开发经验
service中如果有复杂的Dao查询,可以封装子mapper
子mapper继承默认mapper,实现复杂dao层接口,service调用子mapper
简单的add edit对前端的接口,可以直接controller层接收DO对象,
避免复杂的冗余的接收对象定义 和 到DO的转换
在service层create时,可调用mapper的insertSelective方法(因为此时id等参数为null)
@Overridepublic int create(DpsPhysicalTableDO dpsLogicalTableDO) {return mapper.insertSelective(dpsLogicalTableDO);}
Controller层测试(postman)
对post接口的测试,接收对象一般为JSON类型的数据结构(含结构化的类),postman测试时body传递可以选择”raw“,并记得选择content-type:JSON
父子线程之间的trace传递
调用链追踪:在调用链系统设计中,为了优化系统运行速度,会使用多线程编程,为了保证调用链ID能够自然的在多线程间传递。对于父线程中定义为ThreadLocal的变量,需要考虑其传递问题
https://www.jianshu.com/p/94ba4a918ff5
通过反射获取实现一个接口的所有子类
场景:在工厂模式中, 经常需要将所有实现(定义一个接口,不同的类不同的实现方式)统一管理起来,一般存储到一个map结构,暂且称之为“对象工厂”,这就涉及到对象的注册。如果用Spring,可以有两种方式
(1)在类的默认构造方法中,统一调用register到map中
(2)实现BeanPostProcessor,在后处理中register(这时候也可以定义一个注解,写一个单独的类实现BeanPostProcessor,在其post方法中处理该注解)
如果不用Spring,单纯的一个Java工程,可使用反射来做。利用类库
<dependency><groupId>org.reflections</groupId><artifactId>reflections</artifactId><version>0.9.12</version></dependency>
https://github.com/ronmamo/reflections
Reflections reflections = new Reflections("my.package");Set<Class<? extends SomeType>> subTypes = reflections.getSubTypesOf(SomeType.class);然后Class.newInstance()创建实例,register到map中
如何在spring中获取代理对象的目标对象
https://blog.csdn.net/xiongyouqiang/article/details/80401703
public static Object getTarget(Object proxy) throws Exception {if (!AopUtils.isAopProxy(proxy)) {//不是代理对象return proxy;}Object obj = null;if (AopUtils.isJdkDynamicProxy(proxy)) {obj = getJdkDynamicProxyTargetObject(proxy);} else { //cglibobj = getCglibProxyTargetObject(proxy);}return getTarget(obj);}/*** 多层代理的时候递归到原始对象 获取 目标对象** @param proxy 代理对象* @return* @throws Exception*/@Deprecatedpublic static Class<?> getTargetClass(Class<?> proxy) throws Exception {if (!isProxyClass(proxy)) {//不是代理对象return proxy;}return getTargetClass(proxy.getSuperclass());}public static boolean isProxyClass(Class<?> clazz) {return Proxy.isProxyClass(clazz) || AopUtils.isCglibProxy(clazz);}/*** @param proxy* @return* @throws Exception*/private static Object getCglibProxyTargetObject(Object proxy) throws Exception {Field h = proxy.getClass().getDeclaredField("CGLIB$CALLBACK_0");h.setAccessible(true);Object dynamicAdvisedInterceptor = h.get(proxy);Field advised = dynamicAdvisedInterceptor.getClass().getDeclaredField("advised");advised.setAccessible(true);Object target = ((AdvisedSupport)advised.get(dynamicAdvisedInterceptor)).getTargetSource().getTarget();return target;}/*** 获取AOP生成的代理** @param proxy* @return* @throws Exception*/private static Object getJdkDynamicProxyTargetObject(Object proxy) throws Exception {Field h = proxy.getClass().getSuperclass().getDeclaredField("h");h.setAccessible(true);AopProxy aopProxy = (AopProxy)h.get(proxy);Field advised = aopProxy.getClass().getDeclaredField("advised");advised.setAccessible(true);Object target = ((AdvisedSupport)advised.get(aopProxy)).getTargetSource().getTarget();return target;}
如何优雅地统计方法耗时-stopWatch
https://www.yuque.com/antone/zv3ypu/abgos9#X1sDe
如何创建内存缓存
https://www.yuque.com/antone/zv3ypu/abgos9#MsKjY
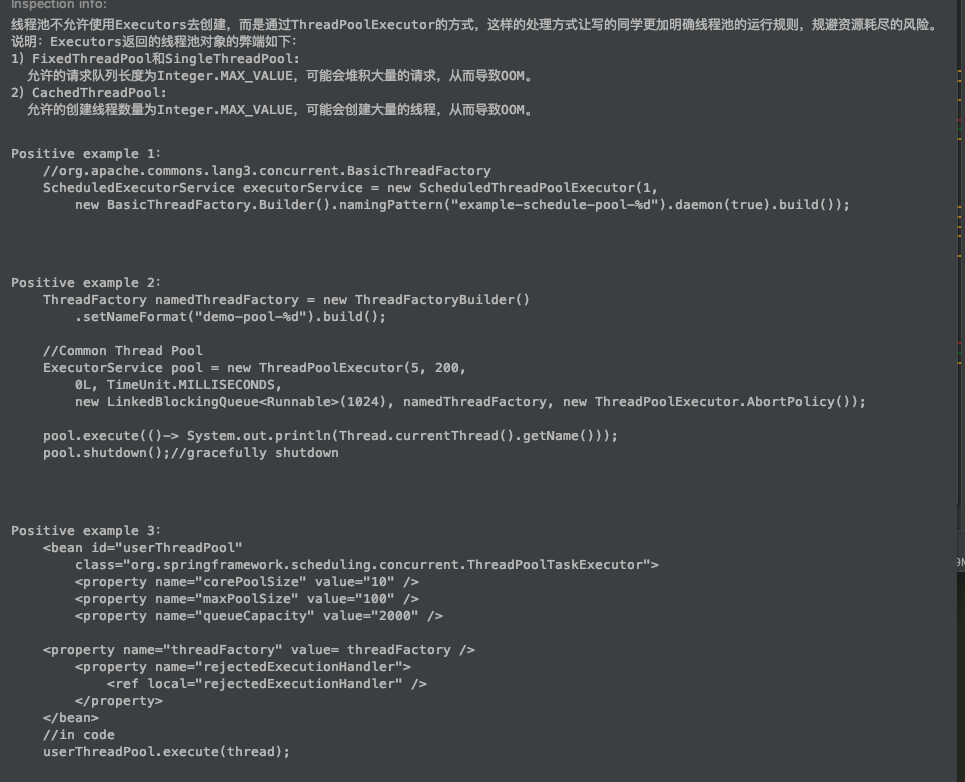
如何优雅的创建线程池
public class xxx {private ThreadPoolTaskExecutor dpsQueryExecutor;/**import javax.annotation.PostConstruct;*/@PostConstructpublic void init() {dpsQueryExecutor = new ThreadPoolTaskExecutor();dpsQueryExecutor.setCorePoolSize(50);dpsQueryExecutor.setMaxPoolSize(500);dpsQueryExecutor.setKeepAliveSeconds(60);dpsQueryExecutor.setQueueCapacity(30);dpsQueryExecutor.setThreadFactory(new ThreadFactoryBuilder().setNameFormat("DpsQueryExecutor-Pool-%d").build());// 对任务执行前后做一些事情,包装器dpsQueryExecutor.setTaskDecorator(runnable -> {final Object rpcContext = EagleEye.currentRpcContext();return () -> {try {// 这里是想做到 父子线程之间的trace传递,traceid不变?EagleEye.setRpcContext(rpcContext);runnable.run();} finally {EagleEye.clearRpcContext();}};});dpsQueryExecutor.initialize();}}
如何想在对象初始化后做一定的事情?
