一、数据分析模型
1. 首先要确认业务分析的对象
可分为3类
 |
 |
 |
|---|---|---|
| 商品/服务/产品 | 用户/客户 | 渠道/市场/活动 |
2. 从维度、指标、分析方法3方面,构建业务分析的模型
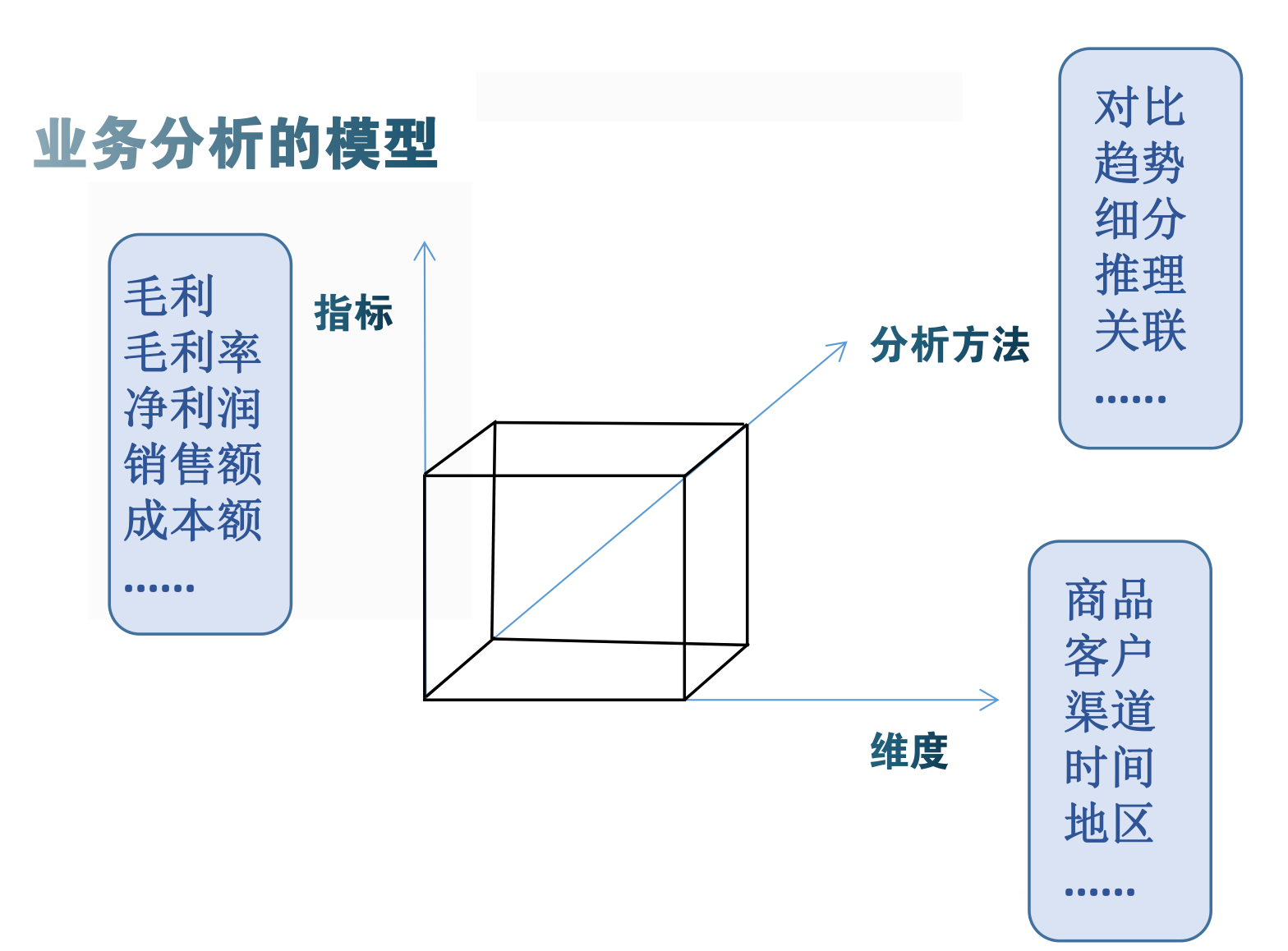
举例:分析毛利率的数据模型
具体分析过程见《半小时掌握finebi》
| 毛利率 = 毛利额 / 销售额 | 毛利额 = 销售额 - 成本额 |
|---|---|
| 销售额 | |
| 分析维度 | 分析方法 |
| 地区维度:省份?城市?门店? | 细分 |
| 产品维度:产品?业务?服务? | 对比、矩阵 |
| 时间维度:年?月?日?订单? | 趋势、细分 |
| 员工维度:销售?进货?人工? | 溯源 |
| 渠道维度:供应商?促销? | 对比、关联 |
| 价格维度:进货价格? | 对比 |
3. 业务数据从哪里来
- 销售数据:**存放于订单中**
- 毛利数据
- 销售数据
- 客单价数据
- 客户数据
- 产品数据:**存放于业务中**
- 产品类别数据
- 进货数据
- 库存数据
- 供应商数据
二、帕累托模型
1. 什么是帕累托模型?
