https://github.com/antonejia/God-Of-BigData#%E4%BA%94hbase
https://github.com/antonejia/BigData-Interview#%E4%BA%94hbase
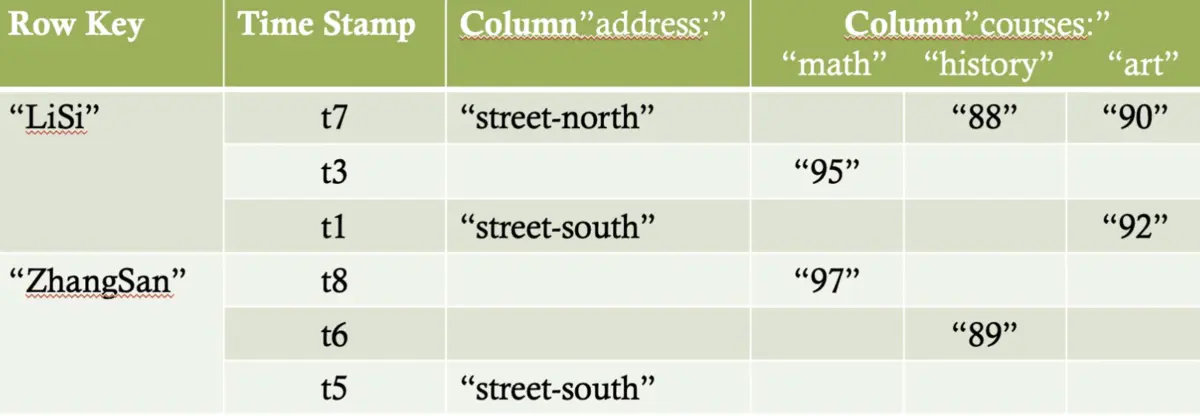
逻辑结构
物理架构
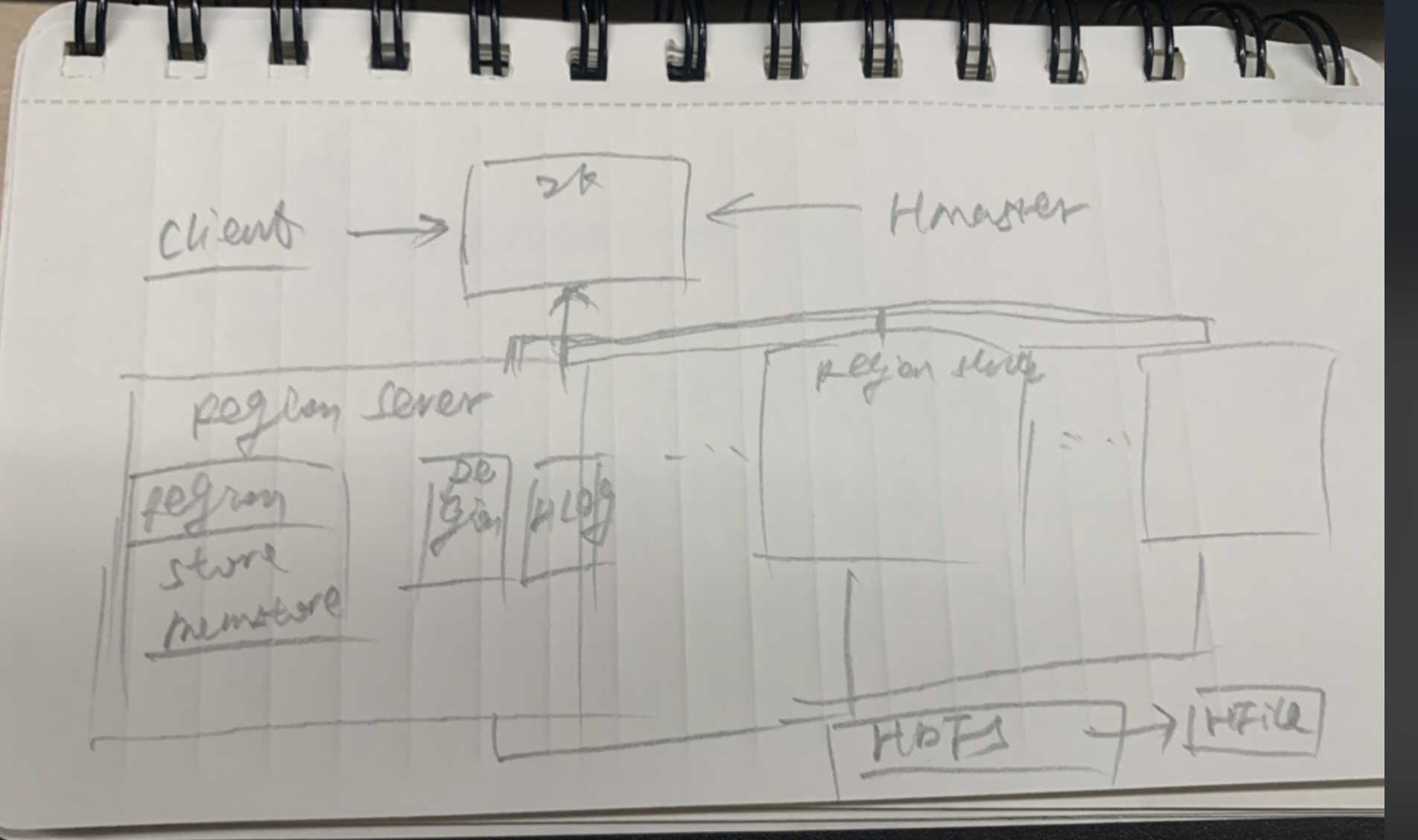
典型的主从架构,一个Hbase集群,一个master,多个region server,zk负责分布式管理,master和server往zk注册机器信息。
上图画的有些问题,比如在读写过程中,client在通过zk拿到对应的region server信息后会直接和region server交互
主要概念
zookeeper
维护机器信息和心跳状态,如果有不可用的机器,会主动通知master。 采用一致性协议保证分布式状态的一致性(这里什么叫分布式状态的一致性:个人理解,因为机器有一台宕机了, 那本该这台机器上访问/存储的数据该怎么办,这些数据就是状态,这就是分布式状态一致性要解决的问题)
Zookeeper一旦感知到RegionServer宕机之后,就会第一时间通知集群的管理者Master,Master首先会将这台RegionServer上所有Region移到其他RegionServer上,再将HLog分发给其他RegionServer进行回放,这个过程通常会很快。完成之后再修改路由,业务方的读写才会恢复正常。
Hmater
- 管理用户的DDL操作(增删改查)
- 统筹协调所有region server
- 启动时分配region,(什么机器该访问/存储什么region由master来定);