方法1:@PostConstruct
import javax.annotation.PostConstruct;@PostConstructpublic void init() {}
方法2:
import org.springframework.beans.factory.config.BeanPostProcessor;public class ComponentHandlerMapping implements BeanPostProcessor {/*** postProcessBeforeInitialization 方法会在Bean构造完成后(构造方法执行完成),初始化方法(init-method)方法调用之前被调用** @param bean 刚刚由Spring实例化出来的Bean* @param beanName 在Spring配置元数据中Bean的名称(id or name)* @return* @throws BeansException*/@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {//如果不做任何事情,直接return beanreturn bean;}/*** Bean构造完成后(构造方法执行完成),初始化方法(init-method)方法完成后被调用** @param bean* @param beanName* @return* @throws BeansException*/@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {xxx}}
注意:postProcessAfterInitialization方法里bean是 spring 代理后的对象,要想获取实际目标对象,参考 https://www.yuque.com/antone/zv3ypu/vw5p0t/edit#SsW4m
方法3:
import org.springframework.beans.factory.InitializingBean;public class BaseSmartInterceptor implements InitializingBean {/*** 在spring bean 被初始化后 会执行该方法,* @throws Exception*/@Overridepublic void afterPropertiesSet() throws Exception {this.init();}}
如何优雅地在完整地打印一次业务逻辑里的想追踪的trace信息
场景:在dps项目里,想打印一次请求中最终执行的sql语句
简单粗暴的方式,在最终生成sql的部分,直接log打印。
