Classifying your cells
Load your data
library(monocle)library(garnett)# load in the data# NOTE: the 'system.file' file name is only necessary to read in# included package data#mat <- Matrix::readMM(system.file("extdata", "exprs_sparse.mtx", package = "garnett"))fdata <- read.table(system.file("extdata", "fdata.txt", package = "garnett"))pdata <- read.table(system.file("extdata", "pdata.txt", package = "garnett"), sep="\t")row.names(mat) <- row.names(fdata)colnames(mat) <- row.names(pdata)# create a new CDS objectpd <- new("AnnotatedDataFrame", data = pdata)fd <- new("AnnotatedDataFrame", data = fdata)pbmc_cds <- newCellDataSet(as(mat, "dgCMatrix"),phenoData = pd,featureData = fd)# generate size factors for normalization laterpbmc_cds <- estimateSizeFactors(pbmc_cds)
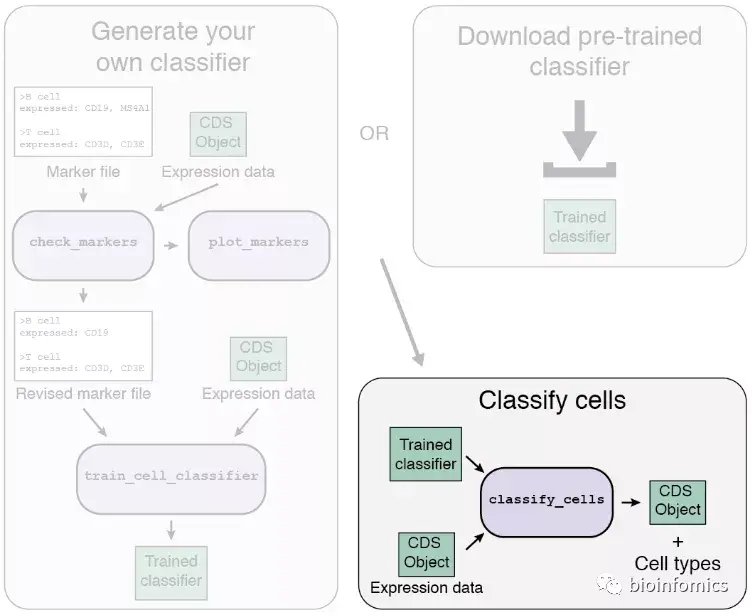
构建好细胞分类器之后,我们就可以使用classify_cells函数对细胞进行分类了。该函数主要包含以下参数:
cds: 包含基因表达数据的CDS输入对象。classifier: 使用Garnett训练获得的garnett_classifier分类器。db: 是用于转换基因id的Bioconductor注释db类包的必要参数。例如,对于人类使用org.Hs.eg.db。cluster_extend: 该参数告诉Garnett是否创建第二组分配,以将分类扩展到相同cluster群中的细胞。我们可以在“garnett_cluster”列的pData表中提供分群的id,也可以让Garnett计算分群并填充该列。cds_gene_id_type:该参数告诉Garnett输入的CDS对象中基因id的格式。默认是“ENSEMBL”。
注意: 如果不提供“garnett_cluster”列,并使用一个非常大的数据集将cluster_extend设置为TRUE,则此函数的运行速度将大大降低。为了方便起见,Garnett会将其计算出的cluster集群保存为“garnett_cluster”,因此如果再次运行该函数,其运算速度会更快。
使用classify_cells函数对细胞进行分类后,在返回的CDS对象中会包含一个Garnett分类的新列(如果cluster_extend = TRUE,则返回两个),我们可以使用pData函数进行查看。
library(org.Hs.eg.db)
# 使用classify_cells函数基于训练好的分类器进行细胞分类
pbmc_cds <- classify_cells(pbmc_cds, pbmc_classifier,
db = org.Hs.eg.db,
cluster_extend = TRUE,
cds_gene_id_type = "SYMBOL")
# 查看分类的结果
head(pData(pbmc_cds))
# CellSample tsne_1 tsne_2 Size_Factor garnett_cluster cell_type cluster_ext_type
#AAGCACTGCACACA-1 CD19+BCells 3.840315 12.084191 0.5591814 1 B cells B cells
#GGCTCACTGGTCTA-1 CD19+BCells 9.970962 3.505393 0.5159340 1 Unknown B cells
