一、窗口函数是什么?
1. 窗口函数有什么用?
在实际业务中,用于解决的需求有:
- 用于分区排序
- 动态Group By
- Top N
- 累计计算
- 层次查询**
2. 窗口函数的分类
| 一级分类 | 二级分类 | 函数名称 | 说明 | | :—-: | :—-: | :—-: | :—-: | | 聚合类函数 | |
- sum()
- avg()
- count()
- max()
- min()
| 聚合函数可用于窗口函数 | | 非聚合类函数
(专用窗口函数) | 排序函数 | RANK() | 当前行在其分区中的排名,有空隙。 | | | | DENSE_RANK() | 当前行在其分区中的排名,没有空隙。(dense译为“密集的”,因为没有空隙,所以密集) | | | | ROW_NUMBER() | 分区内当前行数。 | | | 定位函数 | FIRST_VALUE() | 窗口框架第一行的参数值。 | | | | LAST_VALUE() | 窗口框架最后一行的参数值。 | | | | NTH_VALUE() | 窗口框架第N行的参数值。(nth译为“第N个的”) | | | 比例函数 | PERCENT_RANK() | 排名百分比值。 | | | | CUME_DIST() | 累计分布值。 | | | 分桶函数 | NTILE(n) | 当前行在其分区内的桶号。 | | | 偏移函数 | LAG(col,n,default) | 分区内滞后于当前行的参数值。 | | | | LEAD(col,n,default) | 从行开始的参数值领先于分区内的当前行。 |
二、窗口函数如何使用?
1. 窗口函数的基本格式
<窗口函数> over (partition by <用于分组的列名>order by <用于排序的列名>)
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。接下来,就结合实例,介绍几种窗口函数的用法。
2. 实例
1. 排序函数RANK()、DENSE_RANK()和ROW_NUMBER()的区别
以下表为例
| ID | val |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 6 | 3 |
| 7 | 4 |
| 8 | 4 |
| 9 | 5 |
selectval,row_number() over (order by val) as "row_number" ,rank() over (order by val) as "rank",dense_rank() over (order by val) as "dense_rank"from numbers+------+------------+------+------------+| val | row_number | rank | dense_rank |+------+------------+------+------------+| 1 | 1 | 1 | 1 || 1 | 2 | 1 | 1 || 2 | 3 | 3 | 2 || 3 | 4 | 4 | 3 || 3 | 5 | 4 | 3 || 3 | 6 | 4 | 3 || 4 | 7 | 7 | 4 || 4 | 8 | 7 | 4 || 5 | 9 | 9 | 5 |+------+------------+------+------------+
三个排序函数区别:
row_number(): 显示的是行号。rank():出现并列排名时,每一行都会占位,比如“1,1,2,3,3,3,3,4”rank的排名为“1,1,3,4,4,4,4,7”。dense_rank():出现并列排名时,相同排名的只占一个位置,比如“1,1,2,3,3,3,3,4”dense_rank的排名为“1,1,2,3,3,3,3,4”。此外,如果同时引用多个窗口函数的“窗口范围相同”,也可用别名代替,格式为
select
<窗口函数1> over <窗口别名>,
<窗口函数2> over <窗口别名>,
<窗口函数3> over <窗口别名>
from <表名>
window <窗口别名> as (artition by <用于分组的列名> order by <用于排序的列名>)
则上述比较三者区别的SQL也可写作
select
val,
row_number() over w as "row_number" ,
rank() over w as "rank",
dense_rank() over w as "dense_rank"
from numbers
window w as (order by val)
2. 定位函数FIRST_VALUE()、LAST_VALUE()和NTH_VALUE()的实例。
mysql> SELECT
time, subject, val,
FIRST_VALUE(val) OVER w AS 'first',
LAST_VALUE(val) OVER w AS 'last',
NTH_VALUE(val, 2) OVER w AS 'second',
NTH_VALUE(val, 4) OVER w AS 'fourth'
FROM observations
WINDOW w AS (PARTITION BY subject ORDER BY time);
+----------+---------+------+-------+------+--------+--------+
| time | subject | val | first | last | second | fourth |
