- supervisor节点以及其他excutor的分配是集群启动时分配好的?如果某supervisor挂掉、supervisor里的worker挂掉如何容错的?
supervisor里的worker挂掉的情况:
Supervisor会对本地的Worker进程进行监控,如果发现状态不正常会尝试杀掉Worker并重启,超过一定次数仍为正常会将此Worker任务交还给Nimbus再次进行分配
反压
wangyi 问到
https://www.jianshu.com/p/c7ecd5683226
1.2 Storm 反压机制
Storm反压机制 Storm 在每一个 Bolt 都会有一个监测反压的线程(Backpressure Thread),这个线程一但检测到 Bolt 里的接收队列(recv queue)出现了严重阻塞就会把这个情况写到 ZooKeeper 里,ZooKeeper 会一直被 Spout 监听,监听到有反压的情况就会停止发送。因此,通过这样的方式匹配上下游的发送接收速率。 Storm 提供的最基本的处理 stream 的原语是 spout 和 bolt。 ①spout 是流的源头。 通常 spout 从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,之后发送到Stream中。 ② bolt 处理输入的Stream,并产生新的输出Stream。bolt 可以执行Filter、Map、Join等操作。bolt 是一个被动的 角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
这是不是和“告警引擎里的分发节点 单机分发负载高 时 如何解决” 这一问题类似? 知识要有联想和串联
问题
- 怎么保证监控的稳定性?
分位数算子怎么实现的?
zoom问到
场景:90%的机器cpu小于xxx 则告警
https://lishoubo.github.io/2017/09/20/flink%E5%AE%9E%E6%97%B6%E5%88%86%E6%9E%90%E7%9A%84%E5%87%A0%E7%82%B9%E6%80%BB%E7%BB%93/
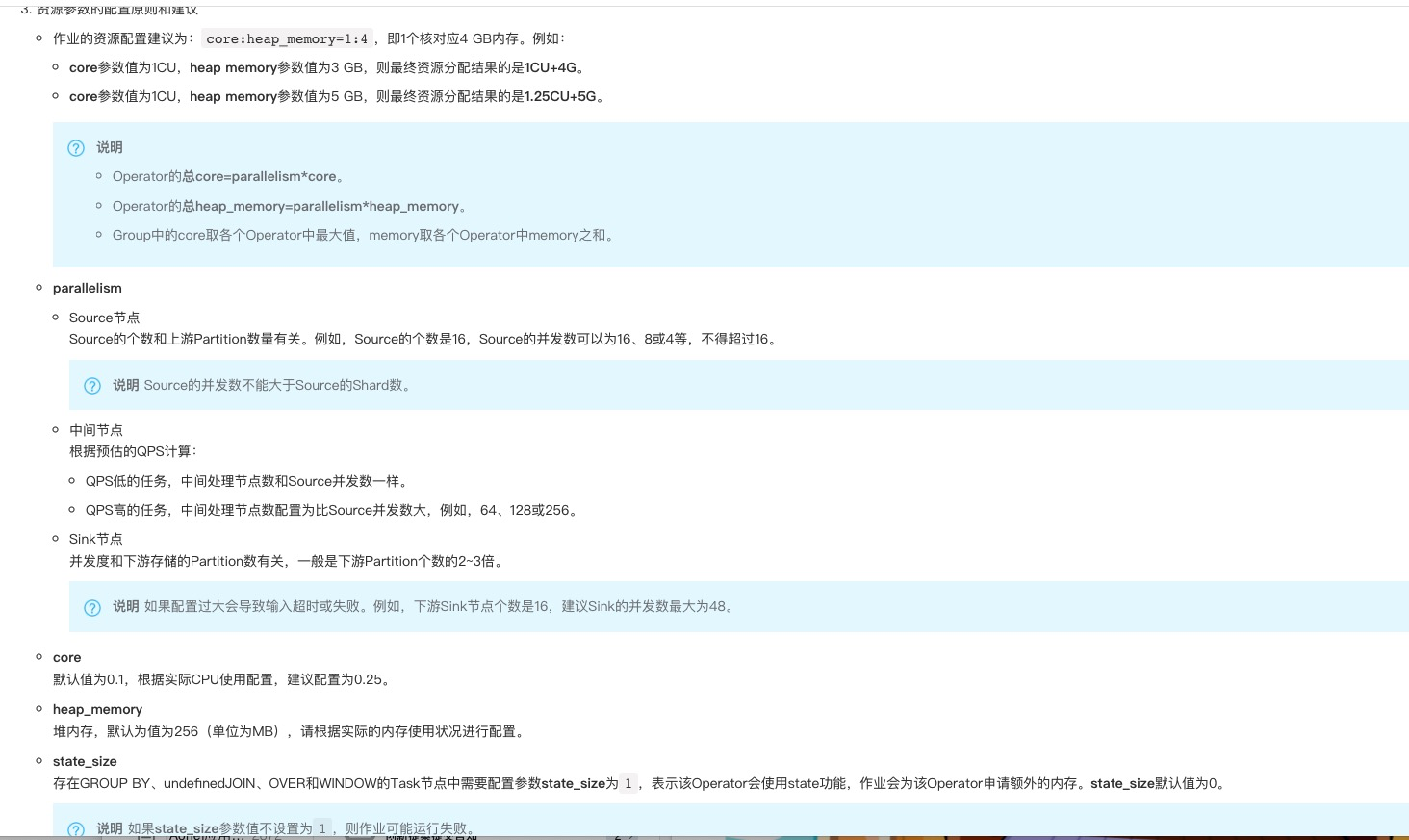
如何配置任务并发和调优?
并发的设置(parallelism)(想想,并发是不是就像多线程)
source节点
source节点的个数和上游partition数量相关。例如,source的 shard分区数为16,那么source节点的并发数可以设置为16、8、或4,但不能超过16,最多一比一.(1个节点消费多个上游队列,不能多个节点消费一个队列,浪费,位点的消费点位有没有问题?)
中间节点
中间节点的并发根据qps预估
- qps低,中间节点个数可以和source节点一致
- qps高,中间节点配置比source并发大,一般为倍数,2倍、3倍这样
sink节点
- 并发度和下游存储的partition数有关,一般是下游partition数的2-3倍。(多个节点往同一个partition里写)
其他资源设置建议(cpu,内存等)
如何保证 exactly once
实现 Exactly Once 语义,则需要在 At Least Once 的基础上进行状态的存储,用来防止重复发送的数据被重复处理,在 Storm 中使用 Trident API 实现。
Exactly Once 中,消息不丢失、不重复,因此需要在 At Least Once 的基础上保存相应的状态,表示上游的哪些消息已经成功发送到下游,防止同一条消息发送多次给下游的情况。

若有收获,就点个赞吧
0 人点赞
