https://www.jianshu.com/c/88f379f8e9fd
https://github.com/FlowerBoot/blog/tree/c95c8d564608101fe342983a77dd4b5381050d66/_posts/effective
消除过期的对象引用
那么什么时候应该清空一个引用呢?Stack类的哪个方面使它容易受到内存泄漏的影响?简单地说,它管理自己的内存。当一个类自己管理内存时,程序员应该警惕内存泄漏问题。 每当一个元素被释放时,元素中包含的任何对象引用都应该被清除。
另一个常见的内存泄漏来源是缓存。一旦将对象引用放入缓存中,很容易忘记它的存在,并且在它变得无关紧要之后,仍然保留在缓存中。
第三个常见的内存泄漏来源是监听器和其他回调。如果你实现了一个API,其客户端注册回调,但是没有显式地撤销注册回调,除非采取一些操作,否则它们将会累积。确保回调时垃圾收集的一种方法是只存储弱引用(weak references),例如,仅将它们保存在WeakHashMap的键(key)中。
避免使用Finalizer和Cleaner机制
Finalizer和Cleaner机制的一个缺点是不能保证他们能够及时执行[JLS,12.6]。 在一个对象变得无法访问时,到Finalizer和Cleaner机制开始运行时,这期间的时间是任意长的。 这意味着你永远不应该Finalizer和Cleaner机制做任何时间敏感(time-critical)的事情。 例如,依赖于Finalizer和Cleaner机制来关闭文件是严重的错误,因为打开的文件描述符是有限的资源。 如果由于系统迟迟没有运行Finalizer和Cleaner机制而导致许多文件被打开,程序可能会失败,因为它不能再打开文件了。
那么,你应该怎样做呢?为对象封装需要结束的资源(如文件或线程),而不是为该类编写Finalizer和Cleaner机制?让你的类实现AutoCloseable接口即可,并要求客户在在不再需要时调用每个实例close方法,通常使用try-with-resources确保终止,即使面对有异常抛出情况(条目 9)。一个值得一提的细节是实例必须跟踪是否已经关闭:close方法必须记录在对象里不再有效的属性,其他方法必须检查该属性,如果在对象关闭后调用它们,则抛出IllegalStateException异常。
使用try-with-resources语句替代try-finally语句
在处理必须关闭的资源时,使用try-with-resources语句替代try-finally语句。 生成的代码更简洁,更清晰,并且生成的异常更有用。 try-with-resources语句在编写必须关闭资源的代码时会更容易,也不会出错,而使用try-finally语句实际上是不可能的。