+----------+---------+------+-------+------+--------+--------+
| 07:00:00 | st113 | 10 | 10 | 10 | NULL | NULL |
| 07:15:00 | st113 | 9 | 10 | 9 | 9 | NULL |
| 07:30:00 | st113 | 25 | 10 | 25 | 9 | NULL |
| 07:45:00 | st113 | 20 | 10 | 20 | 9 | 20 |
| 07:00:00 | xh458 | 0 | 0 | 0 | NULL | NULL |
| 07:15:00 | xh458 | 10 | 0 | 10 | 10 | NULL |
| 07:30:00 | xh458 | 5 | 0 | 5 | 10 | NULL |
| 07:45:00 | xh458 | 30 | 0 | 30 | 10 | 30 |
| 08:00:00 | xh458 | 25 | 0 | 25 | 10 | 30 |
+----------+---------+------+-------+------+--------+--------+
每个函数都使用当前组内指定行对应的值,具体为:
FIRST_VALUE()取的是每个组内的首行,LAST_VALUE()取的是每个组内的尾行,- 对于
NTH_VALUE()当前组并不总是包含所请求的行;在这种情况下,返回值是NULL。
3. 比例函数CUME_DIST()和PERCENT_RANK()
select
val,
row_number() over w as "row_number",
cume_dist() over w as "cume_dist",
percent_rank() over w as "percent_rank"
from numbers
window w as (order by val);
+------+------------+--------------------+--------------+
| val | row_number | cume_dist | percent_rank |
+------+------------+--------------------+--------------+
| 1 | 1 | 0.2222222222222222 | 0 |
| 1 | 2 | 0.2222222222222222 | 0 |
| 2 | 3 | 0.3333333333333333 | 0.25 |
| 3 | 4 | 0.6666666666666666 | 0.375 |
| 3 | 5 | 0.6666666666666666 | 0.375 |
| 3 | 6 | 0.6666666666666666 | 0.375 |
| 4 | 7 | 0.8888888888888888 | 0.75 |
| 4 | 8 | 0.8888888888888888 | 0.75 |
| 5 | 9 | 1 | 1 |
+------+------------+--------------------+--------------+
cume_dist()累计分布值,取值范围(0, 1]左开右闭,返回一个值在一组值中的累积分布。算法为:dist/rows,其中dist是分区尾行的行数。如val=3的分区,dist=6,rows=9,cume_dist=6/9=0.666。该函数应与ORDER BY一起使用,如果不使用ORDER BY,其值为1。
percent_rank()累计百分比值,取值范围[0, 1]左右都闭,返回分区值小于当前行中值的百分比。算法为:(rank-1)/(rows-1),其中rank是分区首行的行数,rows是总行数。如:val=3的分区,rank=4,rows=9,percent_rank=(4-1)/(9-1)=3/8=0.375。该函数应与ORDER BY一起使用。如果不使用ORDER BY,其值为0。
4. 分桶函数NTILE(n)
NTILE(N) OVER(ORDER BY col),参数N是分桶的个数,先按col排序,然后将结果平均放入N个桶中,桶号从1开始。
SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
NTILE(2) OVER w AS 'ntile2',
NTILE(4) OVER w AS 'ntile4'
FROM numbers
WINDOW w AS (ORDER BY val);
+------+------------+--------+--------+
| val | row_number | ntile2 | ntile4 |
+------+------------+--------+--------+
| 1 | 1 | 1 | 1 |
| 1 | 2 | 1 | 1 |
| 2 | 3 | 1 | 1 |
| 3 | 4 | 1 | 2 |
| 3 | 5 | 1 | 2 |
| 3 | 6 | 2 | 3 |
| 4 | 7 | 2 | 3 |
| 4 | 8 | 2 | 4 |
| 5 | 9 | 2 | 4 |
+------+------------+--------+--------+
当不能平均分配时,每组的记录数不能大于它上一组的记录数。如上述例子中,9个数,分为2桶和4桶,均无法整除。因此,分为2组时,分别为(5,4);分为4桶时,分别为(3,2,2,2)。
5. 偏移函数LAG(col,n,default)和LEAD(col,n,default)
lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率。
