大促保障
压测
- 蓄洪压测
- 原理:将几天的数据积累起来,同一时刻放出来。
- 回放压测
压测方法
追数据压测
指将游标拉回到历史上,让集群有充足的数据来进行消费,来观察集群消费的上线是否达到预期值,好处是由于,
优点:维护成本,压测成本低
缺点:如果日常日志量级比较少(与预期量级相差较大),不容易反映真实情况,例如(数据不到1分钟就追上了,导致压测不能持久,例如日常数据量太少,导致消费速度过快,造成key的量级膨胀,与真实情况不相同)
造数据压测
按照实际线上数据的分布,往另一个影子sls里面灌入与预期相当的数据,新的影子任务通过消费影子数据来进行压力
优点:如果压测数据维护的好,能比较高度的还远线上的实际情况
缺点:维护成本高,压测成本高,需要维护灌数据的任务,保持预期的量级稳定,需要对业务有比较好的理解
注意
压测任务不能往线上数据库写入数据,防止污染数据,通常会写到影子表,或者直接阉割输出节点
海纳压测
因为日志数据比较多,造数据的方式难以维护,海纳集群通常采用追数据的压测方法
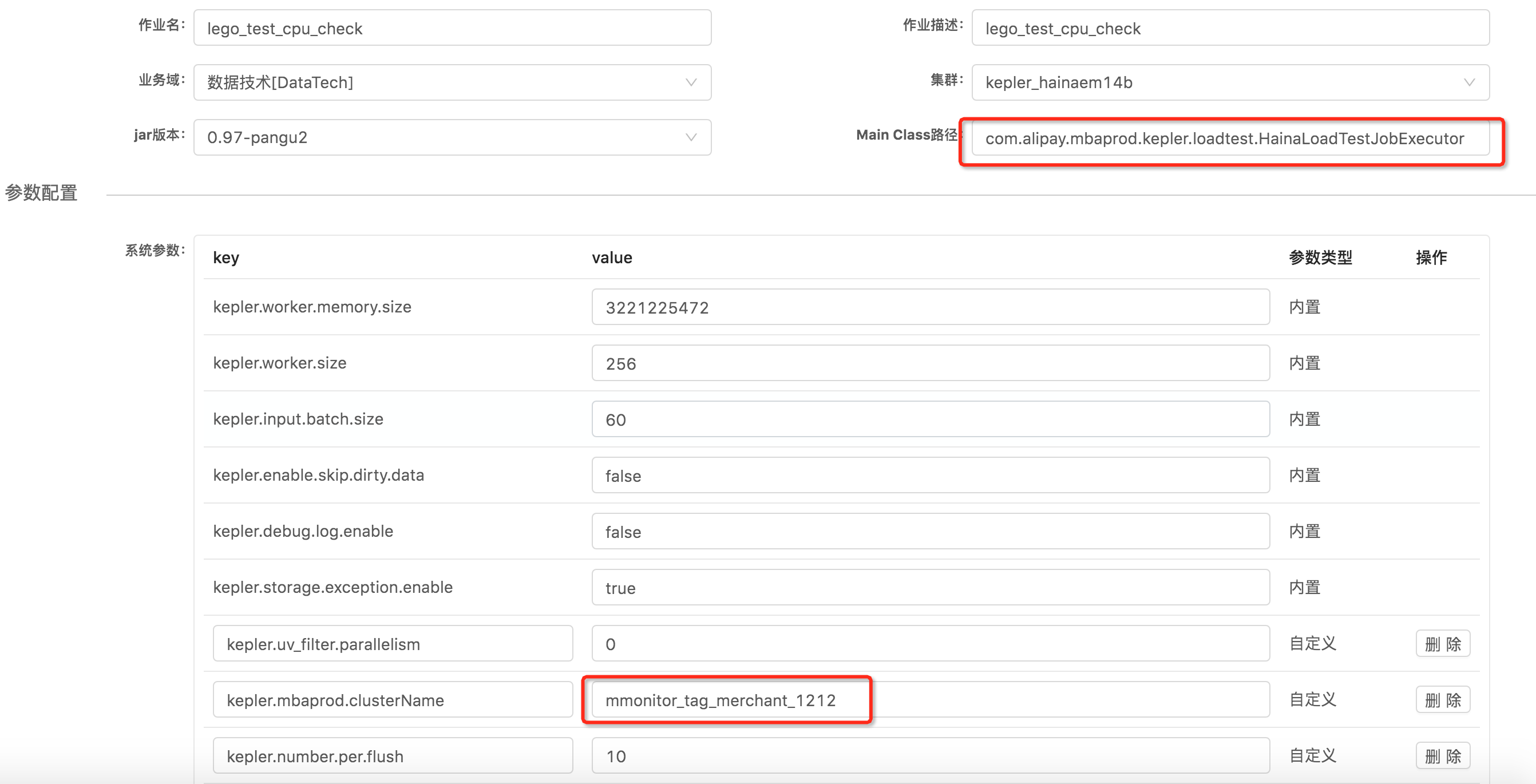
kepler压测任务
http://kepler.alipay.com/topology/hla/11822
如下图
这个类阉割了所有的输出节点,不会影响实际线上任务,数据经过拉取,切分,聚合,然后丢弃,除了存储节点,可以比较好的反映实际计算情况
压测任务可以用这个任务,也可以新建一个压测任务
需要观察的监控界面