当重写equals方法时,同时也要重写hashCode方法
总之,除非必须:在很多情况下,不要重写equals方法,从Object继承的实现完全是你想要的。 如果你确实重写了equals 方法,那么一定要比较这个类的所有重要属性,并且以保护前面equals约定里五个规定的方式去比较。



总之,每次重写equals方法时都必须重写hashCode方法,否则程序将无法正常运行。你的hashCode方法必须遵从Object类指定的常规约定,并且必须执行合理的工作,将不相等的哈希码分配给不相等的实例。
比较compareTo方法的实现中的字段值时,请避免使用”<”和”>”运算符。 相反,使用包装类中的静态compare方法或Comparator接口中的构建方法。
泛型

?和 T的区别
?相对于T来说有很多的限制,比如说: 1. 上面返回的是void,那如果我想传入什么就返回什么,那通配符是做不到的 2. 后面会讲到上界/下面通配符,List配合这两种通配符时,一个不能修改,一个不能读取
但是通配符也有类型参数做不到的: 1. 通配符可以使用?super(即下界通配符)
列表优先于数组
使用限定通配符来增加API的灵活性
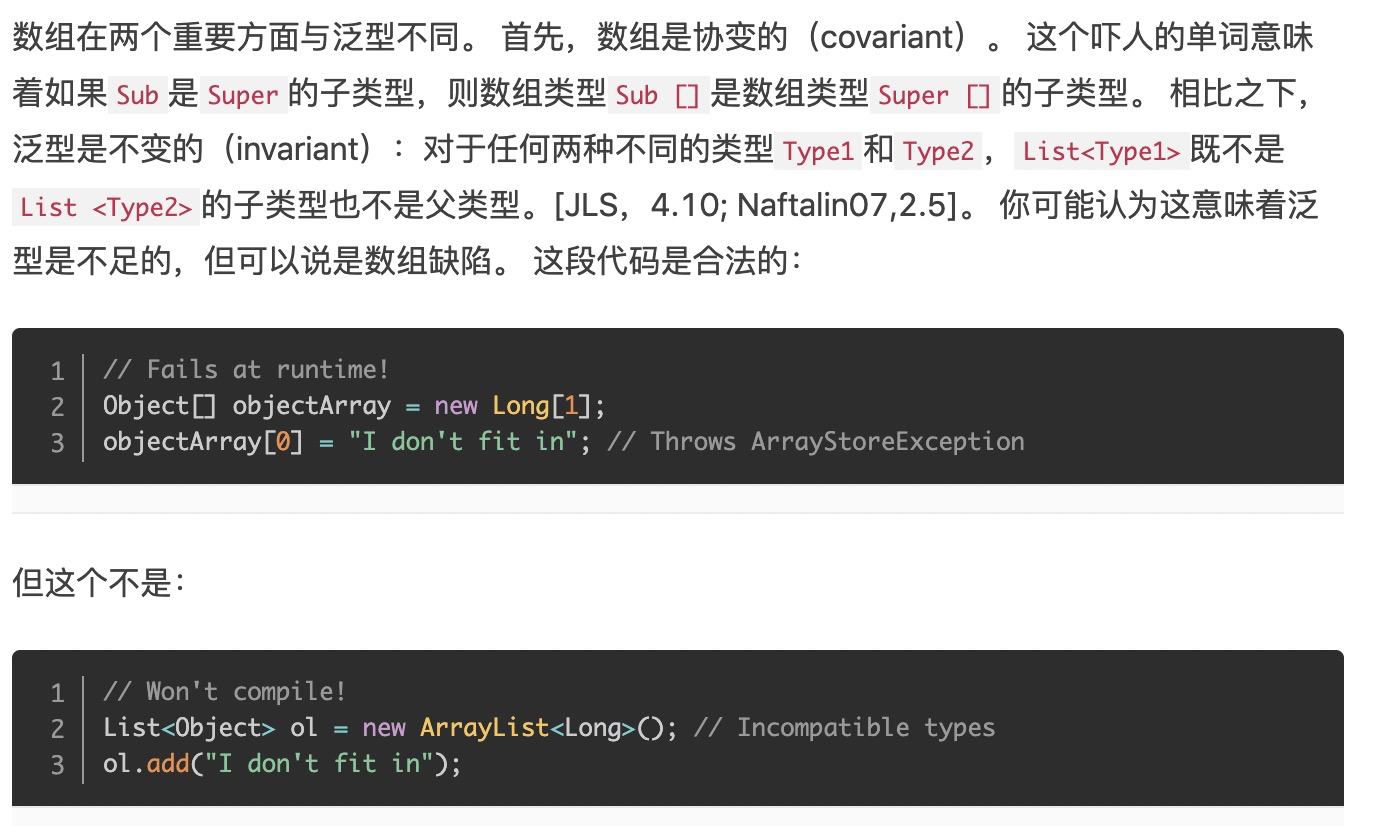
总之,数组和泛型具有非常不同的类型规则。 数组是协变和具体化的; 泛型是不变的,类型擦除的。 因此,数组提供运行时类型的安全性,但不提供编译时类型的安全性,反之亦然。 一般来说,数组和泛型不能很好地混合工作。 如果你发现把它们混合在一起,得到编译时错误或者警告,你的第一个冲动应该是用列表来替换数组。
总之,在你的API中使用通配符类型,虽然棘手,但使得API更加灵活。 如果编写一个将被广泛使用的类库,正确使用通配符类型应该被认为是强制性的。 记住基本规则: producer-extends, consumer-super(PECS)。 还要记住,所有Comparable和Comparator都是消费者。
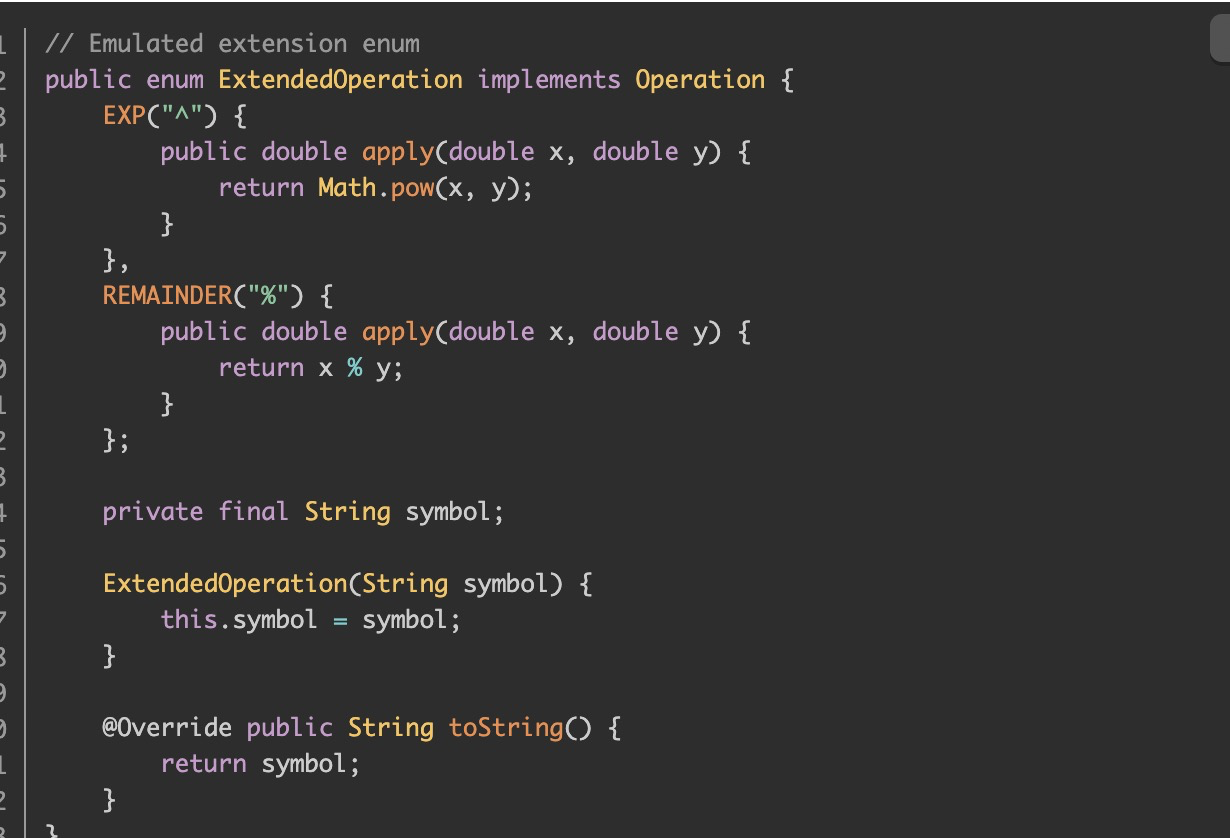
使用接口模拟可扩展的枚举
场景:对加减乘除 枚举,添加 计算方法
明智而审慎地返回Optional
那么什么时候应该声明一个方法来返回Optional <T>而不是T呢?
通常,如果可能无法返回结果,并且在没有返回结果,客户端还必须执行特殊处理的情况下,则应声明返回Optional Optional <T>并非没有成本。 Optional是必须分配和初始化的对象,从Optional中读取值需要额外的迂回。 这使得Optional不适合在某些性能关键的情况下使用。 特定方法是否属于此类别只能通过仔细测量来确定