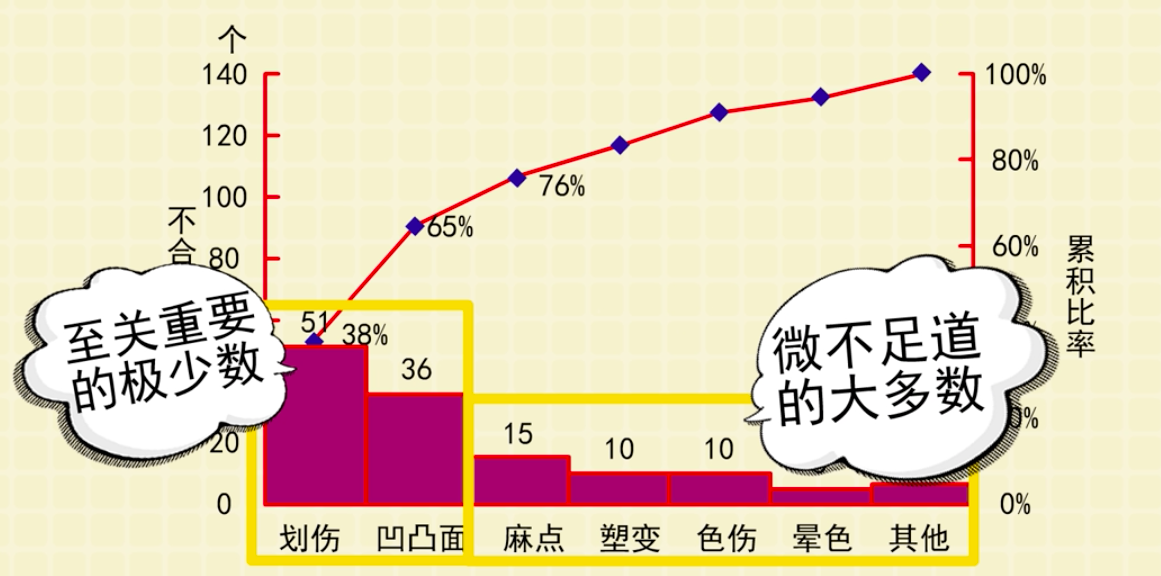
帕累托图是一种按发生频率大小顺序绘制的特殊直方图,故又名排列图、主次图。帕累托图与帕累托法则一脉相承,帕累托法则认为,相对少量的原因通常造成大多数的问题或缺陷,即80%的问题是由20%的原因导致的,故又称二八法则或80/20法则。帕累托图也用于汇总各种类型的数据。
2. 帕累托模型制作
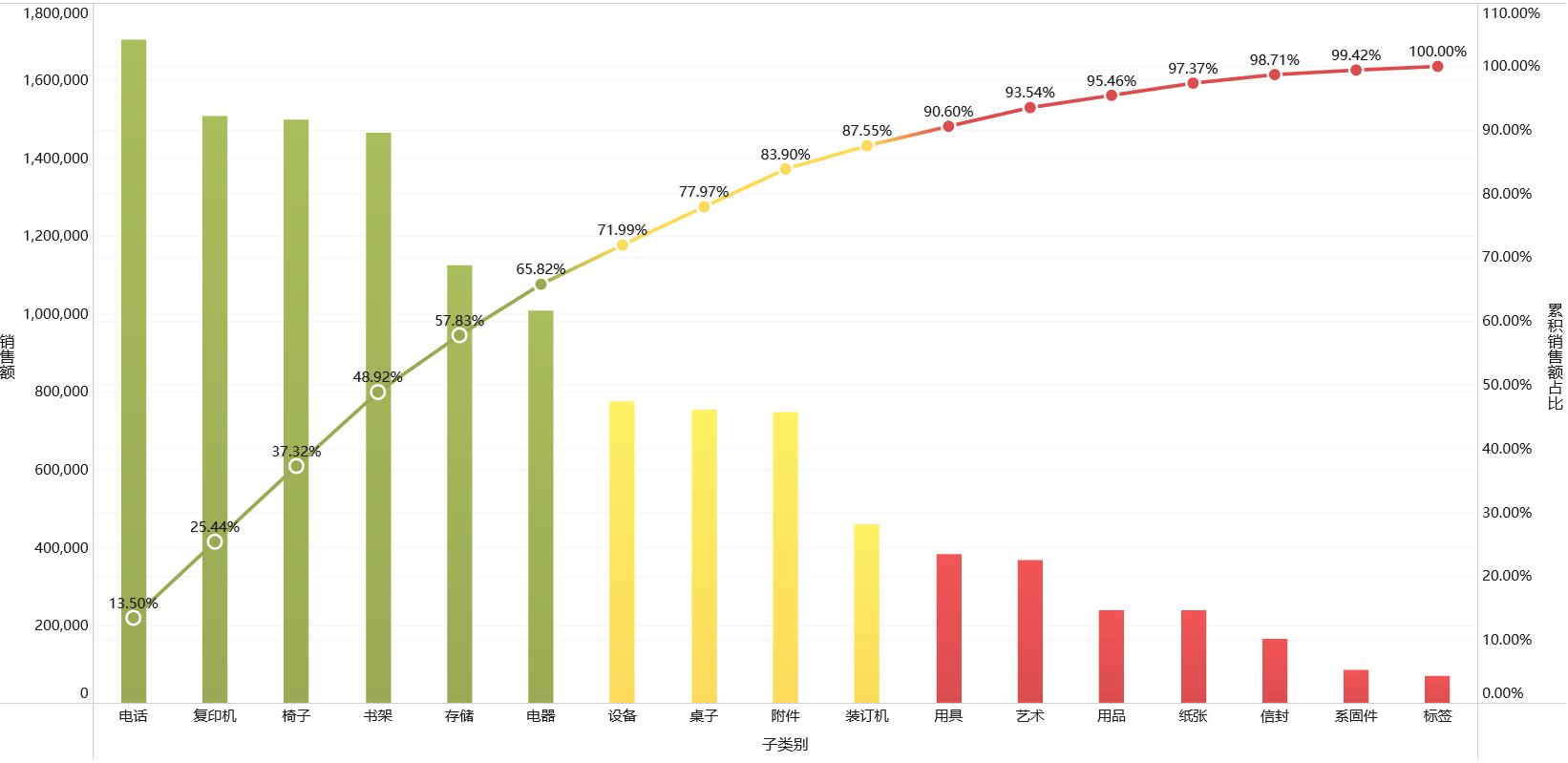 |
1. 按销售额降序排序 1. 计算累计销售额 1. 计算总销售额 1. 计算累计销售额占比 1. 产品归类 |
|---|---|
练习数据帕累托数据.zip
使用工具:FineBI
三、长尾模型
拼多多的成功
 |
10%的⼀⼆线城市消费潜力 VS 90%的三四线城市的消费潜力 |
|---|---|
长尾模型和帕累托模型的区别
| 帕累托模型 | 长尾模型 |
|---|---|
 |
 |
| 关注头部效应 集中力量干大事 优势资源投入 |
关注尾部效应 积少成多 低成本、低门槛 |
四、波士顿模型
1. 波士顿矩阵
根本目的:从市场增长和市场份额的维度为商品分类。
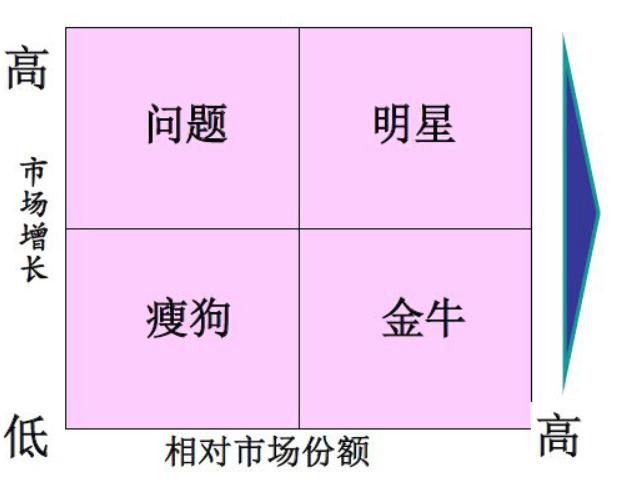 |