缺点:如果有更多信息要打印都要这么做,日志打印代码极不好看地掺杂在了业务逻辑之中。
解决办法:定义拦截器,同时采用ThreadLoacal存储所有trace信息(根据业务需要自定义Trace对象),在需要的时候 往ThreadLoacal set。在拦截器初始时,初始化ThreadLoacal,结束时,清空
public class TraceHelper {private static final ThreadLocal<TraceInfo> TRACE_HOLDER = new InheritableThreadLocal<>();public static void set(TraceInfo traceInfo) {TRACE_HOLDER.set(traceInfo);}public static TraceInfo get() {return TRACE_HOLDER.get();}public static void clear() {TRACE_HOLDER.remove();}public static void appendSql(String sql) {try {TRACE_HOLDER.get().appendSql(sql);} catch (Throwable e) {log.error("traceError", e);}}}import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;@Component@Slf4jpublic class TraceHandlerInterceptor extends HandlerInterceptorAdapter {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)throws Exception {TraceHelper.set(new TraceInfo());return true;}@Overridepublic void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,ModelAndView modelAndView) throws Exception {log.info("trace \n{}", JSON.toJSONString(TraceHelper.get()));TraceHelper.clear();}}public class xxx {public void methodxxx() {//在这里 set traceTraceHelper.appendSql(rawSql);}}
