1.1 语言处理器
| 处理器 | Compilers | Interpreters |
|---|---|---|
| 执行模式 | 将源代码翻译成目标语言编写的程序后再执行输入,产生输出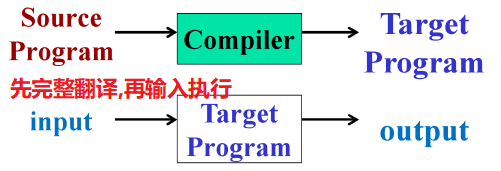 |
不翻译,直接利用输入执行源程序 |
| 执行速度 | 远快于解释器 | 较慢 |
| 错误诊断 | 弱于解释器 | 更好,因为逐个语句地执行源程序 |
| 语言代表 | Python | |
| 优点 | 经过“翻译”后,目标程序的执行速度更快 |
- 逐句执行,对源程序的错误诊断效果更好 - 更好的支持多平台,只需要不同平台的不同解释器就能跨平台的运行源程序 |
混合编译的语言: Java
- Java程序先被compiled成字节码(bytecode)作为中间形式
- 之后由不同平台的JVM将其interpret,直接根据输入产生输出,从而保证了Java程序可以跨平台执行
1.2 编译器的结构
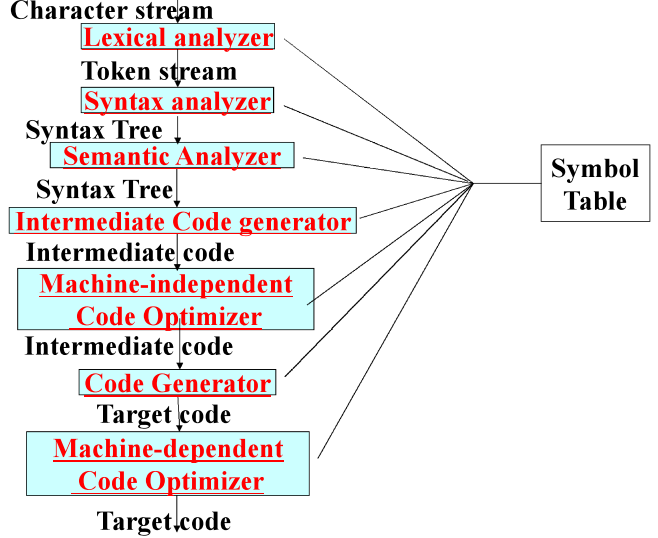
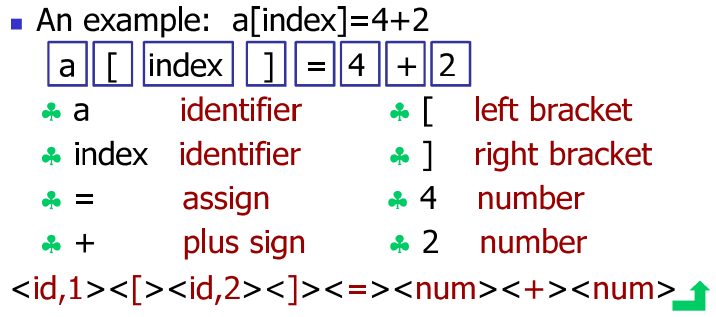
词法分析
| Lexical analysis,也称为scanning 输入: 源程序的字符流 转换: 有意义的词法单元(token),形式如下: <token-name, attribute-value> |
 |
|---|---|
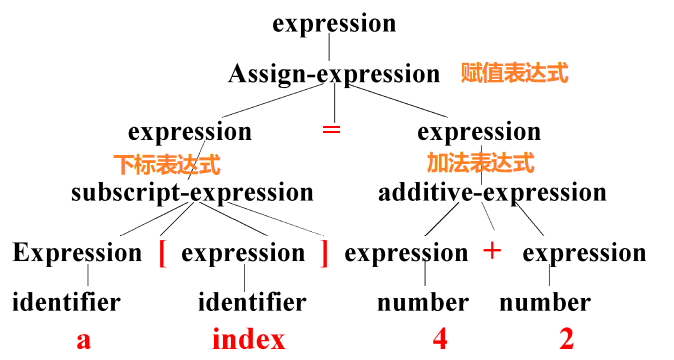
语法分析
| Syntax analysis,也称parsing 输入: token 输出: 分析树parse tree或语法树syntax tree |
 |
|---|---|
语义分析
| Semantic analysis
输入: 语法树和符号表中信息
执行:
- 类型检查: 比如数组下标一定为int
- 类型转换: 比如int和float一起运算,int->float
👉右图即为检查过程 | 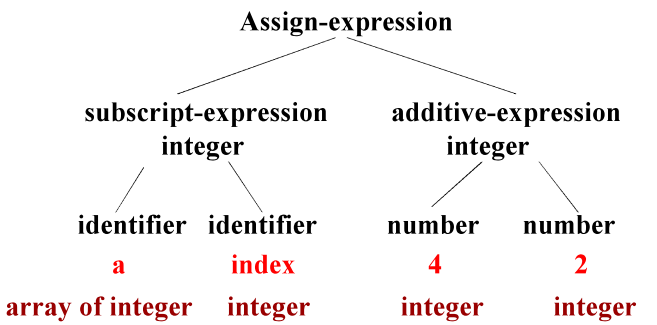 |
| —- | :—-: |
|
| —- | :—-: |
