SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;
Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
对于开发人员来讲,SparkSQL可以简化RDD的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是Spark SQL。
Spark SQL为了简化RDD的开发,提高开发效率,提供了2个编程抽象,类似Spark Core中的RDD
- DataFrame
- DataSet
读取文件
注意:
如果从内存中获取数据,spark可以知道数据类型具体是什么。如果是数字,默认作为Int处理;
但是从文件中读取的数字,不能确定是什么类型,所以用bigint接收,可以和Long类型转换,但是和Int不能进行转换
scala> val df = spark.read.json("data/user.json")df: org.apache.spark.sql.DataFrame = [age: bigint,username: string]
创建会话
Core: SparkContext
SparkContext.xxx 创建RDD
Sql: SparkSession.xxx 创建DF或DS
如何创建SparkSessoin:
* ①如果已经创建过了SparkSession,可以通过SparkSession.builder().getOrCreate()获取已经存在的SparkSession
* ② SparkSession.builder.xxxx.xxx.xxxx.getOrCreate() 创建一个新的SparkSession
// sparkSession 和 session 共用同一个SparkContext
_session.read.格式,及_session.sql(“xxxx”)
//在每个测试方法之前运行@Beforedef init(): Unit ={session = SparkSession.builder.master("local[4]").appName("Word Count")//.config("spark.some.config.option", "some-value") //添加spark的参数.getOrCreate()}//在每个测试方法之后运行@Afterdef close(): Unit ={session.close()}
@Testdef testCreateDF1() : Unit ={//如果从内存中获取数据,spark可以知道数据类型具体是什么。如果是数字,默认作为Int处理;//但是从文件中读取的数字,不能确定是什么类型,所以用bigint接收,可以和Long类型转换,但是和Int不能进行转换val dataFrame: DataFrame = session.read.json("input/people.json")//查看dataFrame.show()//只查看schamedataFrame.printSchema()// 使用sql分析//为当前的表格起名dataFrame.createTempView("person")session.sql("select avg(age) from person where age > 20").show()}
创建视图
将数据映射为一张表
@Testdef testGlobalView() : Unit ={val dataFrame1: DataFrame = session.read.json("input/people.json")//创建为全局视图dataFrame1.createOrReplaceGlobalTempView("person")val sparkSession: SparkSession = session.newSession()//访问全局视图,添加global_temp名称空间,类似于库名.表名sparkSession.sql("select avg(age) from global_temp.person where age > 20").show()}/*一个表格可以有多个视图名Temporary view 'person' already exists;在一个session中,同一个视图名只能指向唯一表格!默认创建的视图,不能跨越Session的,如果希望跨session操作,必须是全局视图!*/@Testdef testCreateTempViewDifference() : Unit ={val dataFrame1: DataFrame = session.read.json("input/people.json")val dataFrame2: DataFrame = session.read.json("input/people1.json")dataFrame1.createTempView("person")//dataFrame2.createTempView("person") 报错//存在就替换,不存在就创建dataFrame2.createOrReplaceTempView("person")println("----------------")// sparkSession 和 session 共用同一个SparkContext// session还能分裂出多一个sparkSessionval sparkSession: SparkSession = session.newSession()println(sparkSession.sparkContext == session.sparkContext)val dataFrame3: DataFrame = sparkSession.read.json("input/people1.json")dataFrame3.createTempView("person")sparkSession.sql("select avg(age) from person where age > 20").show()}
创建DataFrame
/
* 基于集合创建DF
DataFrame=RDD(数据)+schema(元数据)
RDD:
def createDataFrame(rows: java.util.List[Row], schema: StructType)
Row: 代表关系型运算中的一行输出。
构造: Row(x,x,x,x)
类比为数组,通过索引定位元素
获取元素: Row(index) 返回Any(没有类型)
Row.getXxx(index) 返回带类型的数据
弱类型!