业务监控盘:查看各个业务消耗资源情况,用于整改优化
https://mpaasweb.alipay.com/glaucus/1/page/view_1965.htm?role=normal&owner=%D2%E7%CC%EC
考拉监控盘:业务运行容量
http://koala.alipay.com/topology.htm?cluster_name=kepler_hainaem14b&topology_name=lego_test_cpu_check
tm节点日志:
查看瓶颈节点并且排除原因,以及改进
需要调节的kepler配置
https://yuque.antfin-inc.com/monitor_staff/cluster_management/fx2ehw
kepler配置,并发度,内存等,kepler.input.batch.size,默认流控大小,集群名等
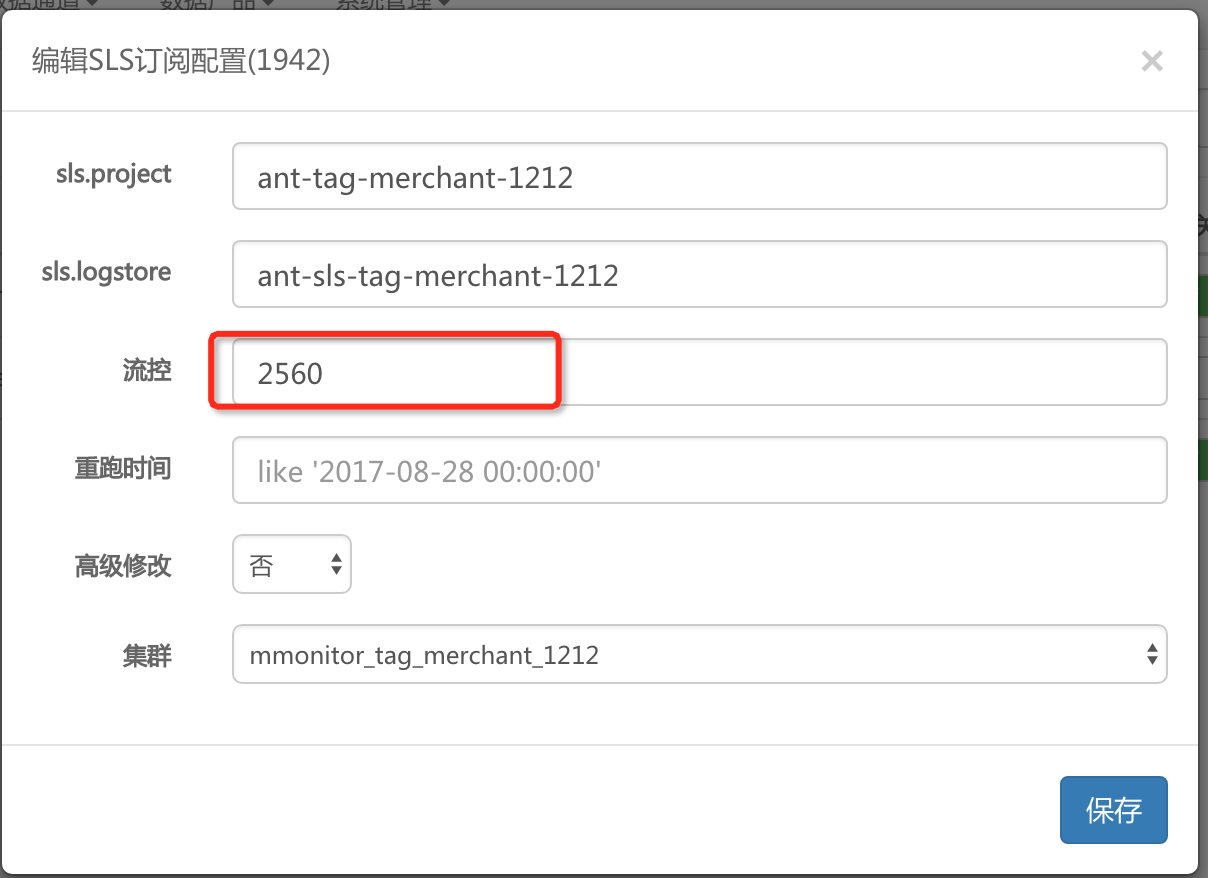
需要调节的mbaprod配置
流控上限值,不同订阅的流控上限值决定了流量的配比(注意,流控值指一个订阅一个批次拉取的数据量,实现方式是流控制除以shard数,每个shard单独以batchsize为入参拉取,循环拉取直到第一次大于这个流控制除以shard数)
参数同步
将修正过的参数同步到线上任务
压测报告
记录cpu,内存水位情况从koala截图
实际数据源或者,切分的流量,从业务监控盘或者海纳截取

若有收获,就点个赞吧
0 人点赞