中间代码生成
| Intermediate
code generation
输入: 通过了syntax analysis和semantic analysis的源程序
输出: 明确的低级或类机器码的表示
👉右图以三地址码为例,每条指令最多三个运算分量,一个运算符 |  |
| —- | :—-: |
|
| —- | :—-: |
(机器无关)优化
| machine-independent optimization
- 机器无关的代码优化,只和源码有关
输入: 中间代码
输出: 优化后代码
👉右图进行常数折叠(机器无关) | 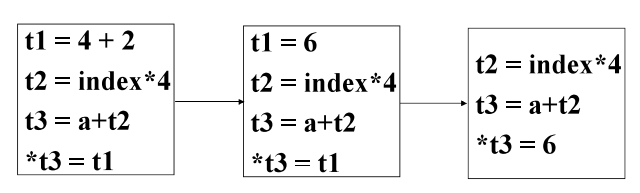 |
| —- | :—-: |
|
| —- | :—-: |
代码生成
| Code generation 输入: 中间代码 执行: 例如为变量选择寄存器或内存位置 输出: 可完成任务的机器指令(目标代码) |
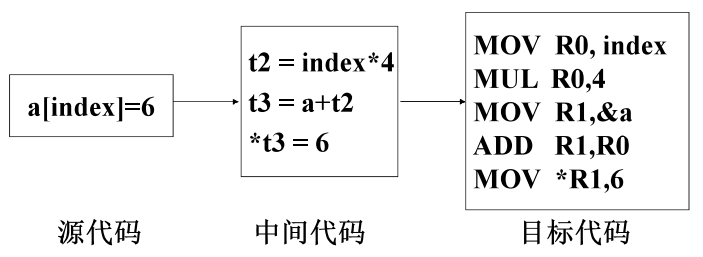 |
|---|---|
(机器相关)优化
| machine-dependent optimization
- 机器相关的代码优化,和目标代码有关
输入: 目标代码
输出: 优化后代码
👉右图进行指令优化 | 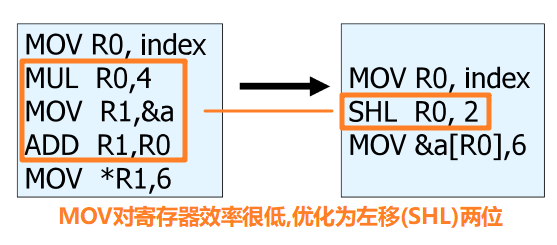 |
| —- | :—-: |
|
| —- | :—-: |
1.3 其余概念
前端/后端
根据当前操作的依赖,可把编译过程分为前后端
| 前端 | 后端 |
|---|---|
| 取决于”源代码”,包括: - 词法分析 - 语法分析 - 语义分析 - 中间代码生成 - 机器无关优化 |
取决于”目标语言”,包括: - 代码生成 - 机器相关优化 |
前后端中介: “中间代码” |
符号表
记录变量名和与之相关信息,如”类型,作用域,参数类型,参数数量,传参方法,返回类型”
遍(Pass)
将源码生成最终目标代码前的多次重复称为遍(pass),多个编译步骤组合成一遍,每遍一个输入文件,一个输出文件,大多数编译器使用不只一遍(比如前端步骤可以组合为一趟,后端步骤组合为一遍)

若有收获,就点个赞吧
0 人点赞