schema:
StructType: 表的结构 样例类,apply方法:StructType() 参数是一个StructField的list或array
StructField(schema): 表中的字段,样例类,apply方法:StructField()
DataType: 字段的数据类型
是什么类型,就使用什么样的case object
例如: StringType、IntegerType…
*/
// 通过Row类型创建DF@Testdef testCreateDF2() : Unit ={//将row数据添加到数组中var datas:java.util.List[Row]=new util.ArrayList[Row]();datas.add(Row("jack",20))datas.add(Row("jack1",30))datas.add(Row("jack2",40))// 表结构var schema: StructType=StructType( StructField("name",StringType) :: StructField("age",IntegerType) :: Nil)val df: DataFrame = session.createDataFrame(datas, schema)df.show()df.printSchema()}
Row补充:
创建Row的两种方式
直接传值
* Row(value1, value2, value3, …)
传进集合:
* Row.fromSeq(Seq(value1, value2, …))
特性
Row(a,b,c,d)
可以通过索引获取:Row(2):Any=c
但是通过下标获取的的值类型是Any,是不确定类型的,所以Row是弱类型数据,需要强转
Row提供了转换方法(明确知道index是什么类型的时候使用!!)_row.getXxx(index):_
val firstValue = row.getInt(0)*// firstValue: Int = 1val isNull = row.isNullAt(3)*// isNull: Boolean = true
创建DataSet
/*
DS 和DS的区别:
DS[T]
DF : Dataset[Row]
泛型上下文:
def createDatasetT : Encoder: Dataset[T]
等价于
def createDatasetEncoder(implicit aa:Encoder[T])
** 重要**:** Encoder**: ①可以直接通过SparkSession中的一些隐式方法,隐式创建Encoder.<br /> 不用你创建,它偷偷给你创建,你看不见<br /> `import sparksession对象.implicits._`<br /> 隐式类import后面的类名必须是用val修饰,因为Scala只支持val修饰的对象的引入。②可以显式调用Encoders的静态方法创建<br /> 1)scala中的基本数据类型: `Encoders.scalaXxx`<br /> 2)scala的String : `Encoders.STRING`<br /> 3)自己定义的类:<br /> 3.1)样例类: ` ExpressionEncoder[T]()` 或 ` Encoders.product[T]`<br /> 因为所有样例类都实现了Product,Serilizable接口<br /> 3.2)非样例类: ` ExpressionEncoder[T]()`
Row类型RDD调用toDS,无法调用,因为没有继承producer,无法构建Encoder,需要使用以下方法:
val df:DataFrame=session.createDataFrame(rdd,schema)
*/
package com.tcodeimport org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}import org.apache.spark.sql.{DataFrame, Dataset, Encoders, Row, SparkSession}import org.junit.{After, Before, Test}import java.util// 实现了 Product ,Serilizablecase class Emp(name:String,age:Int)class DFAndDSTest {var session:SparkSession = null@Testdef testCreateDS() : Unit ={val emps = List(Emp("jack", 30), Emp("marray", 20))// 隐式类import后面的类名必须是用val修饰,因为Scala只支持val修饰的对象的引入。//import session.implicits._val ds: Dataset[Emp] = session.createDataset(emps)(Encoders.product[Emp])ds.show()ds.printSchema()}//在每个测试方法之前运行@Beforedef init(): Unit ={session = SparkSession.builder.master("local[4]").appName("Word Count")//.config("spark.some.config.option", "some-value") //添加spark的参数.getOrCreate()}//在每个测试方法之后运行@Afterdef close(): Unit ={session.close()}}
DF-DS-RDD转换
总结:
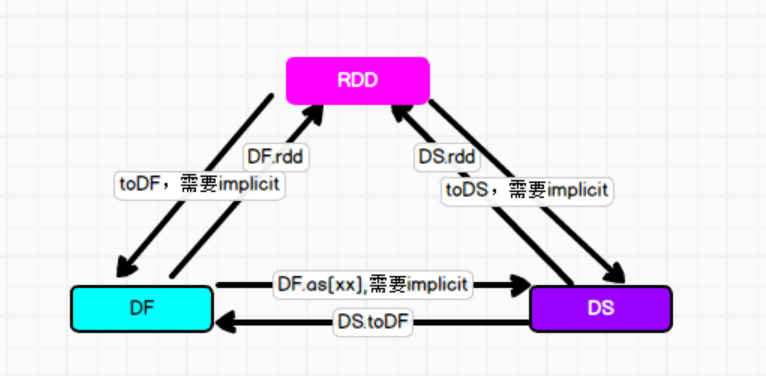