#AGCACTGATATCTC-1 CD19+BCells 3.459529 4.935273 0.6980284 1 B cells B cells
#ACACGTGATATTCC-1 CD19+BCells 1.743949 7.782671 0.8156310 2 B cells B cells
#ATATGCCTCTGCAA-1 CD19+BCells 5.783448 8.558898 1.1153280 1 B cells B cells
#TGACGAACCTATTC-1 CD19+BCells 10.792853 10.585274 0.6494699 3 B cells B cells
table(pData(pbmc_cds)$cell_type)
# B cells CD4 T cells CD8 T cells T cells Unknown
# 207 129 61 164 239
table(pData(pbmc_cds)$cluster_ext_type)
# B cells CD4 T cells T cells
# 403 190 207
library(ggplot2)
# 对分类结果进行可视化
qplot(tsne_1, tsne_2, color = cell_type, data = pData(pbmc_cds)) + theme_bw()
qplot(tsne_1, tsne_2, color = cluster_ext_type, data = pData(pbmc_cds)) + theme_bw()
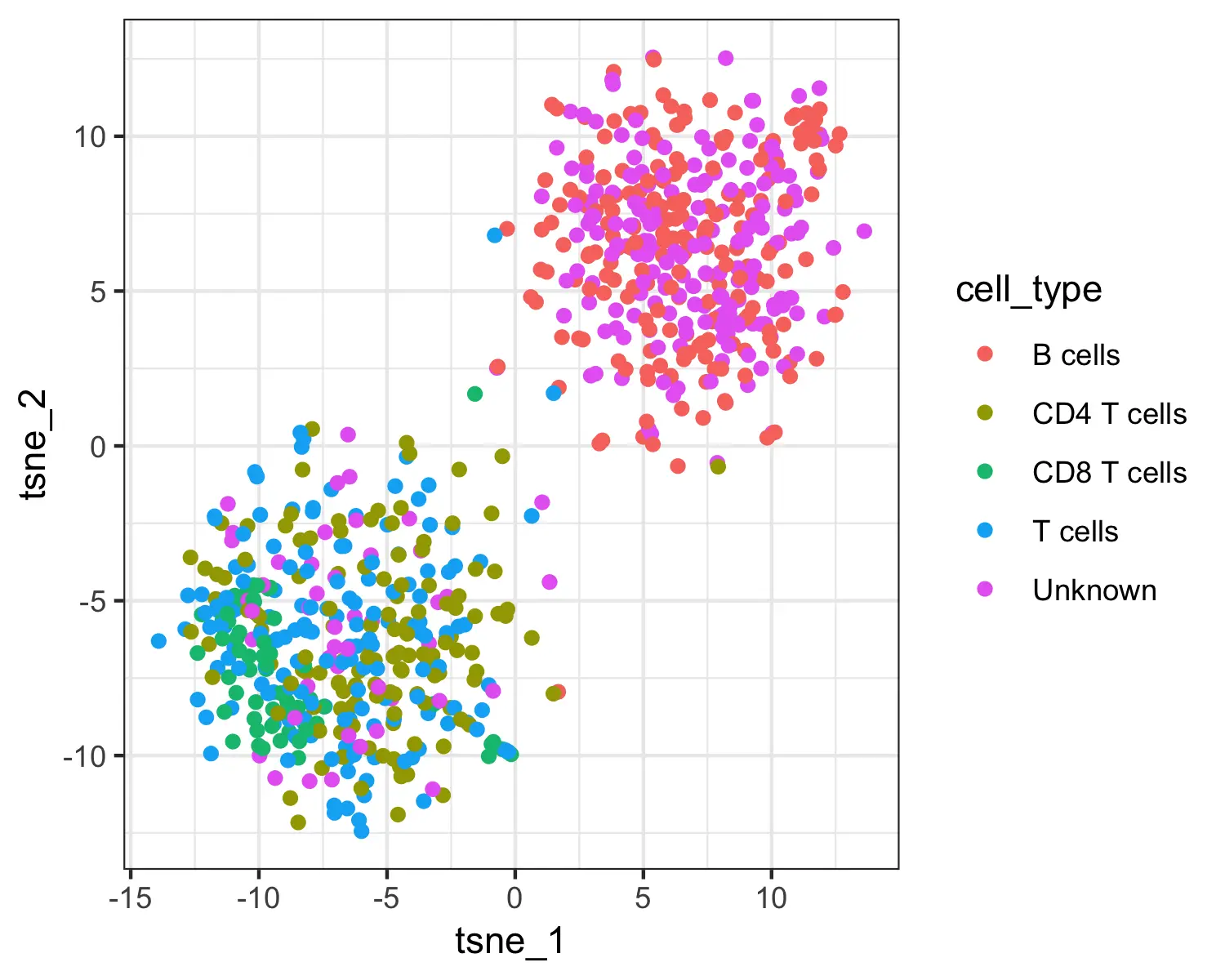
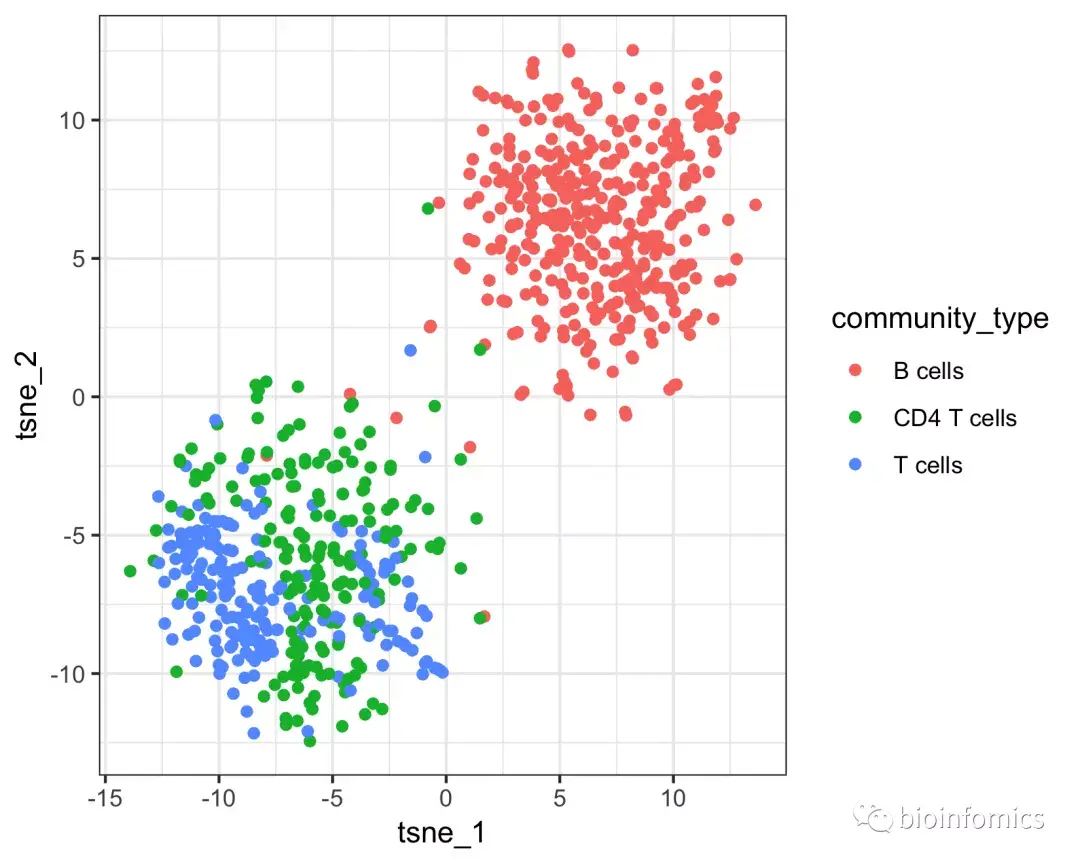
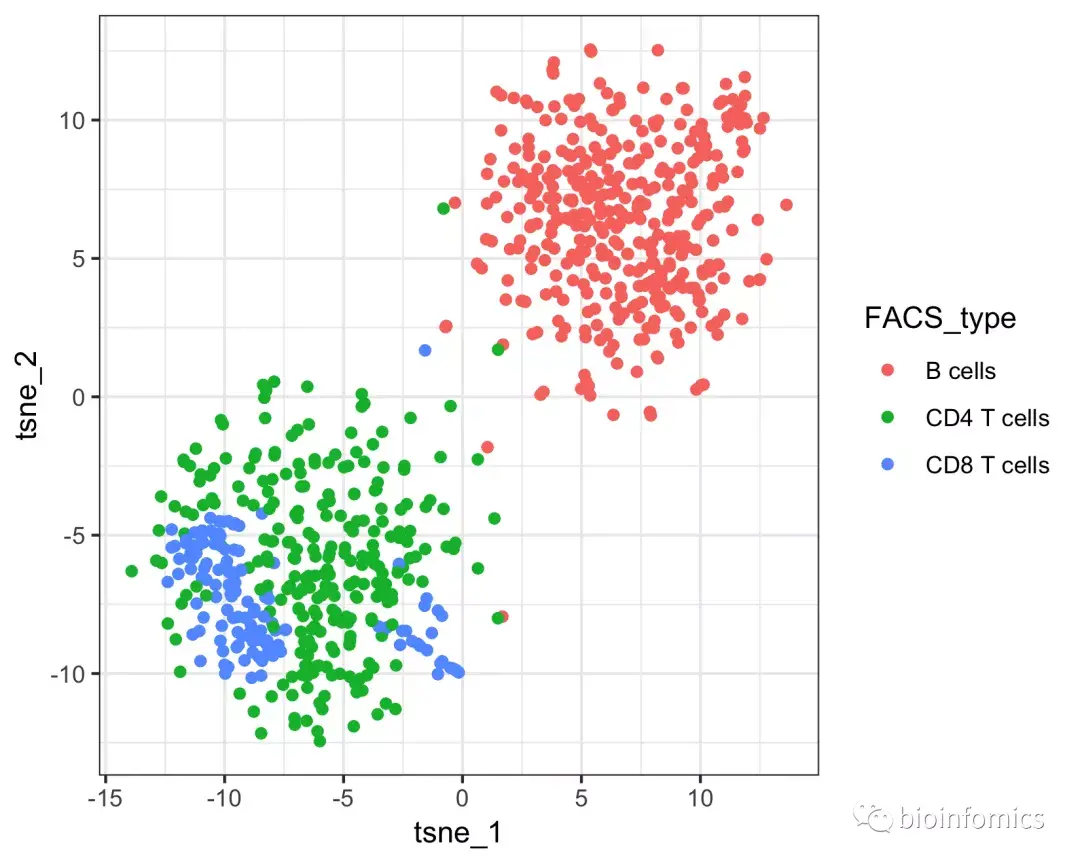
上图中第一个图显示了Garnett的细胞类型分配,第二张图显示了Garnett的cluster群扩展类型分配。我们可以看到,在这些cluster集群中T细胞子集(CD4和CD8)并没有很好地分离开。因此,在计算cluster集群扩展类型时,Garnett将层次结构备份到更可靠的“T细胞”分配中。
