1. 传输层服务
1.1 服务和协议
| 服务 | - 供运行在不同host上的程序进程逻辑通信 - 端系统中的传输层协议: - 发送方:app层msg—>分割为segments—>传递给network层 - 接收方:把segment重组为msgs |
|---|---|
| 协议 | 见: Ch2 因特网传输协议服务(TCP/UDP是传输层协议)⭐ |
1.2 对比网络层
- 网络层
负责hosts之间的逻辑通信
- 传输层
负责程序进程之间的逻辑通信(依赖,加强了网络层服务)
2. 多路复用/多路分解
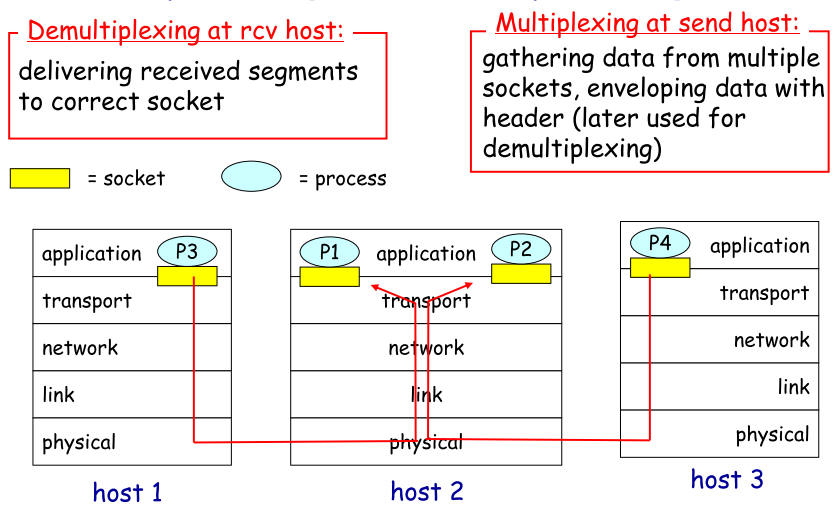
| multiplexing | demultiplexing | |
|---|---|---|
| 定义 | 源host从不同socket中收集数据块,为它们封装head(用于以后分解),从而生成segments,再把segments投递到network层 | 接收端主机,运输层检查字段,标识出对应的接收socket,将把segments定向到对应socket |
**多路复用/分解原理解释了为什么多个socket可使用一个port通信** |
| 原理 |
- 主机接收IP数据报
- 每个数据报有S_IP,D_IP
- 每个数据报携带一个报文段
- 每个报文段有一个S_Port
number,D_Port number
- 主机使用IP&Port
numbers就能直接找到对应的socket
- 参考: 关于port
| 数据报报文段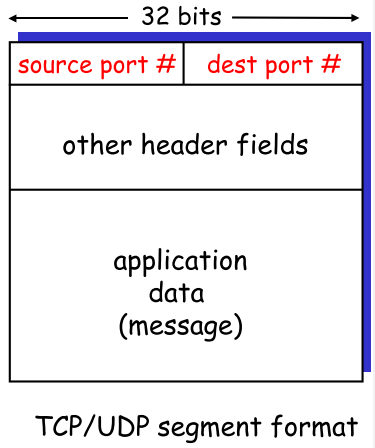 |
|
2.1 UDP—无连接的M/DM
对于接收host来说:
| 特征 |
- 创建指定端口的socket
- 一个UDP** socket是由一个二元组
- 接收UDP数据报时:
- 检查报文段中dest port number
- 通过port number直接引导到对应socket
- 当s IP不同时,只要d IP和port一样,报文段就会引导至一样的socket
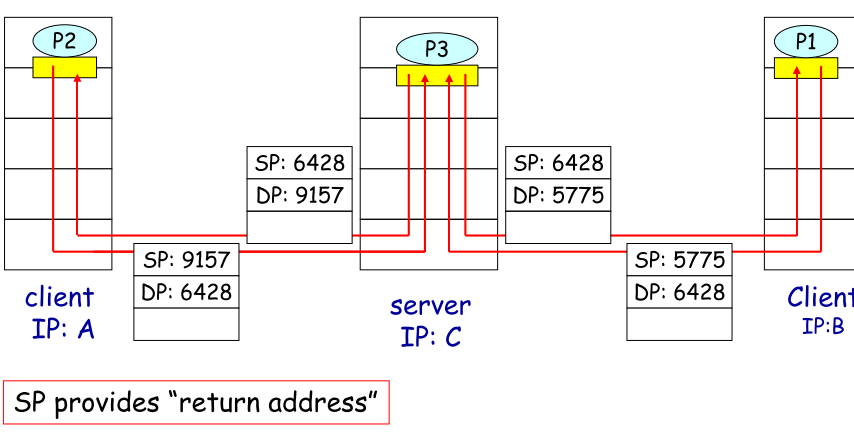 |
| —- | —- |
| SP的作用** | segment中的dest port可供引导segment;
|
| —- | —- |
| SP的作用** | segment中的dest port可供引导segment;
而SP是在当接收方需要回发报文时,会从中取值,加上发送方IP作为地址 |
2.3 TCP—面向连接的M/DM
对于接收host来说:
| 特征 |
- CP socket由四元组标识**<sIP,sP,dIP,dP >,接收方使用四个值直接引导报文段到指定socket
- server host可支持同时多个TCP
sockets,下图
- 因为四元组的区分,web服务器对一个client可以有不同的socket(不同端口),见下图
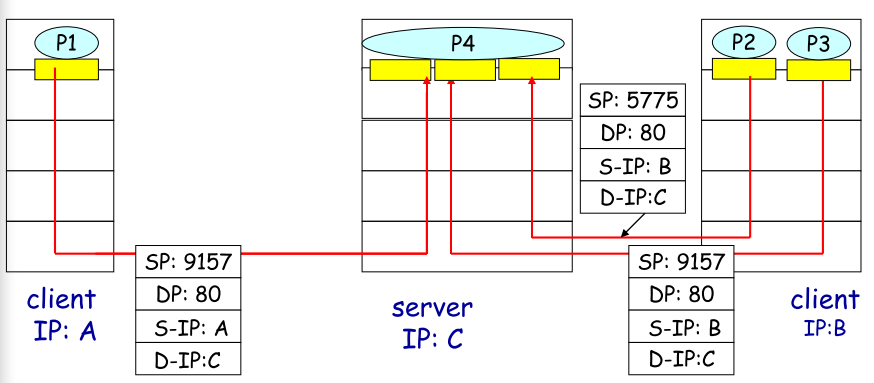 |
| —- | —- |
| 个人理解 | |