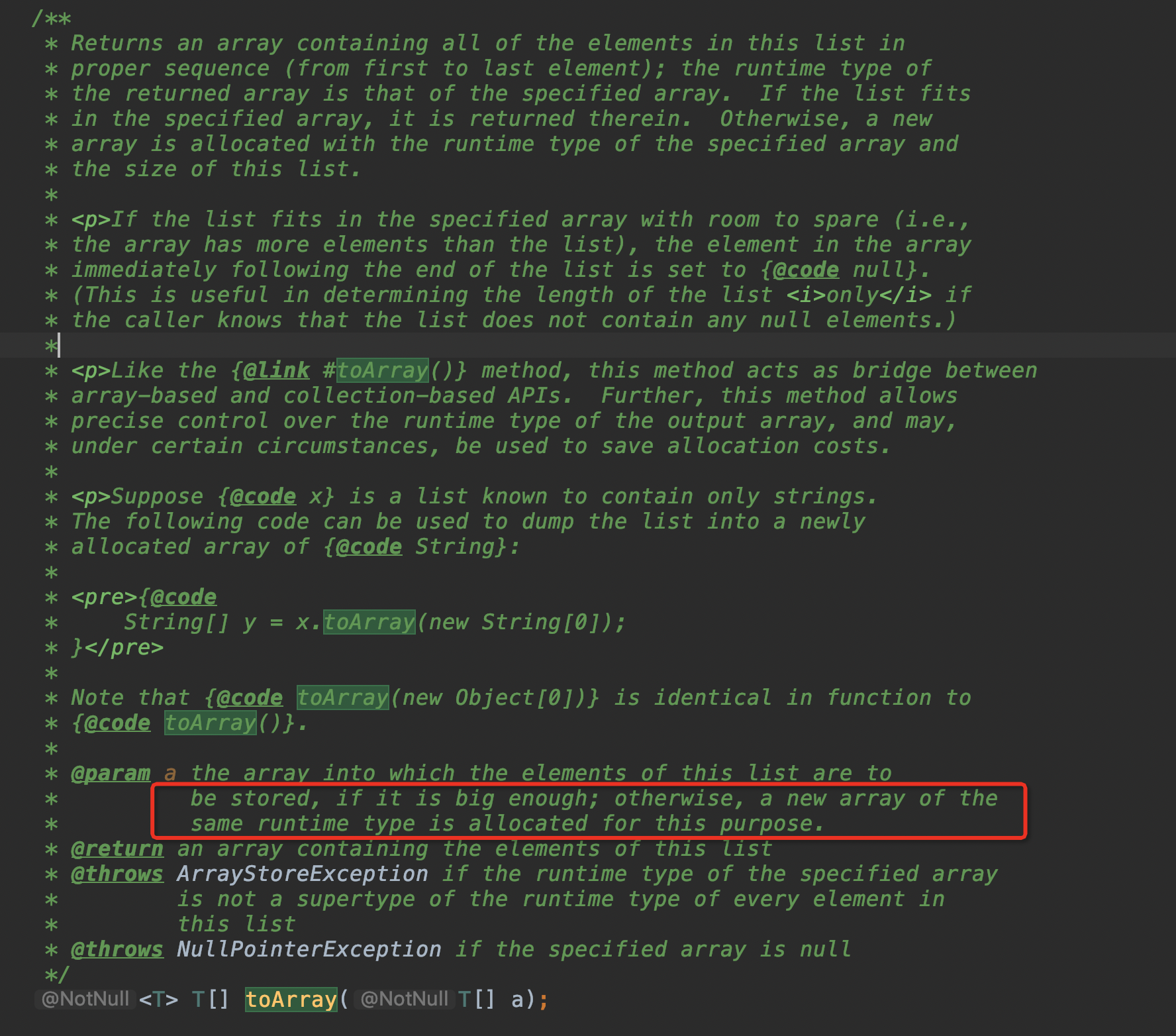
List转数组
方式1:
把Stream的元素输出为数组和输出为List类似,我们只需要调用toArray()方法,并传入数组的“构造方法”:
List<String> list = List.of("Apple", "Banana", "Orange");String[] array = list.stream().toArray(String[]::new);
方式1:
list.toArray(new String[0])
List<父类>转List<子类> List A 转List B
List<AbstractMonitorObject> abstractMonitorObjectList = xxx;// 这里为什么可以写new TopicMonitorObject[0], 因为实际上会新建一个TopicMonitorObject类型的数组//然后把abstractMonitorObjectList的元素一个一个的放进去,为什么放得进去,这里前提是abstractMonitorObjectList// 里的元素 本来存的就是TopicMonitorObject类型。这里只是做一个List<?>定义上的转换return Arrays.asList(abstractMonitorObjectList.toArray(new TopicMonitorObject[0]));
return Optional.ofNullable(abstractMonitorObjs).orElse(ImmutableList.of()).stream().map(o -> (TopicMonitorObject)o).collect(Collectors.toList());
通用程序设计
如何快速创建一个对象、map、list
场景:写测试用例时,有时需要构建一个list,原始写法
List list = new ArrayList();T t1= new T();t1.set();...T t2 = new T();t2.set();...list.add(t1);list.add(t2);
这样写代码繁重,如何简便?
采用google guava
构建list:ImmutableList.of(, , , ,);
构建Map,ImmutableMap.of()
如何生成一个N以内的随机整数
采用Random.nexInt(N)
而不是自己编写以下函数,弊端:
- 极端情况下 生成的数字 可能重复、可能不够随机
Math.abs(new Random().nextInt()) % N
生成随机数,以及能提升多线程情况下性能的ThreadLocalRandom