- 在故障恢复或负载均衡时重新分配region
- 监控所有 region server实例(就是上面描述的region servier宕机后,master会收到zk发来的消息,然后迁移这台机器上的数据,再将Hlog分发 回放等操作)
Region Server
负责数据的读写操作。
Region server 包含以下几部分
Region
Hbase根据rowkey范围 水平拆分 为很多region。每个Region都包含了从start key到end key的所有行。region 被分配给 region server来管理,每个server可管理大约1000个region
HLog
所有数据会先被写到这里,用来故障恢复
MemStore
写缓存,存储了还没flush到磁盘的数据,数据会先写到这里,积累到一定程度后统一flush到HDFS(一个HFile的形式)。
这里的数据是有序的,写到HDFS的时候也是顺序写。
HFile
在HDFS上存储的方式就是HFile,以有序key value的形式。Hbase为每个列簇都创建一个HFile,里面具体的cell就是key value的数据。如下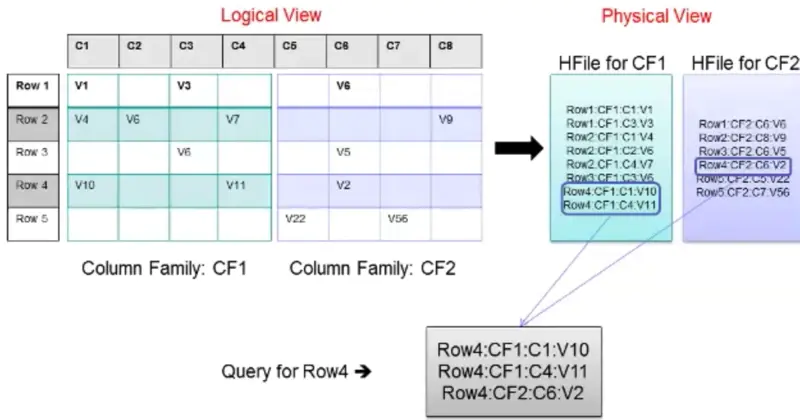
写流程
1、找到该往哪台region servier写:client通过zk获取哪台机器存放着 meta table,client 从该台机器获取 该往哪台server写
2、region server先写到内存,并返回client 成功
3、同时写Hlog
4、内存到达一定量级后,flush到HDFS。同时删除内存数据,删除Hlog中的历史数据,记录最后写的数据的最大序列号(?)
