Knuth-Morris-Pratt子字符串查找
算法描述
- KMP算法基本思想是匹配失败时,已经知晓部分文本,从而避免回退到所有字符前
DFA模拟
DFA确定优先有限状态自动机,由状态和转换构成,pat中的每一个字符可代表一个状态
二维数组表示:dfa[转换][状态]即为一个DFA 字符串查找:DFA中,只有一条是匹配转换,从j->j+1,其余都非匹配,回到之前某个状态
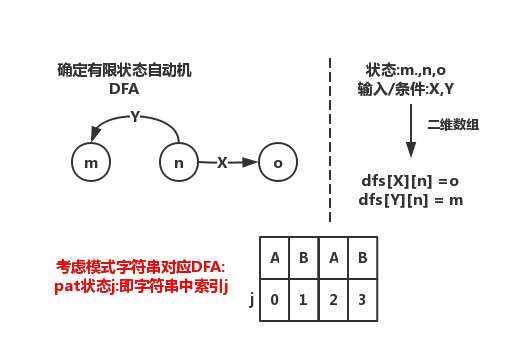
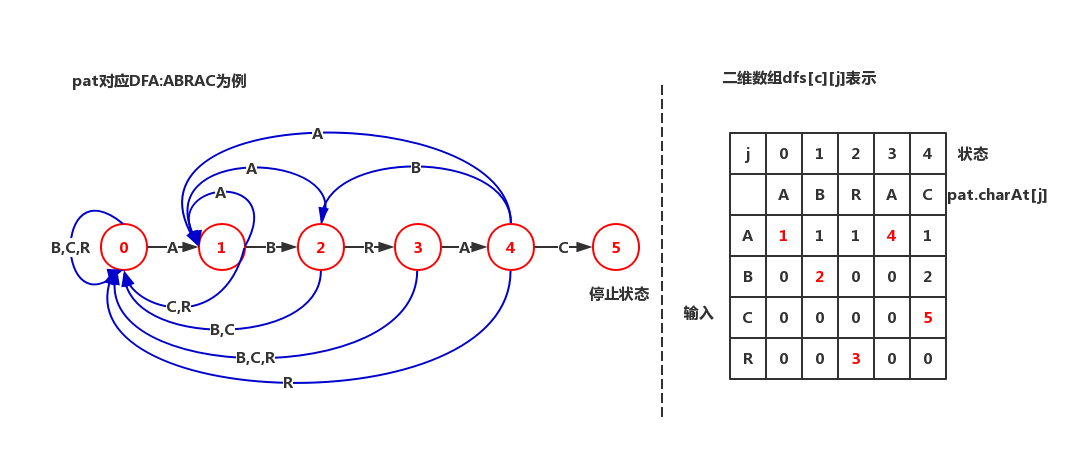
KMP算法和DFA
- 模拟DFA运行:只要知道dfa[][]就可以得到KMP算法:当txt的i和pat的j指向字符匹配失败(从txt的i-j+1开始匹配),pat的下一可能匹配位置应从i-dfa[txt.charAt(i)][j]开始,但从该位置开始的dfa[txt.charAt(i)][j]个字符和pat的前dfa[txt.charAt(i)][j]个字符相同,无需回退指针i,只需将j设置为dfa[txt.char(i)][j]并且i+1即可
//模拟DFA运行public int search(String txt){int i,j,N = txt.length(), M = pat.length();for (i = 0, j = 0; i < N && j < M; i++)j = dfa[txt.charAt(i)][j];if (j == M) return i-M;//找到匹配else return M;//未找到匹配}
构造DFA
- 核心:dfa[i][j]要理解为j状态时接收i时发生的转换
- 考虑暴力解法在pat.charAt(j)匹配失败时
- 回退文本指针i至初始位置
- 文本指针右移一位,重新开始扫描
- 重点在于:pat.charAt(1)到pat.charAt(j-1)被重新扫描,首字母和最后一个字符忽略
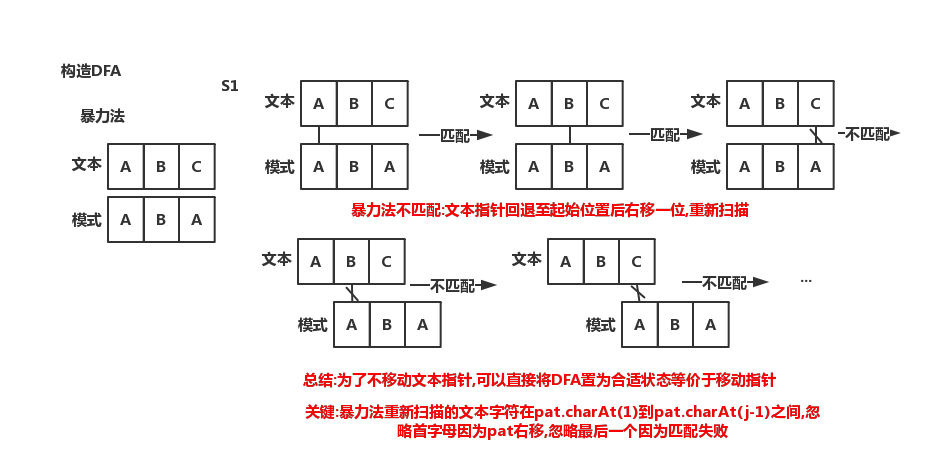
- 考虑DFA只要知道暴力法回退扫描完后DFA的状态,将其重置为此状态,就达到了不移动指针但等价的效果
- 匹配失败:dfa[][X]复制到dfa[][j]
