
自动提交offsets
kafka消费者配置Mapxx,xx
在设置了latest模式消费
且设置自动提交offsets,那么很容易出现数据丢失的情况
原理:
首先sparkstreaming消费数据是按批次处理的,
自动提交一个批次的数据,是无论那批次数据是否发生异常,都会进行offset的提交
此时重新消费数据的时候从latest消费的话,就会消费不到之前异常数批次据数据中一部分数据
sparkstreaming消费kafka的3种保存offsets来处理语义
checkpoint保存offsets
已经消费数据(保存到数据库)
但是offsets却没被保存
下次消费还会读取之前的offsets
此时造成数据重复
所以只能做到 at least one

kafka itself
这种情况先把自动模式关闭
之后实现代码逻辑
再手动提交
此时如果代码逻辑异常,手动提交的代码就不会执行
如果此时执行的是幂等操作,那么就能实现eaxctly once 的操作,例如flume,mysql都中有事务,可以实现精准一次(下面有实现)
而打印在控制台明显不是幂等操作
使用自己的数据库
使用事务来保证幂等性
当offset、数据两者同时写入才算写入,否则回滚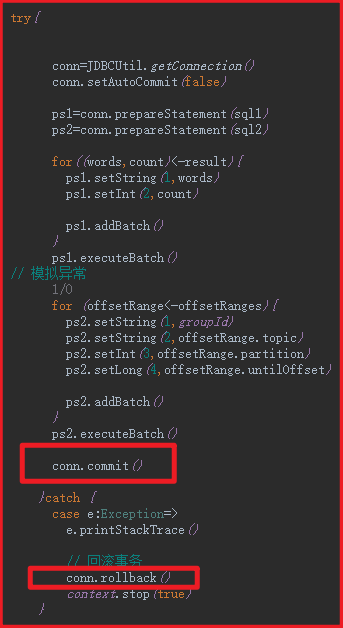
总结:
1、如果想要保证精准一次消费,那么需要借助外部带有事务的存储设备,例如mysql
从spark从kafka消费数据后,将数据以及offset一同存放进mysql,如果两者都成功,才算成功,否则回滚
2、如果offset只存放到kafka中,且设置手动提交,那么当某批次数据发生异常,offset是无法提交的,但是已经消费到数据库中,若宕机,再次消费会造成 at least once重复消费
3、checkpiont
和存放在kafka中一样,而且会产生很多小文件

若有收获,就点个赞吧
0 人点赞