读流程
- 同样先找到应该往哪台region server去读
- 先从server memstore中读,没有就从HFile上读
读合并:每行数据可能当前在不能的位置,有的在内存里有,有的可能刚刚读过,在server 缓存里,有的可能在HFile里,这些地方都读过来然后合并结果,就叫读合并。
因为同一行数据 不同的列簇的数据可能在不同的HFile里,所以一次读取可能需要读取多个HFile,影响性能,这就叫 读放大
其他一些操作
Minor Compaction
Hbase会把一些小的HFile文件自动合并为大的HFile文件,这个过程就叫Minor Compaction,减少HFile的数量。 为的是提高读写效率
Major Compaction
把同一列簇的所有 HFile合并为一个大的HFile,这个就叫Major Compaction。
一般很耗磁盘和网络IO,在低峰期执行。
Region分裂
当一个Region数据量过大时(多大?),会自动分裂,这个分裂动作会报告给HMaster,更新元数据信息。
问题:
哪里存储了这个信息:region存在于哪个region server。这是meta信息
Hbase有什么缺点,为什么会有lindorm
热点问题如何解决
Hbase几个典型特点/关键词
- 列式存储:(什么是列式存储 https://juejin.cn/post/6844904118872440840,一列的数据会顺序存在一起,这样方便一列的全部数据快速读出来,这也是他擅长的查询场景,范围批量查?)
- 无固定schema,每一行的schema可不同,只要列簇相同
- 数据无类型,就是字节码。所以查询时需要转类型
Hbase支持的查询操作
写入节点挂掉,如何保证数据不丢失。
https://www.zhihu.com/column/p/28475168
http://hbasefly.com/2016/10/29/hbase-regionserver-recovering/
关键解答:HBase集群中一台RegionServer宕机(实指RegionServer进程挂掉,下文同)并不会导致已经写入的数据丢失,和MySQL等数据库一样,HBase采用WAL机制保证这点:它会先写HLog,再写缓存,缓存写满后一起落盘。即使意外宕机导致很多缓存数据没有及时落盘,也可以通过HLog日志恢复出来
Zookeeper一旦感知到RegionServer宕机之后,就会第一时间通知集群的管理者Master,Master首先会将这台RegionServer上所有Region移到其他RegionServer上,再将HLog分发给其他RegionServer进行回放,这个过程通常会很快。完成之后再修改路由,业务方的读写才会恢复正常。
可是没有数据丢失并不意味着宕机对业务方没有任何影响。众所周知,RegionServer宕机是由zookeeper首先感知到的,而zookeeper感知到RegionServer宕机事件是需要一定时间的,这段时间默认会有3min。也就是说,在RegionServer宕机之后的3min之内系统并不知晓它实际上已经宕机了,所有的读写路由还会正常落到它上面,可想而知,这些读写必然都会失败。(当然,并不是所有RegionServer宕机都需要3min中才能被Zookeeper感知。如果RegionServer在运行过程中产生自身难以解决的问题,它会自己abort自己,并且RegionServer会主动通知Zookeeper自己已经宕机的事实。这种场景下,影响用户读写的时间会极大的缩短到秒级)
Hbase如何支持sql查询

若有收获,就点个赞吧
0 人点赞