与返回装箱的基本类型相比,返回包含已装箱基本类型的Optional的代价高得惊人,因为Optional有两个装箱级别,而不是零。因此,类库设计人员认为为基本类型int、long和double提供类似OptionOptionalInt、OptionalLong和OptionalDouble。它们包含Optional<T>上的大多数方法,但不是所有方法。因此,除了“次要基本类型(minor primitive types)”Boolean,Byte,Character,Short和Float之外,永远不应该返回装箱的基本类型的Optional。
总之,如果发现自己编写的方法不能总是返回值,并且认为该方法的用户在每次调用时考虑这种可能性很重要,那么或许应该返回一个Optional的方法。但是,应该意识到,返回Optional会带来实际的性能后果;对于性能关键的方法,最好返回null或抛出异常。最后,除了作为返回值之外,不应该在任何其他地方中使用Optional。
何时使用Lamda表达式
与方法和类不同,lambda没有名称和文档; 如果计算不是自解释的,或者超过几行,则不要将其放入lambda表达式中。 一行代码对于lambda说是理想的,三行代码是合理的最大值。 如果违反这一规定,可能会严重损害程序的可读性。 如果一个lambda很长或很难阅读,要么找到一种方法来简化它或重构你的程序来消除它
匿名类和Lamda表达式的case
何时使用方法引用

序列化
https://jishuin.proginn.com/p/763bfbd24061
何时使用序列化(implements Serializable)
序列化:对象转换为字节序列
反序列化:字节序列转换为对象
使用场景举例
- http接口服务:服务端和客户端交互时(一般我们指定JSON类型传输,实际是字符串类型,而String类已经实现了Serializable)
- 设计到RPC网络传输时
- 内存对象涉及到传输到磁盘或数据库时(自动生成的DO对象一般都实现了Serializable接口)
serialVersionUID的作用是什么,一般如何生成
- 指定一个类序列化的版本号。用于反序列化时和原始类序列化版本号的比较,相等才能反序列化成功。
- 可以任意制定一个值。也可以通过IDE工具生成。
- 如果不指定,JVM会默认生成一个,当类的属性发生变化时,就会导致序列化时和反序列化时版本号不一致,反序列化失败。
并发
你可能昕说过,为了提高性能,在读或写原子数据的时候,应该避免使用同步。这个建议是非常危险而错误的。虽然语言规范保证了线程在读取原子数据的时候,不会看到任意的数值,但是它并不保证一个线程写入的值对于另一个线程将是可见的。 为了在线程之间进行可靠的通信,也为了互斥访问,同步是必要的。 这归因于 Java 语言规范中的内存模型(memory model),它规定了一个线程所做的变化何时以及如何变成对其他线程可见[JLS ,17.4; Goetz06, 16]。
