直方图,hist()
基于默认索引,对salary做直方图,看salary的分布情况
df.salary.plot.hist(bins=20)
out:
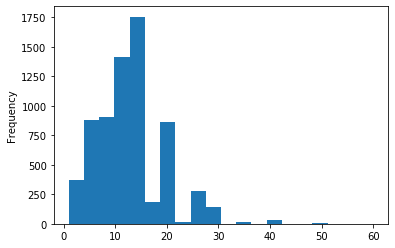
以education为横坐标,salary为纵坐标,制作直方图
- 按education分组,提取全部的salary ```python df.groupby(‘education’).apply(lambda x:x.salary)
out:
education
不限 1 1
6 1
13 1
18 1
20 1
..
硕士 6850 8
6856 20
6865 40
6870 25
6871 8
Name: salary, Length: 6874, dtype: int64
2. 利用unstack,将2级行索引转换为列索引更多关于unstack的用法,参考[https://blog.csdn.net/anshuai_aw1/article/details/82830916](https://blog.csdn.net/anshuai_aw1/article/details/82830916)```pythondf.groupby('education').apply(lambda x:x.salary).unstack()out:0 1 2 3 4 5 6 7 8 9 ... 6864 6865 6866 6867 6868 6869 6870 6871 6872 6873education不限 NaN 1.0 NaN NaN NaN NaN 1.0 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN博士 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN大专 NaN NaN NaN NaN NaN 1.0 NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN 6.0本科 NaN NaN 1.0 1.0 1.0 NaN NaN 1.0 1.0 1.0 ... 15.0 NaN 25.0 25.0 25.0 30.0 NaN NaN 4.0 NaN硕士 1.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN 40.0 NaN NaN NaN NaN 25.0 8.0 NaN NaN5 rows × 6874 columns
- T转置 ```python df.groupby(‘education’).apply(lambda x:x.salary).unstack().T
out:
education 不限 博士 大专 本科 硕士
0 NaN NaN NaN NaN 1.0
1 1.0 NaN NaN NaN NaN
2 NaN NaN NaN 1.0 NaN
3 NaN NaN NaN 1.0 NaN
4 NaN NaN NaN 1.0 NaN
… … … … … …
6869 NaN NaN NaN 30.0 NaN
6870 NaN NaN NaN NaN 25.0
6871 NaN NaN NaN NaN 8.0
6872 NaN NaN NaN 4.0 NaN
6873 NaN NaN 6.0 NaN NaN
6874 rows × 5 columns
4. 作图,bins参数控制直方图的列数,alpha参数设置透明度,stacked=True设置堆积图形,orientation='horizontal'水平图(直方图一般不用水平图)
```python
df.groupby('education').apply(lambda x:x.salary).unstack().T.plot.hist(bins=20,alpha=0.5,stacked=True)
out: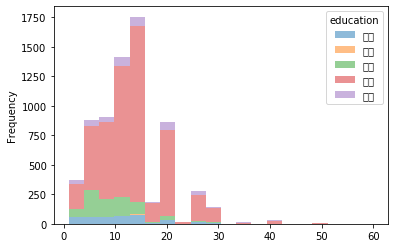

若有收获,就点个赞吧
0 人点赞