RDD—DF|DS
Row类型RDD调用toDS,无法调用,因为没有继承producer,无法构建Encoder,需要使用以下方法:
val df:DataFrame=session.createDataFrame(rdd,schema)
@Testdef testRDDToDf() : Unit ={val sparkSession: SparkSession = SparkSession.builder.getOrCreate()val list = List(Person("jack", 20), Person("marry", 30))val rdd: RDD[Person] = session.sparkContext.makeRDD(list)// 不导入RDD是没有方法提示的import sparkSession.implicits._//implicit def rddToDatasetHolder[T : Encoder](rdd: RDD[T]): DatasetHolder[T]// rdd: RDD[Person] ----->rddToDatasetHolder(rdd) ----> DatasetHolder[Person] ----------->DatasetHolder[Person].toDF()val df: DataFrame = rdd.toDF()val ds: Dataset[Person] = rdd.toDS()}
DF—DS—RDD
package com.tcodeimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import org.junit.{After, Before, Test}case class Person(name:String,age:Int)/*** Created by VULCAN on 2021/6/5*/class ConversionTest {var session:SparkSession = null/*DF/DS.rdd*/@Testdef testDFToRDD() : Unit ={val sparkSession: SparkSession = SparkSession.builder.getOrCreate()val dataFrame1: DataFrame = session.read.json("input/people.json")// DF转换为rddval rdd: RDD[Row] = dataFrame1.rdd// DF转换DSimport sparkSession.implicits._val ds: Dataset[Person] = dataFrame1.as[Person]// DS转换rddval rdd1: RDD[Person] = ds.rdd}//在每个测试方法之前运行@Beforedef init(): Unit ={session = SparkSession.builder.master("local[4]").appName("Word Count")//.config("spark.some.config.option", "some-value") //添加spark的参数.getOrCreate()}//在每个测试方法之后运行@Afterdef close(): Unit ={session.close()}}
RDD[Row]—DF
val df: DataFrame = session1.implicits.rddToDatasetHolder(rdd2)(ExpressionEncoder[Row]()).toDF()
@Testdef testRowTypeRddToDF() : Unit ={val emps = List(Emp("jack", 30), Emp("marray", 20))val rdd1: RDD[Emp] = session.sparkContext.makeRDD(emps)val rdd2: RDD[Row] = rdd1.map(emp => Row(emp.name, emp.age))val session1: SparkSession = SparkSession.builder.getOrCreate()import session1.implicits._val df: DataFrame = session1.implicits.rddToDatasetHolder(rdd2)(ExpressionEncoder[Row]()).toDF()//rdd2.toDF()// df.show()rdd1.toDF()}
Encoder
重要: Encoder: ①可以直接通过SparkSession中的一些隐式方法,隐式创建Encoder.
不用你创建,它偷偷给你创建,你看不见
import sparksession对象.implicits._
隐式类import后面的类名必须是用val修饰,因为Scala只支持val修饰的对象的引入。
②可以显式调用Encoders的静态方法创建<br /> 1)scala中的基本数据类型: `Encoders.scalaXxx`<br /> 2)scala的String : `Encoders.STRING`<br /> 3)自己定义的类:<br /> 3.1)样例类: ` ExpressionEncoder[T]()` 或 ` Encoders.product[T]`<br /> 因为所有样例类都实现了Product,Serilizable接口<br /> 3.2)非样例类: ` ExpressionEncoder[T]()`
Row类型RDD调用toDS,无法调用,因为没有继承producer,无法构建Encoder,需要使用一下方法:

若有收获,就点个赞吧
0 人点赞