明星类:增长率高、占有率高,代表着十分成功的产品,是主打的明星产品; 金牛类:增长率低、占有率高,已经占据了市场但是没有发展空间的产品,属于现金牛产品; 问题类:增长率高、占有率低,说明用户需求高,但是本身产品有问题,需要改进优化; 瘦狗类:增长率低、占有率低,市场不认可的失败产品,需要尽快去除。 |
|---|---|
2. 波士顿矩阵的构成
|
- 销售维度
- 销售量
- 销售增长率(常用)
- 目标市场容量
- 竞争对手强弱
- 利润高低
|
- 产品维度
- 市场占有率(常用)
- 技术
- 设备
- 资金利用能力
| | —- | —- |
3. 波士顿模型的制作
- 确定维度(尽量选取毫无关联要素)
- 确定计算维度的指标
- 计算分界值
- 产品分类
练习数据,与帕累托数据.zip为同一数据源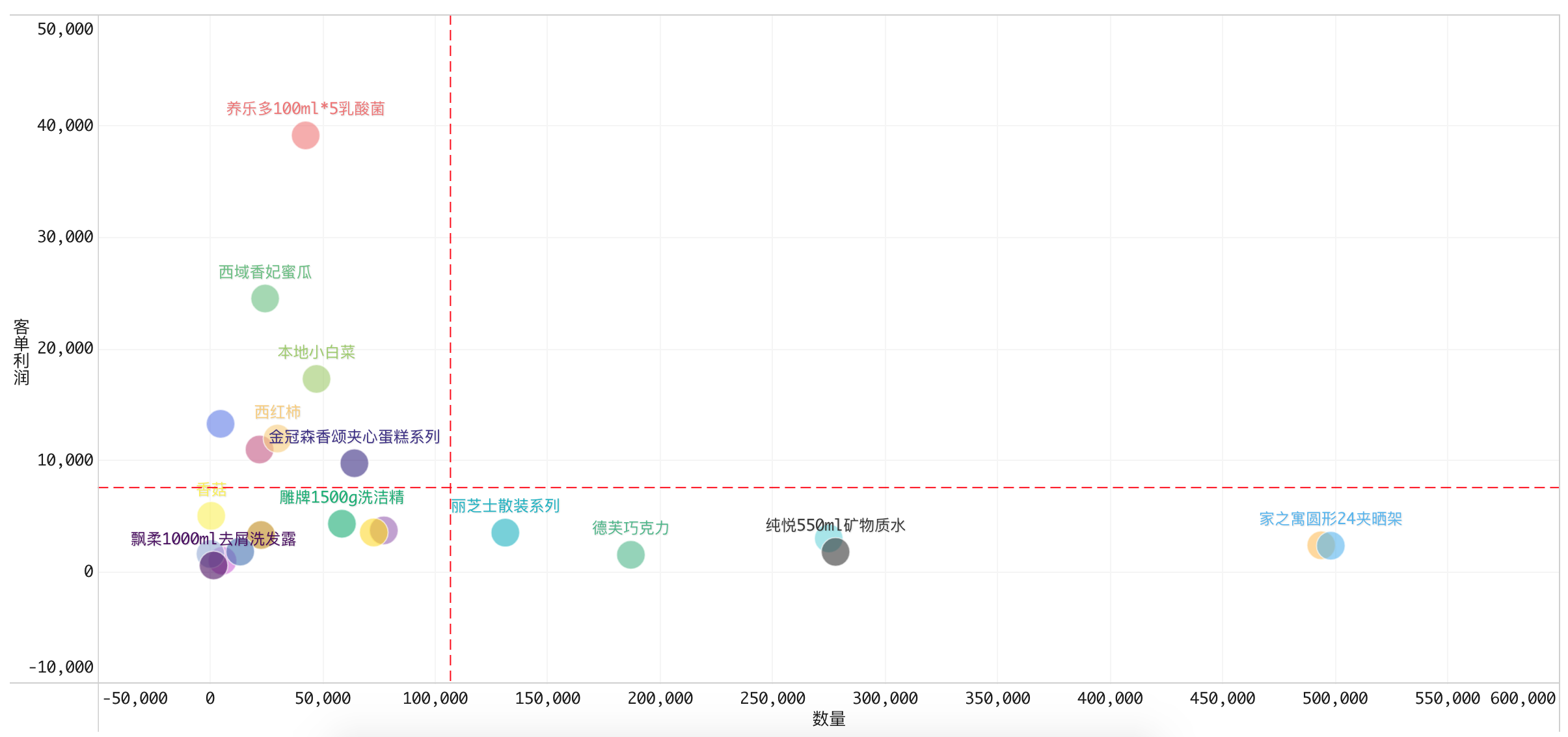
4. 波士顿矩阵图的分析
遵循波士顿矩阵的4个原则:月牙原则、黑球原则、对角原则、跃迁法则。
月牙原则
如果波士顿矩阵中的数据呈现月牙状,也就是明星、金牛、问题产品多,而瘦狗产品少,则说明企业的经营比较成功,产品结构的分布十分合理。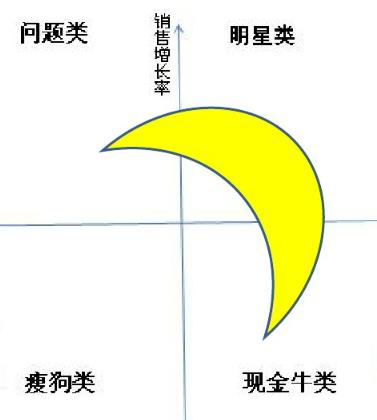
结合案例:练习数据的波士顿矩阵呈现的是反月牙🌛,没有明星类产品,瘦狗类象限集中了很多产品应该被出售或淘汰掉,应将资源集中现金牛和问题产品上。