Arrays.asList构造的list是immutable的
代码逻辑中使用断言
比如使用 Assert.notEmpty 来保证 集合不空,空则抛出异常。省略繁琐的集合判空,并抛异常的代码。
从json字符中获取array
场景
{"GOC": [123, 456, 789],"CUSTOM": [213, 87]}
获取”GOC”对应的 数组,并判断是否包含某个Long值
错误的写法:
JSONObject jsonObject = JSON.parseObject(monitorSceneConfig);JSONArray configIds = jsonObject.getJSONArray(monitorScene);Long currentConfigId = 123L;// 拿着当前的ID 和配置参数里的ID进行匹配if (CollectionUtils.contains(configIds.iterator(), currentConfigId)) { // 这里不能被判断为 包含,因为JSONArray返回的实际是个Integer类型,底层equals时会判为不相等......}
正确的写法
将JSONArray configIds = jsonObject.getJSONArray(monitorScene);改为List<Long> configIds= JSONObject.parseArray(jsonObject.getString(monitorScene), Long.class);
文件读写
读取文件内容,所有内容转换为大的String串
思路:BufferedReader逐一(循环)读取单行,以“\n”拼接;
编写方法:常见的while(br.read() != null) { s += br.read() + “\n” };优化方法:采用Stream,可以看到Stream的灵活使用使代码简洁,并且某些时候比较易懂
// classloader 读取文件流,file path为resource目录下的相对路径InputStream inputStream = XXX.class.getResourceAsStream("file path");BufferedReader br = new BufferedReader(inputStream).lines() // lines stream.collect(Collectors.joining("\n"));
方式二:继续优化
例如,Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容:
try (Stream<String> lines = Files.lines(Paths.get("/path/to/file.txt"))) {...}
此方法对于按行遍历文本文件十分有用。
以上方法位于 JDK 1.8之后的NIO包。
方式三:
java.nio.file.Files#readAllLines(java.nio.file.Path, java.nio.charset.Charset)
Path的构造方式:Paths.get(“src/test/resources/indicator/repo3.json”)
可以为相对路径,也可以为绝对路径。但都是当前操作系统下的文件路径(pwd),而不是Java工程编译后的相对路径和绝对路径。
一般当前路径为当前工程的根目录。可通过Paths.get(“.”).toAbsolutePath().toString()看下当前路径是什么,以决定相对路径如何写。
方式四:guava的Files类有更直接的方法:
com.google.common.io.Files#readLines(java.io.File, java.nio.charset.Charset)
方式五:apache common库有IOUtils,应该更简单
通过自定义命令行参数执行java程序
场景:java命令行执行一个main程序,希望动态传入一些参数。核心要解决 参数的定义和参数值的传递/解析 问题。
类库:jcommander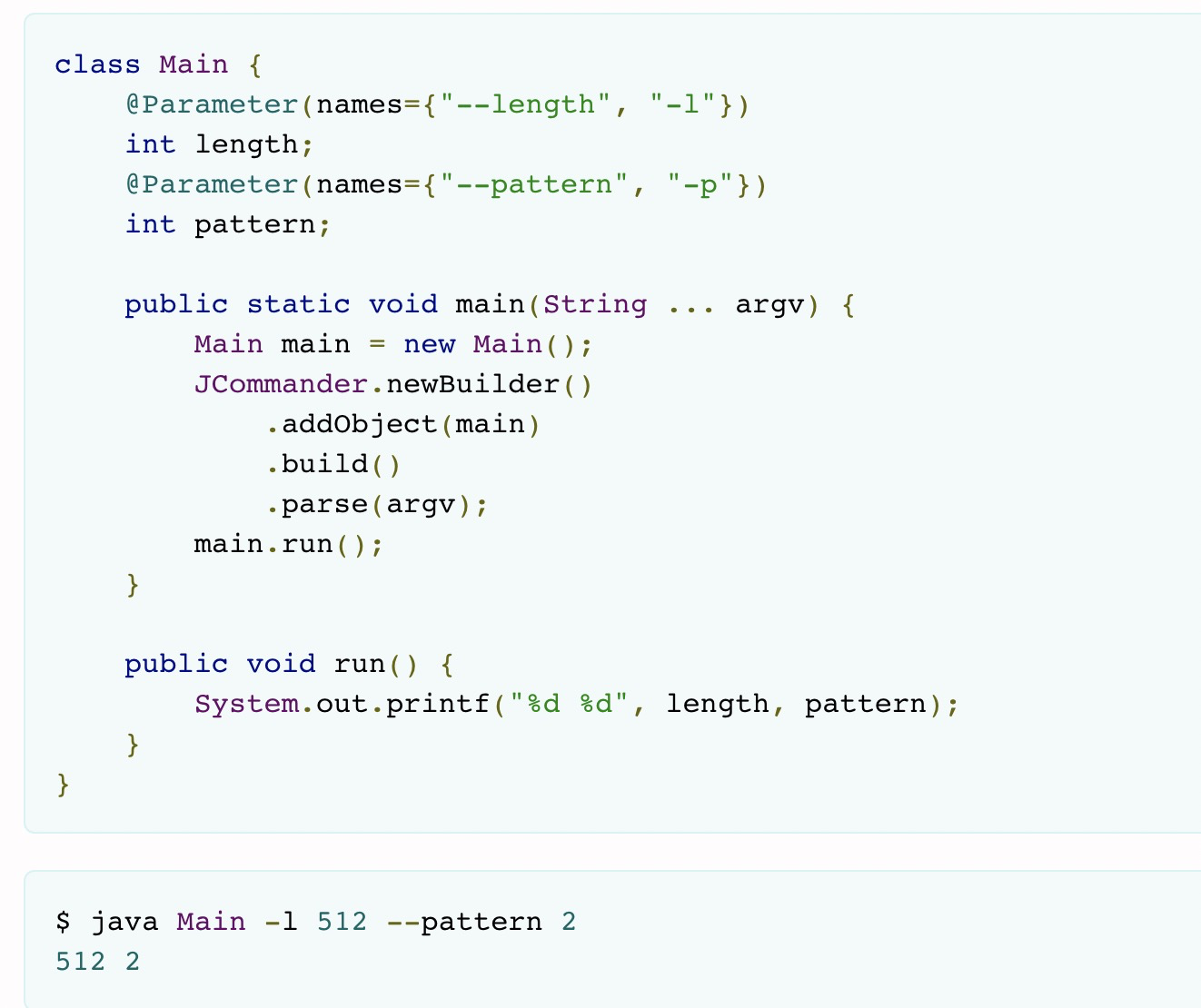
JSON parse相关
json字符串转换为含自定义类的对象
比如转换为Map
使用TypeReference
JSON.parseObject(s, new TypeReference<Map<String, MyCustomClass>>() {})
踩坑记录
当字符串采用 | 进行分割
当字符串采用 | 进行分割,想要split时,直接采用string.spit(“|”) 会有问题,这里默认的split方法 将其作为了正则表达式进行
这时应采用 apache的 StringUtils,这也是经验,涉及到字符串操作都要采用StringUtils
这种小问题不容易发现,一旦出现可能会浪费你好几个小时,踩坑了。
时刻注意 StringUtils.split的大坑,与splitByWholeSeperator的区别
public static String[] split(final String str, final String separatorChars)public static String[] splitByWholeSeparator(final String str, final String separator);
