如何设计一个朋友圈的发布和浏览过程
以wx为例,考虑到这么大的用户体量,如何兼顾发送和浏览的效率。描述表结构设计和从系统角度描述整体流程。
核心要解决的问题:接收方刷朋友圈时的效率问题。
方案:采用写扩散机制。在发送方发消息的时候,不止写消息表,还要写时间轴表,将所有好友的时间轴均插入消息ID。这样保障用户在读朋友圈的时候的查询性能。
https://www.jianshu.com/p/68a87d7f0ea9 https://max.book118.com/html/2017/0321/96300396.shtm
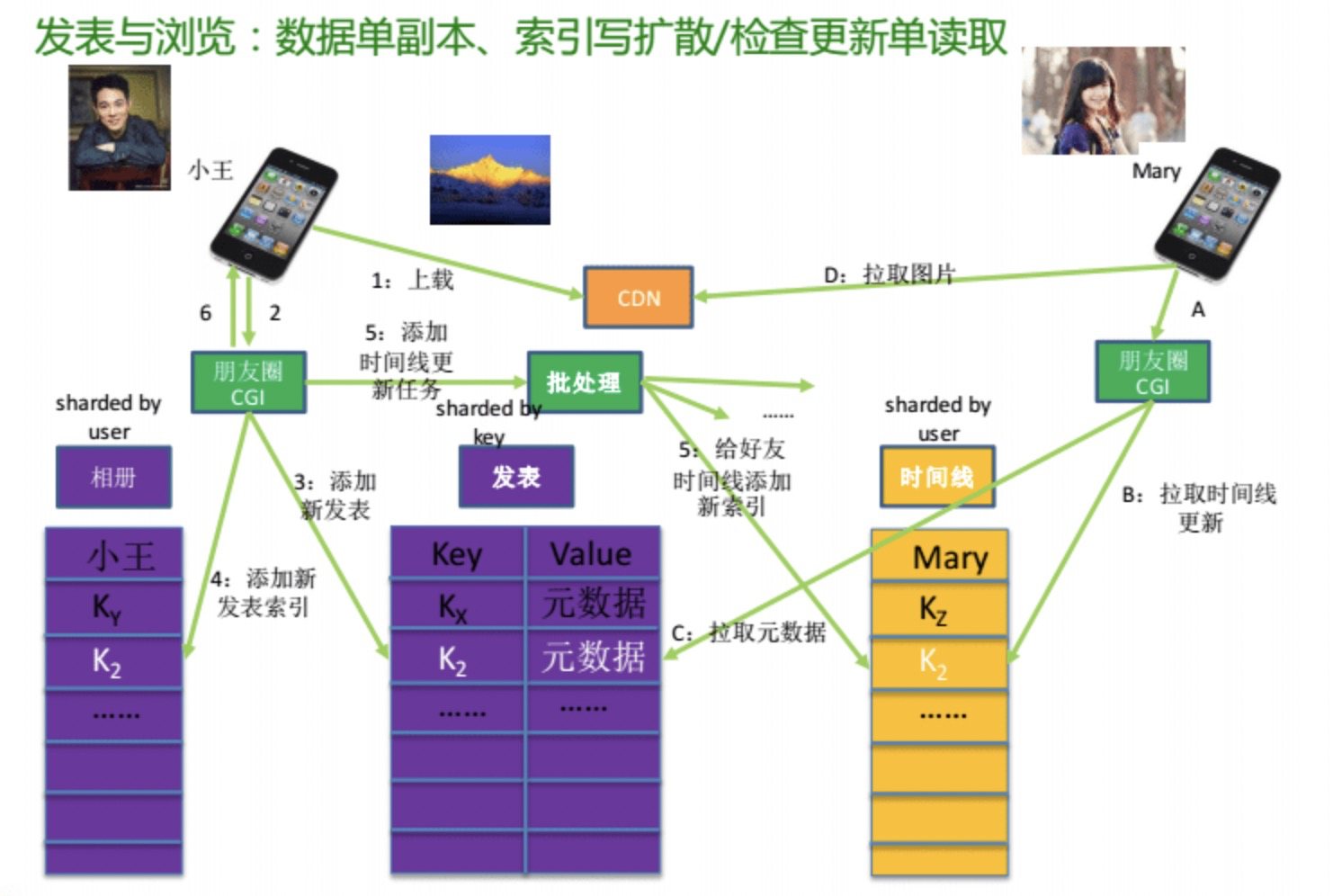
这里举例说明一下,两个用户小王和Mary(如下图)。小王和Mary各自有各自的相册,可能在同一台服务器上,也可能在不同的服务器上。现在小王上传了一张图片到自己的朋友圈。上传图片不经过微信后台服务器,而是直接上传到最近的腾讯CDN节点,速度非常快。图片上传到该CDN后,小王的微信客户端会通知微信的朋友圈CDN:这里有一个新的发布(比如叫K2),这个发布的图片URL是什么,谁能看到这些图片,等等此类的元数据,来把这个发布写到发布的表里。 在发布的表写完之后,会把这个K2的发布索引到小王的相册表里。所以相册表其实是很小的,里面只有索引指针。相册表写好了之后,会触发一个批处理的动作。这个动作就是去跟小王的每个好友说,小王有一个新的发布,请把这个发布插入到每个好友的时间线里面去。
Mary上朋友圈了,而Mary是小王的一个好友。Mary拉自己的时间线的时候,时间线会告诉到有一个新的发布K2,然后Mary的微信客户端就会去根据K2的元数据去获取图片在CDN上的URL,把图片拉到本地。
在这个过程中,发布是很重的,因为一方面要写一个自己的数据副本,然后还要把这个副本的指针插到所有好友的时间线里面去。如果一个用户有几百个好友的话,这个过程会比较慢一些。这是一个单数据副本写扩散的过程。但是相对应的,读取就很简单了,每一个用户只需要读取自己的时间线表,就这一个动作就行,而不需要去遍历所有好友的相册表。
使用写扩散的原因是,如果使用读是很容易失败的,一个用户如果要去读两百个好友的相册表,极端情况下可能要去两百个服务器上去问,这个失败的可能性是很大的。但是写失败了就没关系,因为写是可以等待的,写失败了就重新去拷贝,直到插入成功为止。

若有收获,就点个赞吧
0 人点赞