黑球原则
如果在现金牛象限内几乎没有产品,则说明该企业几乎没有可以依靠的大盈利产品,整个企业可能会因为资金短缺、周转性差、投入产出不明显等原因而失败,这就是黑球原则。
结合案例:通过分析发现,练习数据中有6款现金牛产品,但缺少明星产品,所以应当对现有产品结构进行撤退、缩小的战略调整,考虑向其它事业渗透,开发新的事业。
对角原则
如果数据集中在第一象限,也就是“明星”型产品,这说明企业处于一个快速成长阶段;而数据越是集中于第三象限,也就是“瘦狗”型产品,说明企业的亏损程度就越大。
结合案例:练习数据的产品集中在瘦狗型象限,说明正在亏损,应做出及时调整。
跃迁原则
问题产品通常是一些投机性产品,带有较大的风险,可能利润率很高,但市场份额很小,但是它通过一定的战略规划调整,最后可以进入金牛产品。这意味着企业开始进入了一个良好的盈利模式之中,但是这一趋势移动速度的快与慢对整个公司的利润存在影响。
结合案例:通过分析发现,练习数据中有6款现金牛产品,同时“养乐多”和“西域香妃蜜瓜”属于客单利润高但销量低的产品,可考虑适当降价提升销量,将其打造成明星产品或现金牛产品。
五、购物篮模型
1. 购物篮模型
| 例1:火腿与泡面 | 例2:淘宝推荐 | |
|---|---|---|
 |
 |
 |
2. 购物篮模型的构成