- 匹配成功: dfa[pat.charAt(j)][j]设置为j+1
- 重启状态X: X = dfa[pat.charAt(j)][X]
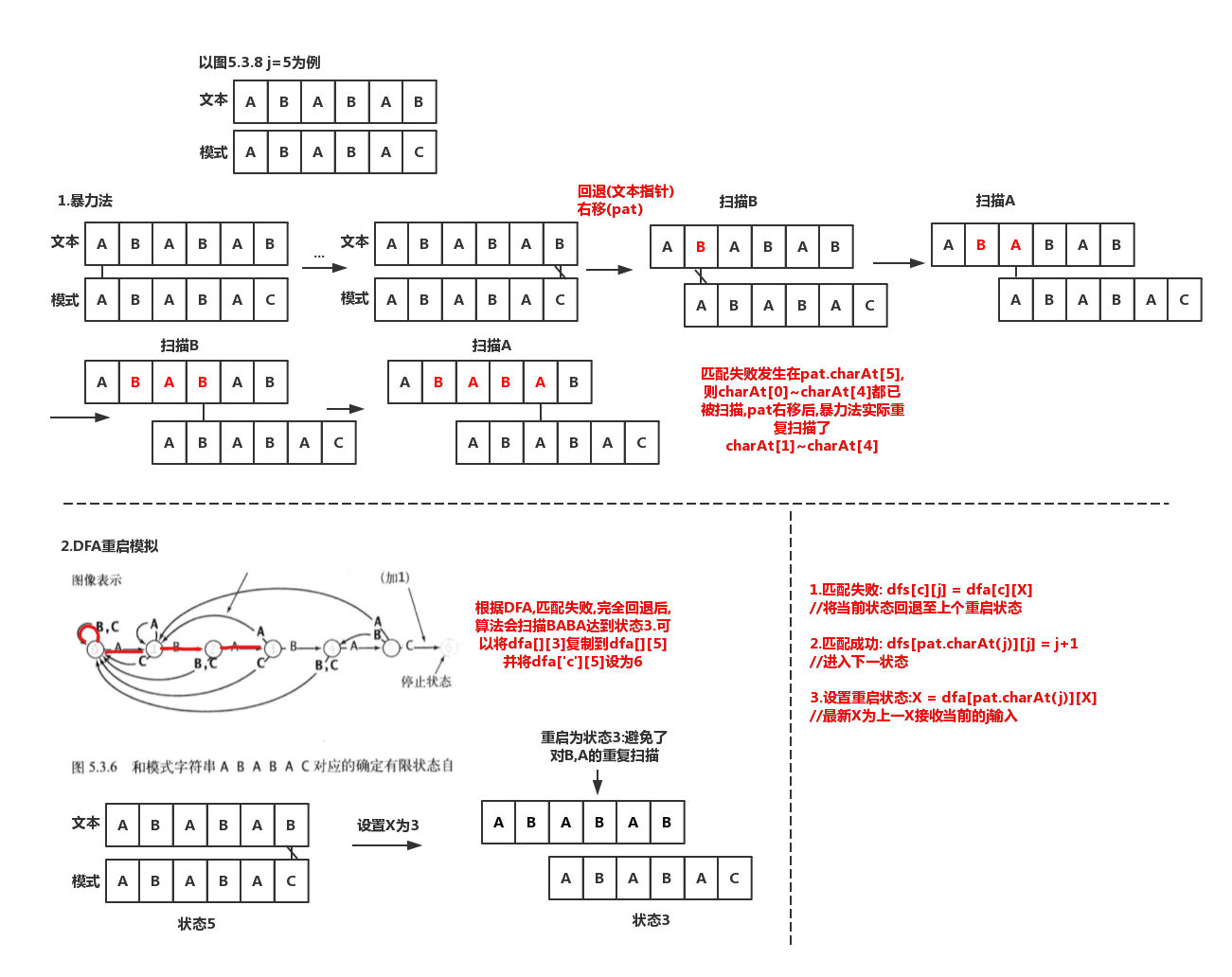
public KMP(String pat){this.pat = pat;int M = pat.length();int R = 256;dfa = new int[R][M];//构建DFAdfa[pat.charAt(0)][0] = 1;for (int X = 0, j = 1; j< M; j++){for (int c = 0; c < R; c++)dfa[c][j] = dfa[c][X];//匹配失败dfa[pat.charAt(j)][j] = j+1;//匹配成功X = dfa[pat.charAt(j)][X];//更新重启状态}}
KMP算法API
| 返回类型 | 方法 | 描述 |
|---|---|---|
| KMP(String pat) | 根据pat构建DFA | |
| int | search | 输入txt运行DFA |
public class KMP {private String pat;private int[][] dfa;public KMP(String pat){}public int search(String txt){}public static void main(String[] args){String pat = args[0];String txt = args[1];KMP kmp = new KMP(pat);StdOut.println("text: " + txt);int offset = kmp.search(txt);StdOut.print("pattern");for (int i = 0; i < offset; i++)StdOut.print(" ");StdOut.println(pat);}}
算法分析
- 长度M的pat和N的txt,KMP算法访问字符不会超过M+N个
证明:在KMP()构造DFA时访问pat中每个字符一次,在search()访问每个txt字符一次

若有收获,就点个赞吧
0 人点赞