因为此示例数据来自FACS排序的细胞样本,所以我们可以将Garnett的分类结果与“真实的”细胞类型进行比较。
# 查看FACS排序的细胞分类结果
qplot(tsne_1, tsne_2, color = FACS_type, data = pData(pbmc_cds)) + theme_bw()
Troubleshooting
Common marker file errors
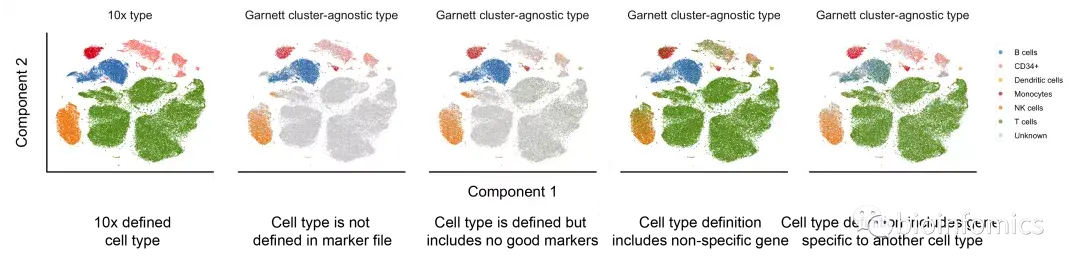
这里,我们提供了一些常见的标记文件错误和Garnett分类的潜在结果的示例。在上图中,我们使用10x PBMC version 2 (V2)的数据进行分类器的训练,然后使用该分类器对上述的10x PBMC version 1 (V1)数据进行细胞分类。第一个面板由基于FACS排序的细胞类型进行分配着色,其余的面板由Garnett集群无关的细胞类型分配着色。
- A cell type is missing from the marker file. 例如,在PBMC标记文件中,不包括T细胞定义(面板2)。我们发现,通常Garnett会将缺失的细胞类型标记为“Unknown”。
- A cell type is defined but includes no good specific markers. 例如,在PBMC标记文件中,仅使用CD4而不用CD3来定义T细胞(面板3)。在这种情况下,我们发现Garnett只标记了一部分T细胞,而没有标记其余细胞。
- A gene that is not specific and widely expressed is used to define a cell type. 例如,如果我们将MALAT1 (PBMC数据集中表达最多的转录本)添加到T细胞定义(面板4)中,在这种情况下,我们会发现每种细胞类型最终都在真实细胞类型和T细胞之间混合分配。在另一种情况下,包含一个广泛表达的非特异性基因可能会导致Garnett根本找不到足够的训练样本,因为它会认为所有细胞都是模棱两可的(因为它们会表达其他marker基因和非特异性的基因)。
