1.4算法分析
1.4.3数学模型
一个程序运行的总时间主要和两点有关:
1. 执行每条语句的耗时
2. 执行每条语句的频率
前者取决于计算机,编译器和操作系统.后者取决于程序本身和输入,因此
总时间 = 每条语句耗时*每条语句频率 + 指令成本
1.4.3.1近似
在频率分析中可能产生冗长的表达式,如:

这种表达式中,首项之后的其他项都很小,常使用~符号忽略较小项
一般的近似方式

一般不会指定底数,因为常数a可以弥补
典型的近似
| 函数 | 近似 | 增长的数量级 |
|---|---|---|
| N³/6-N²/2+N/3 | ~N³/6 | N³ |
| N²/2-N/2 | ~N²/2 | N² |
| lgN+1 | ~lgN | lgN |
| 3 | ~3 | 1 |
常见的增长数量级函数
| 描述 | 函数 |
|---|---|
| 常数级别 | 1 |
| 对数级别 | logN |
| 线性级别 | N |
| 线性对数级别 | NlogN |
| 平方级别 | N² |
| 立方级别 | N³ |
| 指数级别 | 2^N |
1.4.3.2近似运行时间
近似运行时间的计算:根据执行频率将Java语句分块,计算出每种频率的首项近似,判定每条指令的执行成本并计算出总和.
关键现象:执行最频繁的指令—程序的内循环,决定了程序执行的总时间.
1.4.4增长数量级的分类
典型增长数量级函数
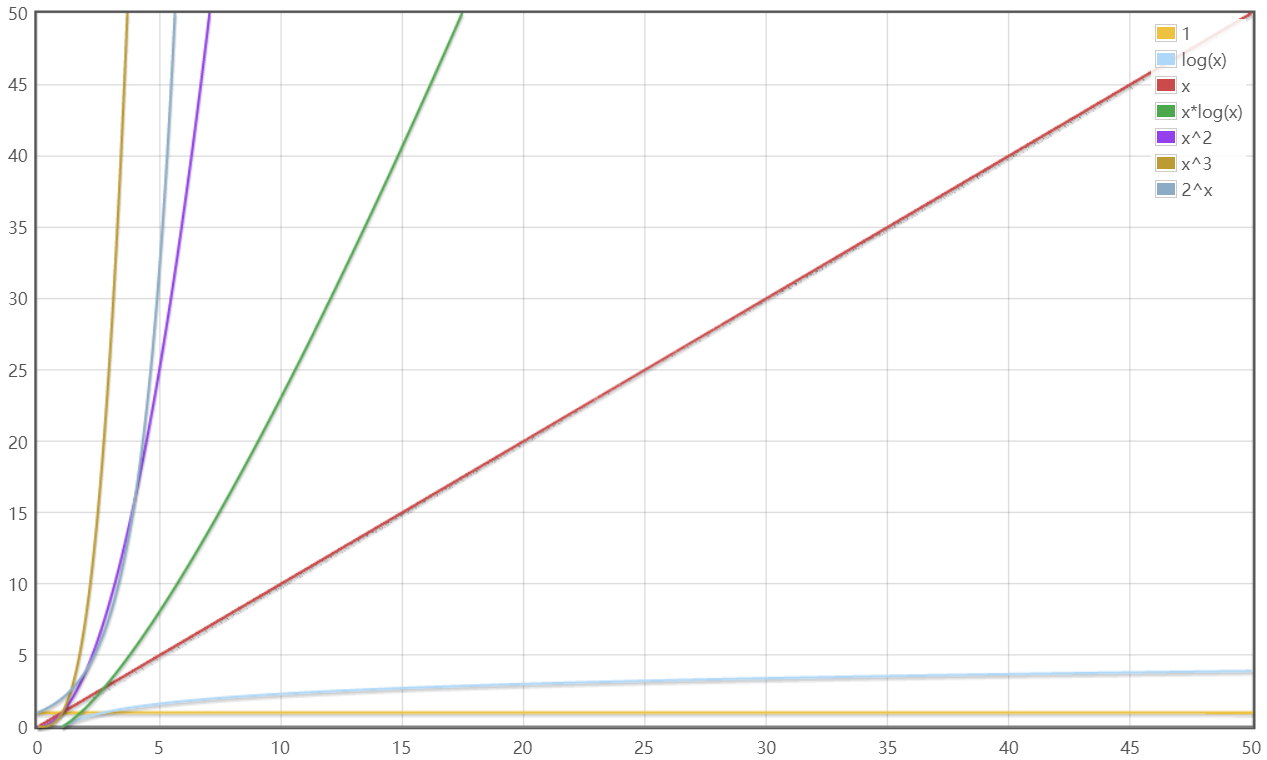
对增长数量级的常见假设总结
| 描述 | 增长的数量级 | 说明 | 举例 |
|---|---|---|---|
| 常数级别 | 1 | 普通语句 | 两数相加 |
| 对数级别 | logN | 二分策略 | 二分查找 |
| 线性级别 | N | 循环 | 找出最大值 |
| 线性对数级别 | NlogN | 分治 | 归并排序 |
| 平方级别 | N² | 双层循环 | 检查所有元素对 |
| 立方级别 | N³ | 三层循环 | 检查所有三元组 |
| 指数级别 | 2^N | 穷举查找 | 检查所有子集 |
注意:平方级别和立方级别的算法对于大规模的问题是不可用的,许多问题的平方级解法可以有线性对数级别算法代替
1.4.6倍率实验
倍率实验通过计算每次试验和上一次运行时间的比值(问题规模每次翻倍),反复运行直到比值趋近极限2b.可得结论:它们运行时间的增长数量级约为N**b**
常见的增长数量级函数(指数级别除外)均有如下结论:
1.4.7注意事项
1.4.7.1大常数
有事只保留首项是错误的,如2N²+cN中,如果c非常大,则首项近似就是错误的
1.4.7.2非决定性内循环
1.4.7.3指令时间
1.4.7.4系统因素
1.4.7.6对输入的强烈依赖
1.4.9内存
Java原始数据类型常见内存/需求
| 类型 | 字节 |
|---|---|
| boolean | 1 |
| byte | 1 |
| char | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
1.4.9.1对象
对象使用内存 = 所有实例变量内存 + 对象本身开销(一般为16字节,包括一个指向对象的类的引用,垃圾收集信息,同步信息,且一般内存的使用都会被填充为8字节的倍数)