参数:col是待查找的字段,n是偏移的行数,默认是1,default是没有符合条件时的默认值,如不设置则显示null。
LAG()和LEAD()经常被用来计算行之间的差异。下面的查询显示了一组观测值,包括观测值、相邻的LAG()和LEAD()值,以及当前行和相邻行之间的差异。
SELECT
val,
lag ( val ) over w AS "lag",
lead ( val ) over w AS "lead",
val - lag ( val ) over w AS "lag_diff",
val - lead ( val ) over w AS "lead_diff"
FROM numbers
WINDOW w AS ( ORDER BY val );
+------+------+------+----------+-----------+
| val | lag | lead | lag_diff | lead_diff |
+------+------+------+----------+-----------+
| 100 | NULL | 124 | NULL | -24 |
| 124 | 100 | 125 | 24 | -1 |
| 125 | 124 | 200 | 1 | -75 |
| 200 | 125 | 200 | 75 | 0 |
| 200 | 200 | 315 | 0 | -115 |
| 315 | 200 | 335 | 115 | -20 |
| 335 | 315 | 545 | 20 | -210 |
| 545 | 335 | 785 | 210 | -213 |
| 758 | 545 | NULL | 213 | NULL |
+------+------+------+----------+-----------+
在这个例子中,LAG()和LEAD()调用分别使用默认的N和默认值1和NULL。
LAG()和LEAD()还可以用来计算总和而不是差值。比如这个数据集,它包含了斐波那契数列的前几个数字。
SELECT n FROM fib ORDER BY n;
+------+
| n |
+------+
| 1 |
| 1 |
| 2 |
| 3 |
| 5 |
| 8 |
+------+
下面的查询显示了与当前行相邻的行的LAG()和LEAD()值。它还使用这些函数将前几行和后几行的值加到当前行的值上。其效果是生成斐波那契数列中的下一个数字,以及之后的下一个数字。
SELECT
n,
LAG(n, 1, 0) OVER w AS 'lag',
LEAD(n, 1, 0) OVER w AS 'lead',
n + LAG(n, 1, 0) OVER w AS 'next_n',
n + LEAD(n, 1, 0) OVER w AS 'next_next_n'
FROM fib
WINDOW w AS (ORDER BY n);
+------+------+------+--------+-------------+
| n | lag | lead | next_n | next_next_n |
+------+------+------+--------+-------------+
| 1 | 0 | 1 | 1 | 2 |
| 1 | 1 | 2 | 2 | 3 |
| 2 | 1 | 3 | 3 | 5 |
| 3 | 2 | 5 | 5 | 8 |
| 5 | 3 | 8 | 8 | 13 |
| 8 | 5 | 0 | 13 | 8 |
+------+------+------+--------+-------------+
3.聚合函数作为窗口函数
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
我们来看一下窗口函数是聚合函数时,会出来什么结果:
select *,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表
得到结果: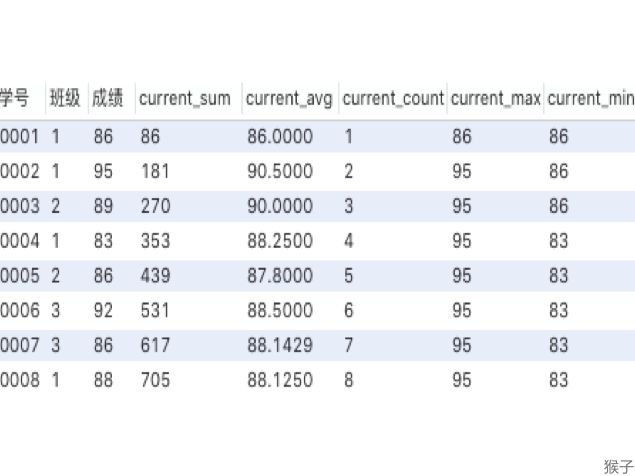
有发现什么吗?我单独用sum举个例子:
如上图,聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。比如0004号,在使用sum窗口函数后的结果,是对0001,0002,0003,0004号的成绩求和,若是0005号,则结果是0001号~0005号成绩的求和,以此类推。
不仅是sum求和,平均、计数、最大最小值,也是同理,都是针对自身记录、以及自身记录之上的所有数据进行计算,现在再结合刚才得到的结果(下图),是不是理解起来容易多了?
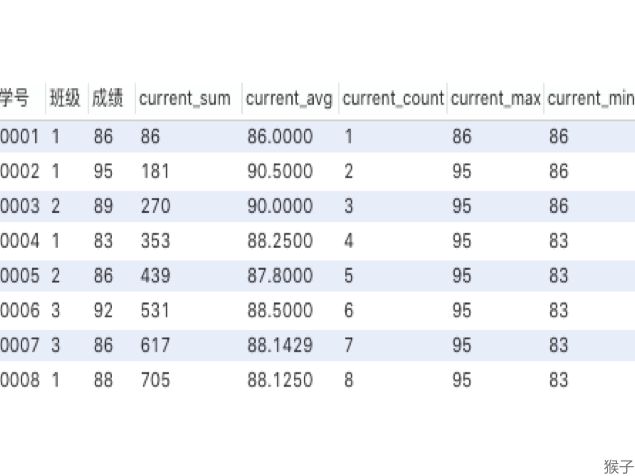
比如0005号后面的聚合窗口函数结果是:学号0001~0005五人成绩的总和、平均、计数及最大最小值。
如果想要知道所有人成绩的总和、平均等聚合结果,看最后一行即可。
这样使用窗口函数有什么用呢?
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
四.注意事项
partition子句可是省略,省略就是不指定分组,结果如下,只是按成绩由高到低进行了排序:
select *,
rank() over (order by 成绩 desc) as ranking
from 班级表
得到结果: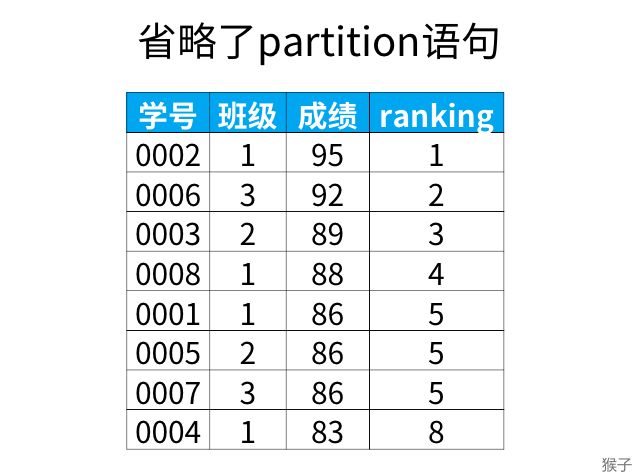
但是,这就失去了窗口函数的功能,所以一般不要这么使用。**

若有收获,就点个赞吧
0 人点赞