如果对共享的可变数据的访问不能同步,其后果将非常可怕,即使这个变量是原子可读写的。
总而言之,为了避免死锁和数据破坏,千万不要从同步区字段内部调用外来方法。更通俗地讲,要尽量将同步区字段内部的工作量限制到最少。当你在设计一个可变类的时候,要考虑一下它们是否应该自己完成同步操作。在如今这个多核的时代,这比永远不要过度同步来得更重要。只有当你有足够的理由一定要在内部同步类的时候,才应该这么做,同时还应该将这个决定清楚地写到文档中(详见第 82 条) 。
newCachedThreadPool 和 newFixedThreadPool的场景
为特殊的应用程序选择 executor service 是很有技巧的。如果编写的是小程序,或者是轻量负载的服务器,使用 Executors.newCachedThreadPool 通常是个不错的选择,因为它不需要配置,并且一般情况下能够「正确地完成工作」。但是对于大负载的服务器来说,缓存的线程池就不是很好的选择了!在缓存的线程池中,被提交的任务没有排成队列,而是直接交给线程执行。如果没有线程可用,就创建一个新的线程。如果服务器负载得太重,以致它所有的 CPU 都完全被占用了,当有更多的任务时,就会创建更多的线程,这样只会使情况变得更糟。因此,在大负载的产品服务器中,最好使用 Executors.newFixedThreadPool ,它为你提供了一个包含固定线程数目的线程池,或者为了最大限度地控制它,就直接使用 ThreadPoolExecutor 类。
不仅应该尽量不要编写自己的工作队列,而且还应该尽量不直接使用线程。当直接使用线程时, Thread 是既充当工作单元,又是执行机制。在 Executor Framework 中,工作单元和执行机制是分开的。现在关键的抽象是工作单元,称作任务(task) 。任务有两种:Runnable 及其近亲 Callable (它与 Runnable 类似,但它会返回值,并且能够抛出任意的异常)。执行任务的通用机制是 executor service 。如果你从任务的角度来看问题,并让一个 executor service 替你执行任务,在选择适当的执行策略方面就获得了极大的灵活性。本质上,Executor 框架执行的功能与 Collections 框架聚合(aggregation)的功能相同。
并发工具优于 wait 和 notify
同步器(Synchronizer)是使线程能够等待另一个线程的对象,允许它们协调动作。最常用的同步器是 CountDownLatch 和 Semaphore 。较不常用的是 CyclicBarrier 和 Exchanger 。功能最强大的同步器是 Phaser 。

若有收获,就点个赞吧
0 人点赞