一个Integer对象使用24字节开销 = 16字节对象开销 + 4字节int开销 + 4字节填充
1.4.9.2链表
嵌套的非静态(内部)类,如Node类,还需要额外8字节用于一个指向外部类的引用
一个Node对象使用40字节开销 = 16字节对象本身 + 指向Item和Node对象的引用各需要8字节 + 8字节额外开销
1.4.9.3数组
Java中数组被视为对象,数组都需要24字节的头信息(16字节对象开销+4字节保存长度+4字节填充);一个对象的数组实际上是对象的引用的数组,除了对象元素的开销还有对象引用的开销;而二维数组是一个数组的数组,每个数组都是一个对象
- 一般数组:一个N个int的数组开销(24+4N)字节 = 24字节头信息 + 4N数组元素开销
- 对象数组:一个含有N个Node对象的数组开销(24+40N+8N)字节 = 24字节头信息 + 40N对象元素开销 + 8N对象引用开销
- 二维数组:一个M*N的double类型数组开销()字节 = 24字节头信息 + 8M字节所有对象引用开销 + 24M元素数组开销 + 8MN所有double变量开销
1.4.9.4字符串对象
String对象在库中定义
public class String{private char[] value;private int offset;private int count;private int hash;...}
String的标准实现含有4个实例变量:一个指向字符数组的引用(8字节)和三个int值(各4字节),第一个int值描述的是字符数组中的偏移量,第二个int值是一个计数器(字符串的长度),第三个int值是一个散列值,因此
一个String对象开销40字节() = 16字节对象开销 + 3*4int开销 + 8字节引用开销 + 4个填充字节
但这只是除了字符数组之外字符串所需的内存空间,所有字符所需的内存需要另记,因为String的char数组常常在多个字符串之间共享,因为String对象不可变.这种设计使String的实现可以在多可对象有相同value[]数组时节省内存
1.4.9.5字符串的值和子字符串
一个长度为N的String对象一般需要(64+2N)字节 = 40字节本身开销 + (24 + 2N)数组开销
但当调用substring()方法创建子字符串是,它仍然使用了相同的value[]数组,因此只会使用40字节,子字符串的别名,子字符串对象的偏移量和长度与标记了子字符串的位置,即“一个子字符串所需的额外内存是一个常数,构造一个子字符串所需的时间也是常数”
在递归中创建数组和其他大型对象的风险
每一次递归调用都会使用大量内存,当方法返回时,占用的内存也被返回给系统栈.new出对象时,系统会从堆内存的另一块区域为该对象分配内存,而且所有对象会一直存在,直到引用消失.这种动态过程使得准确估计一个程序的内存使用极为困难.
答疑
问:大O的含义是什么?
答:定义:对于f(N)和g(N),如果存在常数c和N’使得对于所有N>N’都有|f(N)|<cg(N),则我们称f(N)为O(g(N)),主要描述算法性能的渐进上限.但算法的实际性能可能好很多,所以大O主要简化乐对增长数量级的上限的研究.

若有收获,就点个赞吧
0 人点赞