- A cell type definition includes genes that are specific to another cell type. 例如,如果我们将B细胞的最佳标记(CD79A)添加到T细胞的定义中(面板5)。我们会发现B细胞簇中包含了B细胞和T细胞和混合细胞类型分配,但是其余的细胞类型的标签大多没有变化。
My species doesn’t have an AnnotationDbi-class database
如果我们使用的物种没有可用的AnnotationDbi类数据库,则Garnett将无法在基因ID类型之间进行转换。但是,我们仍然可以使用Garnett进行细胞分类。我们可以设置db =’none’,然后确保在标记文件中使用与CDS对象相同的基因ID类型。当设置db =’none’时,Garnett将忽略基因ID类型的参数。
More troubleshooting to come…
Citation
If you use Garnett to analyze your experiments, please cite:
citation("garnett")
# Hannah A. Pliner, Jay Shendure & Cole Trapnell (2019). Supervised classification enables rapid annotation of cell atlases. Nature Methods
#
# A BibTeX entry for LaTeX users is
#
# @Article{,
# title = {Supervised classification enables rapid annotation of cell atlases},
# journal = {Nature Methods},
# year = {2019},
# author = {Hannah A. Pliner and Jay Shendure and Cole Trapnell},
# }
#
参考来源:https://cole-trapnell-lab.github.io/garnett/docs/#2-classifying-your-cells

若有收获,就点个赞吧
0 人点赞
