth,(year(CURRENT_DATE)-year(s_birth)-(case when month(CURRENT_DATE) < month(s_birth) then 1when month(CURRENT_DATE) = month(s_birth) and day(CURRENT_DATE) < day(s_birth) then 1else 0 end)) as agefrom student;
next_day
取:自今天开始的下一个星期n,一般配合date_sub使用,来获取上星期数据:
date_sub(next_day('2021-06-08','Monday'),7)
🩸杂七杂八函数
🧬with—as
| with 临时表名1 as (), 临时表名2 as (), 临时表名3 as () xxx语句 |
|---|
💉自定义函数
1)Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2)当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出
如lateral view explore()
4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
5)编程步骤:
(1)继承org.apache.hadoop.hive.ql.exec.UDF
(2)需要实现evaluate函数;evaluate函数支持重载;
(3)在hive的命令行窗口创建函数
添加jar
add jarlinux_jar_path
创建function
create [temporary] function [dbname.]function_name AS class_name;
(4)在hive的命令行窗口删除函数
Drop [temporary] function [if exists] [dbname.]function_name;
6)注意事项:UDF必须要有返回类型,可以返回null,但是返回类型不能为void;
自定义UDF函数
1)创建一个Maven工程Hive
2)导入依赖
<dependencies><!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency></dependencies>
3)创建一个类
这里的evaluate单词是写死的,不能有变
需要继承新的UDF:GenericUDF
package com.atguigu.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}
导入函数jar包
方法一:
1.打成jar包上传到服务器/opt/module/jars/udf.jar,后重启hiveservices.sh
2.将jar包添加到hive的classpath
hive (default)> add jar /opt/module/datas/udf.jar;
方法二:
1.直接添加文件到 hive/lib目录中,后重启hiveservices.sh
或者(hive根目录创建文件夹auxlib, 上传函数的jar包到 $HIVE_HOME/auxlib 目录,重启hive)
2.不需要添加到classpath
方法三:
或上传到hdfs:实际使用更多上传到hdfs中。
将Jar包添加为函数
创建临时函数与开发好的java class关联
hive (default)> create temporary function mylower as "com.atguigu.hive.Lower";
或者:
hive (default)> create function explode_json_array as 'hive_func.ExplodeJson';
如果是上传到hdfs,则:(客户端访问hdfs端口:8020)
调用函数:
即可在hql中使用自定义的函数strip
hive (default)> select ename, mylower(ename) lowername from emp;
注意事项
— 严重的注意事项 hive内置的函数可以在任意库下使用,自定义的函数,只能在定义的库下使用,如果要跨库,必须加库名
CREATE function explode_jsonarray as 'com.atguigu.hive.functions.ExplodeJsonArray';
desc function gmall.explode_jsonarray

若有收获,就点个赞吧
0 人点赞