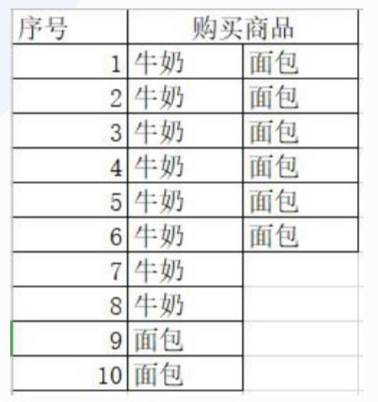 |
支持度:同时被购买的次数占总次数的概率 例如牛奶与面包的支持度是:6/10=0.6 置信度:购买了A又购买了B的概率 例如牛奶的置信度是:6/8=0.75 提升度:组合产品的支持度与单个商品购买概率乘积的比值* 例如牛奶被单独购买的概率是2/10=0.2,面包被单独购买的概率是2/10=0.2,所以牛奶与面包这个组合的提升度是:0.6/ ( 0.20.2 ) =15>1,所以这个组合是有效的 |
|---|---|
3. 购物篮模型的制作
步骤:
- 第一步:确定维度指标。商品两两交集、并集
- 第二步:计算置信度。交集除以某一个产品出现的总次数。
- 第三步:计算支持度。交集除以总订单数。
- 第四步:计算提升度。每种商品单独购买的概率=每种商品单独购买的次数
- 第五步:产品分类
https://www.jianshu.com/p/1f229740064f
https://www.jianshu.com/p/ff0eb70d31ec
https://blog.csdn.net/weixin_42057852/article/details/82661667?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param

若有收获,就点个赞吧
0 人点赞