split方法是按每个字符进行分隔,而splitByWholeSeparator是按整个字符串分隔
所以split(xx, “abc”) 会按 “a” “b” “c” 均做分隔,而splitByWholeSeparator(xx, “abc”) 按”abc”整体进行分隔。
编码问题
case:老项目是GBK编码的,通过IDEA导进来后,build会出错。提示“java:编码UTF-8的不可映射字符”,类似下图的错误。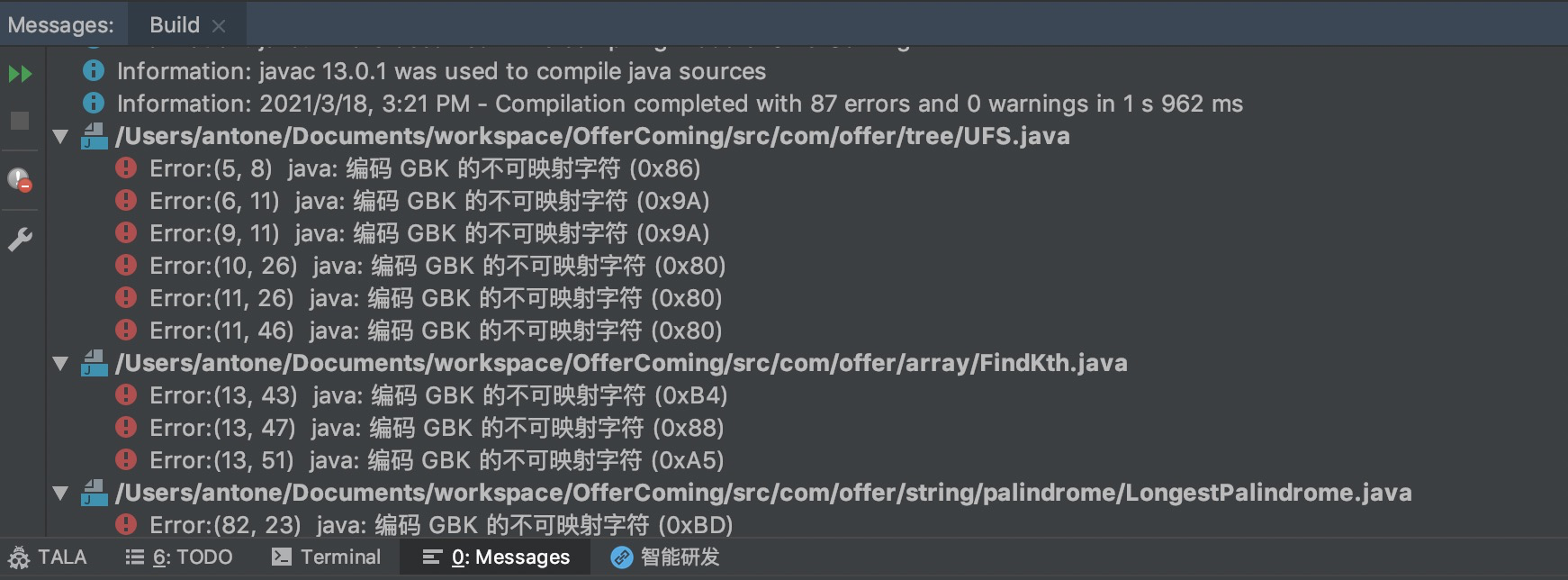
解决办法:
(1)如果想继续采用GBK编码,那么更改IDEA配置,注意只更改当前project的配置。以下位置都改为GBK。
重新build看有没有问题。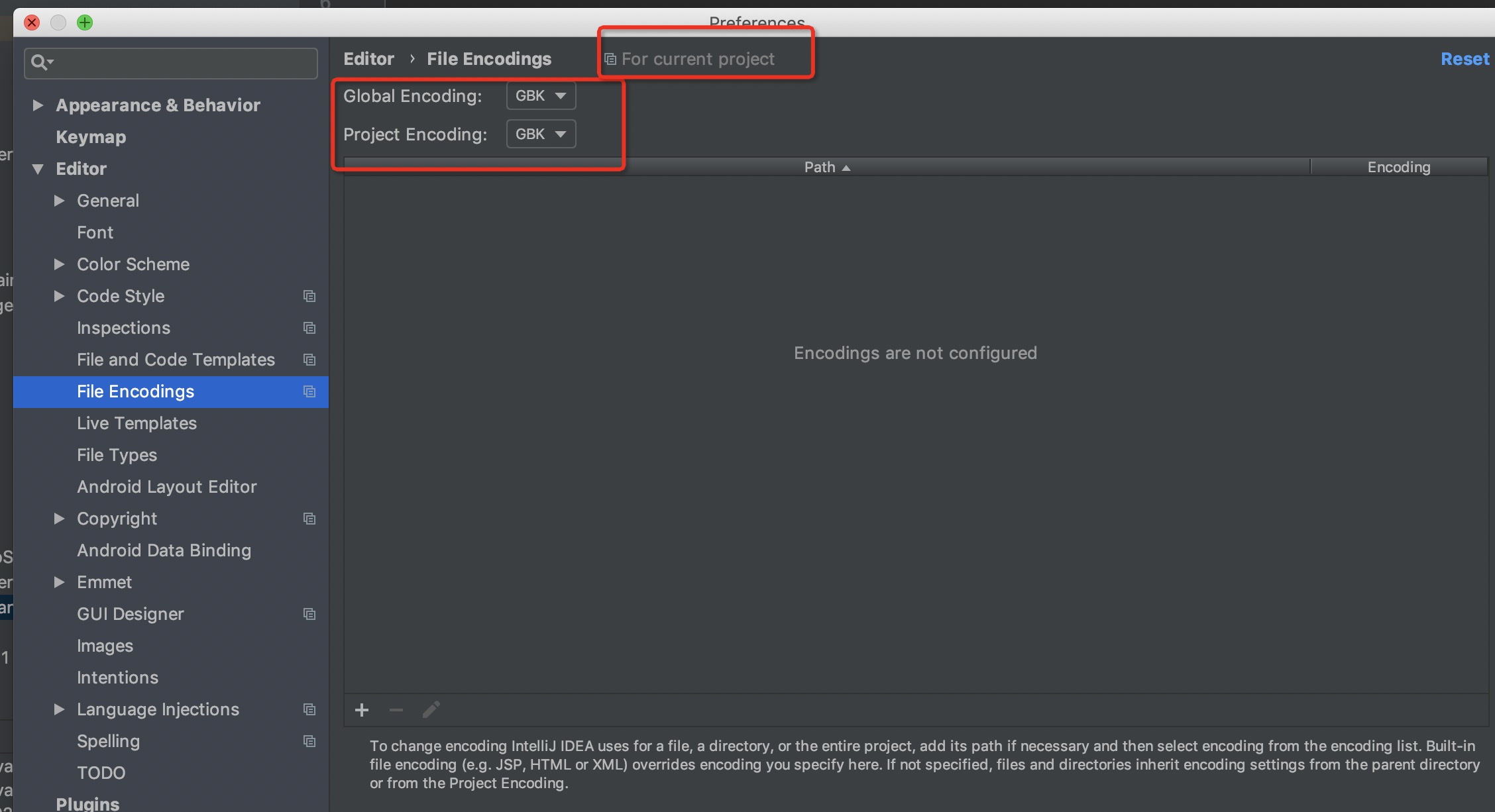
(2)倾向所有项目的文件统一采用UTF-8编码。所以想用UTF-8编码加载工程。思路:先将所有文件都转化为UTF-8编码,再用utf-8加载工程。对于单个文件,方式如下:
- 先用 GBK形式 reload文件,确保显示正常。然后转换为utf-8
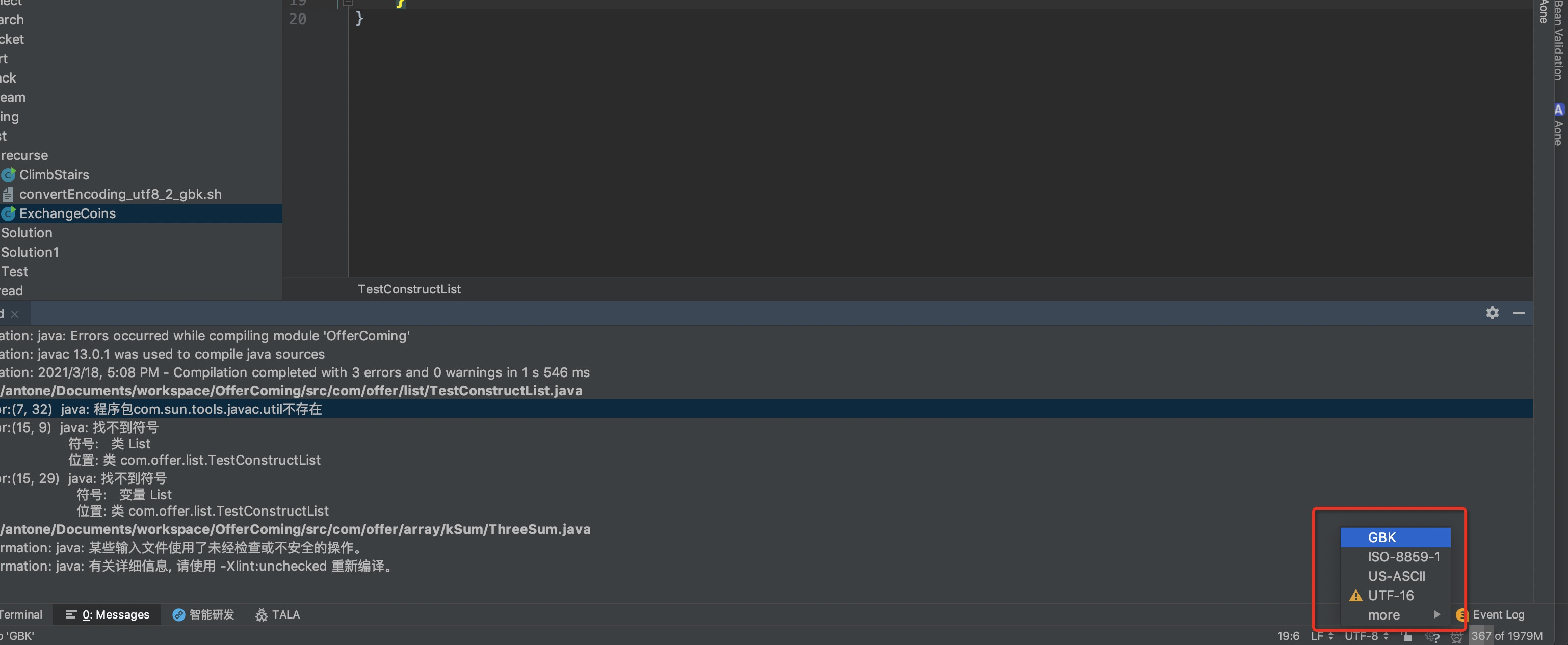
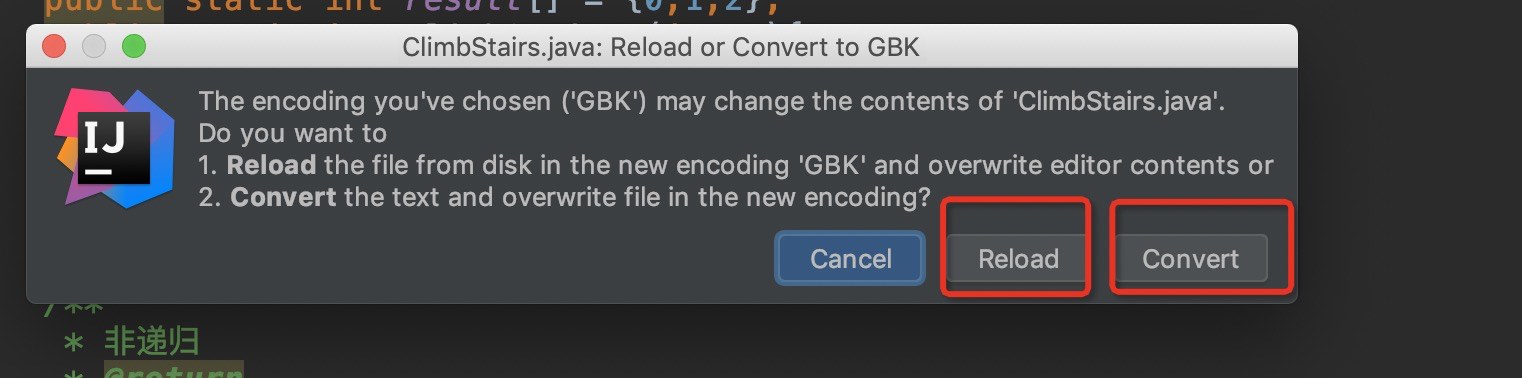
- 以上步骤操作完后会在下面图中显示一条记录。这也是idea的环境配置。也可从这里直接添加文件编码配置。
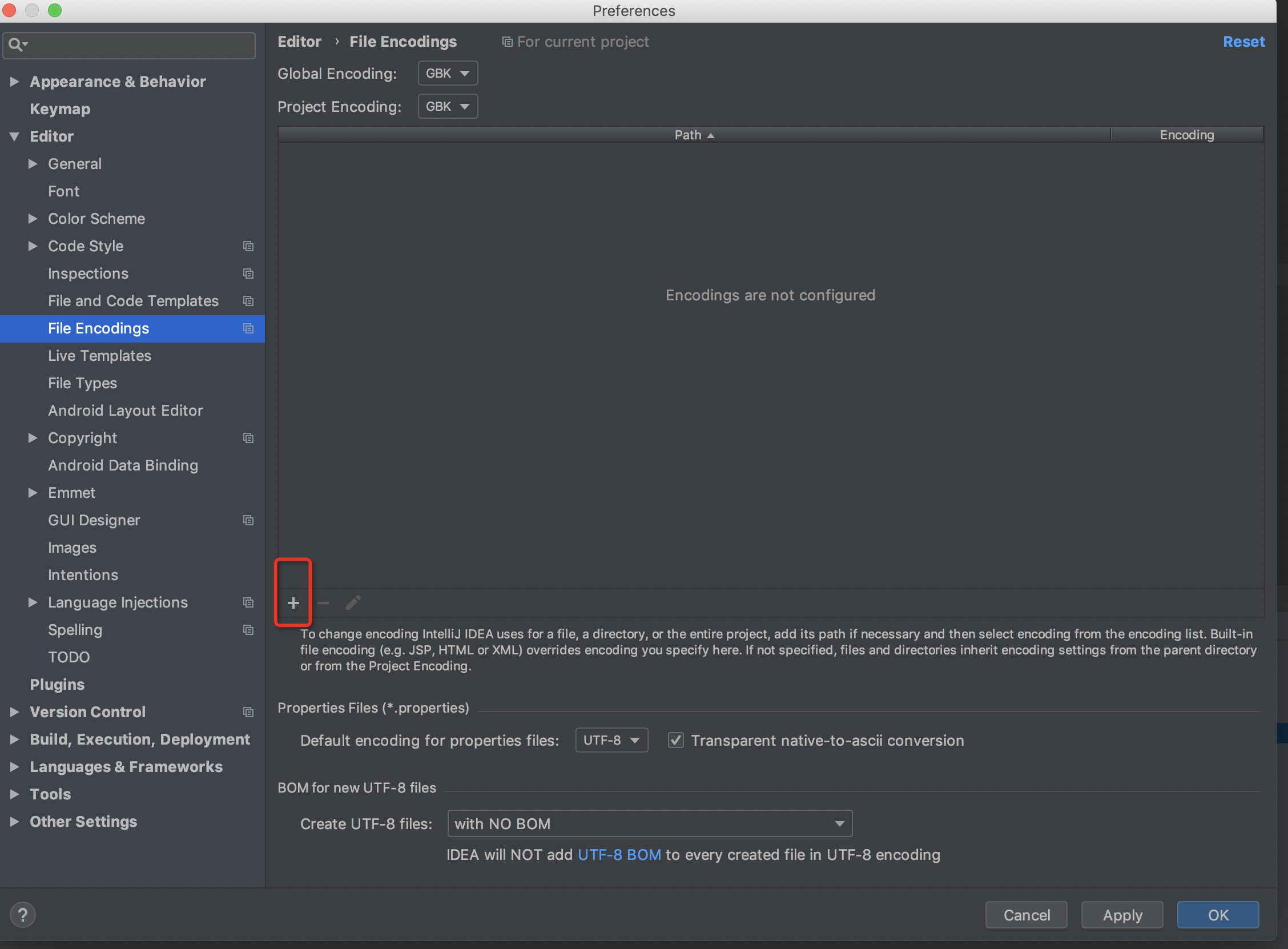
但对于多个文件,如何批量操作呢?我并没有找到好的方法。上图中可以设置directory的编码,但并没有生效于其下的所有文件。
网上搜索到其他最原始的命令行的方法,尝试基本成功,但有部分文件出现转换后部分内容丢失。
#!/bin/shfor file in `find ./ -name "*.java"`;doecho convering : $fileiconv -f GBK -t utf-8 $file > $file.tmv $file.t $filedoneecho DONE
Debug时出现断点不可打,no executable code found …..
一般就是本地代码和远程代码不一致
排查过程踩了一些坑,但最终其实还是代码不一致的原因
多线程对同一集合Sort时,会报错,注意不要直接sort原集合,而是copy一份
场景:一段代码中包含以下集合sort语句。该代码会多线程同时执行,在每个线程中都会排序同一个集合xxx。
Collections.sort(xxx)
报错信息:
java.util.ConcurrentModificationExceptionat java.util.ArrayList.sort(Unknown Source)at java.util.Collections.sort(Unknown Source)at CollectionsTS.MyRunnable.run(ArrayListTS.java:37)at java.lang.Thread.run(Unknown Source)java.util.ConcurrentModificationExceptionat java.util.ArrayList.sort(Unknown Source)at java.util.Collections.sort(Unknown Source)at CollectionsTS.MyRunnable.run(ArrayListTS.java:37)at java.lang.Thread.run(Unknown Source)
内部类 generic array creation
我遇到了如下代码一样的错误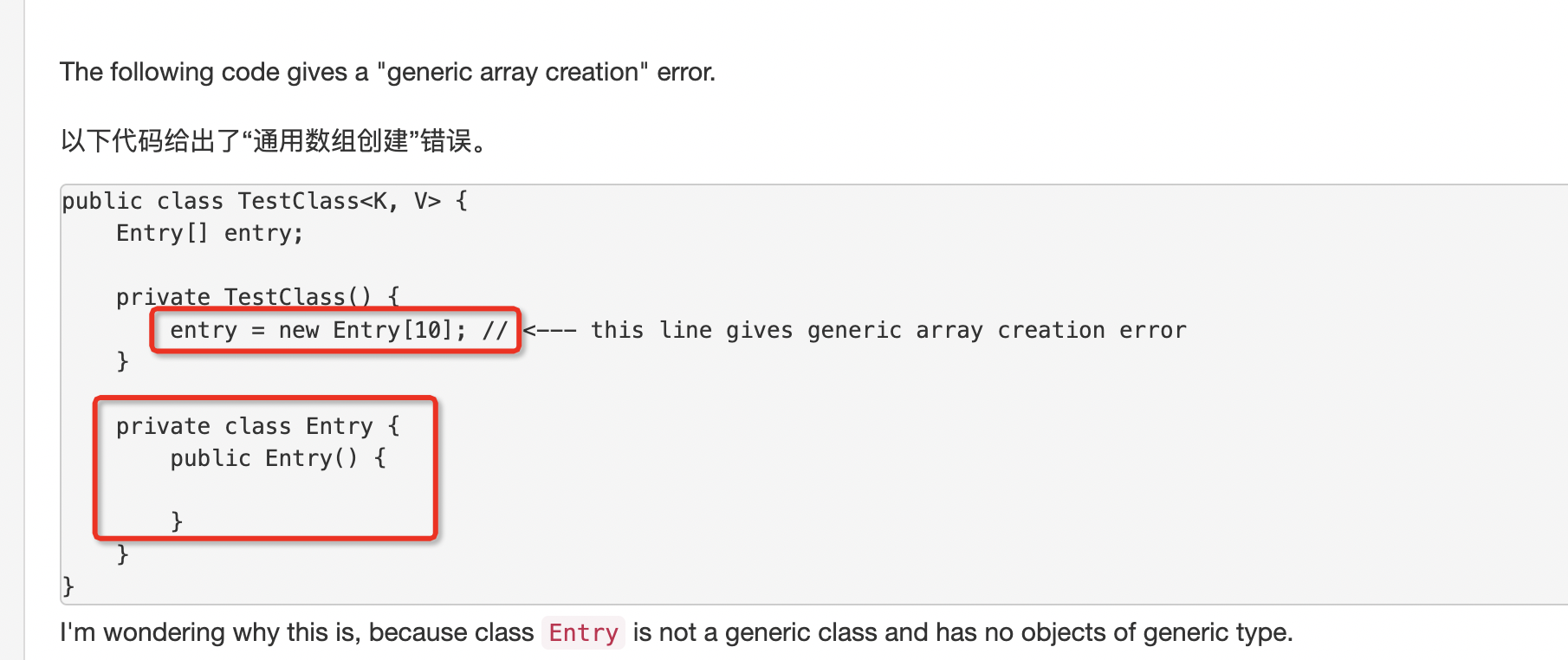
原因还是没太明白。内部类听恶心的,还是尽量少用,容易踩坑。
解决方案
https://codejzy.com/posts-600581.html
1、加static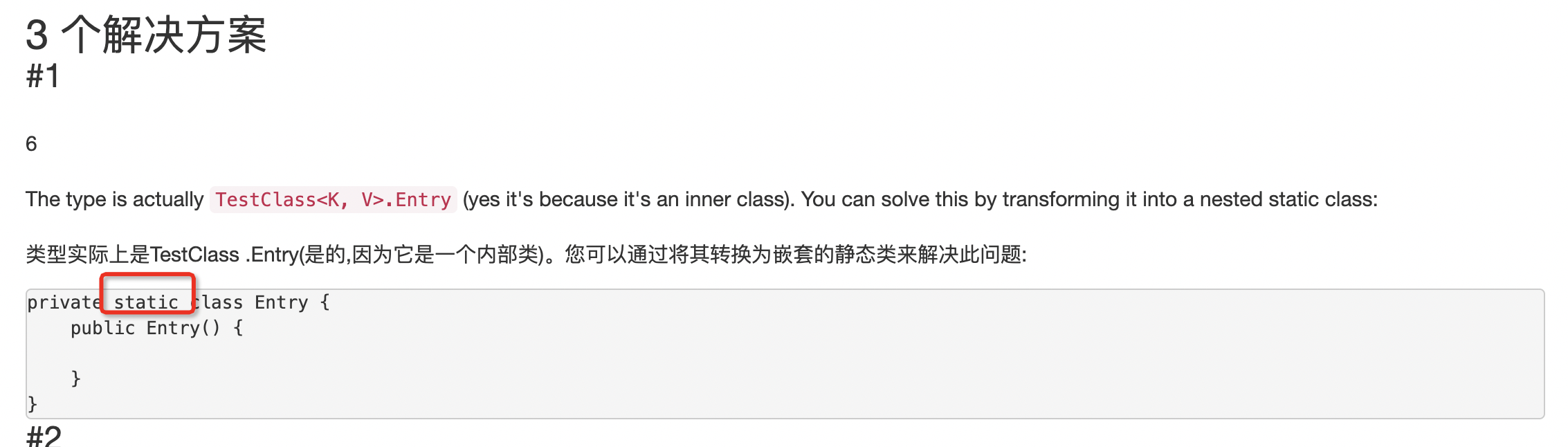

mysql
为什么设置db gmt_modified字段默认值后未生效,还是得显示传值?
一般gmt_modified字段这么设置
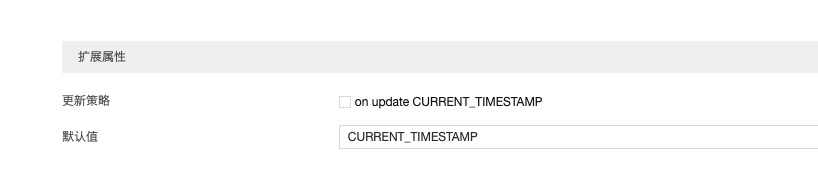
gmt_modified字段这么设置
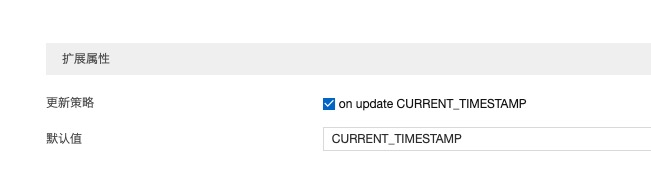
但db insert 遇到gmtCreate还是得显示传值,否则报sql错误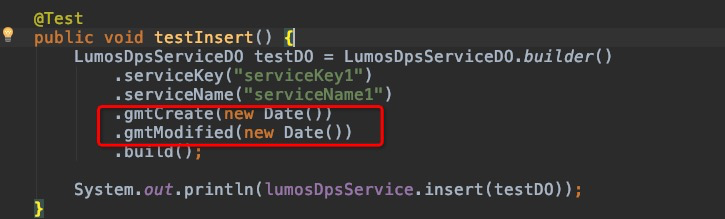
原因是,insert的时候显示配置了要insert gmt_create列,而实际传的是null,当然会报错啦。解决办法:insert语句不要包含gmt_create列就好啦。
运维经验
如何修改JVM参数?build 遇到 OOM问题?
https://blog.csdn.net/ahwsk/article/details/89921425
其他
postman
需要在heade中设置Cookie参数,从浏览器的network中找一个请求,copy下cookie。注意:不能采用 浏览器里的copy value,需要直接自己选择复制
否则可能出现空白字符,实际copy成字符串后会是%%

若有收获,就点个赞吧
0 人点赞