| 所谓多路复用就是一条路可以同时传输多个来自不同links的segs,要做到这点,就需要区分segs,因此UDP中使用二元组,TCP中使用四元组,解复用自然而然就是”各回各家,各找各妈”** | |
|
| —- | —- |
| 个人理解 | |
| 所谓多路复用就是一条路可以同时传输多个来自不同links的segs,要做到这点,就需要区分segs,因此UDP中使用二元组,TCP中使用四元组,解复用自然而然就是”各回各家,各找各妈”** | |
3. 无连接传输—UDP
3.1 概述
| 特征 |
- 无连接
- 没有s/r之间的握手;
- 每个UDP上的seg都独立于其他segs被处理
- 尽力而为的传输
- 丢包,乱序
- 简单
- seg的header更小
- 无拥塞控制
| 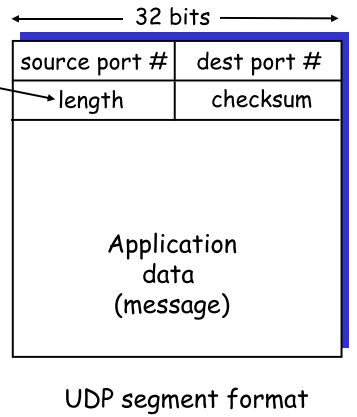
UDP
seg中length指明了seg**的字节长度(data+header) |
| :—-: | —- | —- |
| 用于 | 适合loss tolerant以及rate
sensative的程序,如:流媒体,DNS | |
| 改进** | 企业为了并取优点,大都自己设计应用层协议实现原有传输层TCP中的可靠性保证,在传输层采用UDP协议,保证速度 | |
3.2 checksum
| 目的 | 检测segs中的错误 | |
|---|---|---|
| 流程 | sender: - 把seg内容视为16bits序列 - 对所有16bits字求和,并回卷溢出,结果取反码作为checksum - 把checksum放在UDP seg中 |
receiver: - 根据收到seg内容计算checksum - 对比计算结果和checksum域中的值 - 相等:no error - 不相等: error |
| 举例 |  |
4. 可靠数据传输原理,RDT⭐
**principles of reliale data transfer(不理解FSM简单浏览本节即可,从题中学习)
4.1框架
| 服务抽象 | 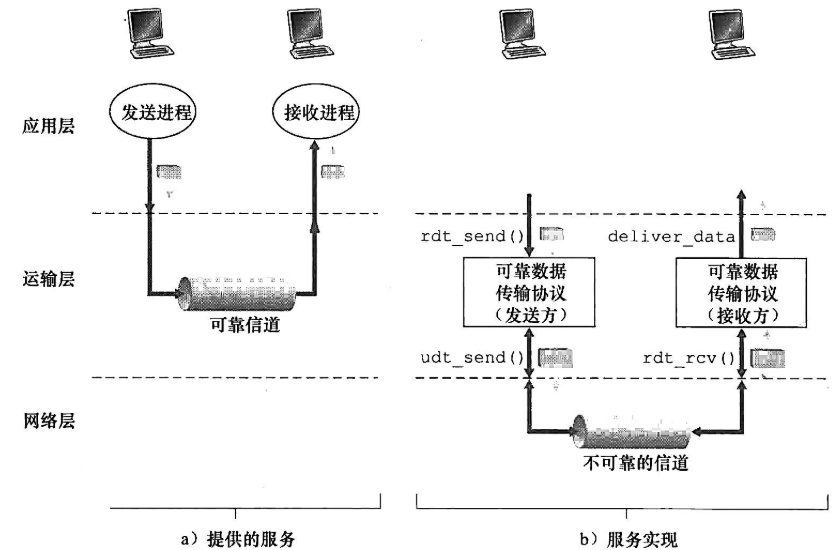 理想情况:数据可以通过可靠的信道传输,从而bits不会损坏或丢失,而且所有数据都按照发送顺序交付.如TCP连接 |
|
|---|---|---|
| 实现协议 | 可靠数据传输协议 reliable |
data transfer protocol.如TCP就是传输层上的可靠传输协议 | |
| 问题 | 可靠协议的下层协议也许不可靠.如TCP在网络层上不可靠的IP协议上传输 | |
| 讨论目标 | 开发一个协议,能够考虑到底层带来的bits损坏或丢失升至丢包,注意的是可靠数据传输原理不针对某一层,在各层中都有体现 | |
| 约定 |
- rdt/udt: 可靠/不可靠数据
- rdt_send():上层调用(如app),传输可靠数据
- udt_send():由rdt调用,通过不可靠信道传输数据给receiver
- deliver_data():rdt调用,传递数据给上层
- rdt_rcv():当packets抵达信道的rcv端时调用
目前只考虑单向(unidirectional)数据传输,以下过程设计到FSM,有限状态机
| 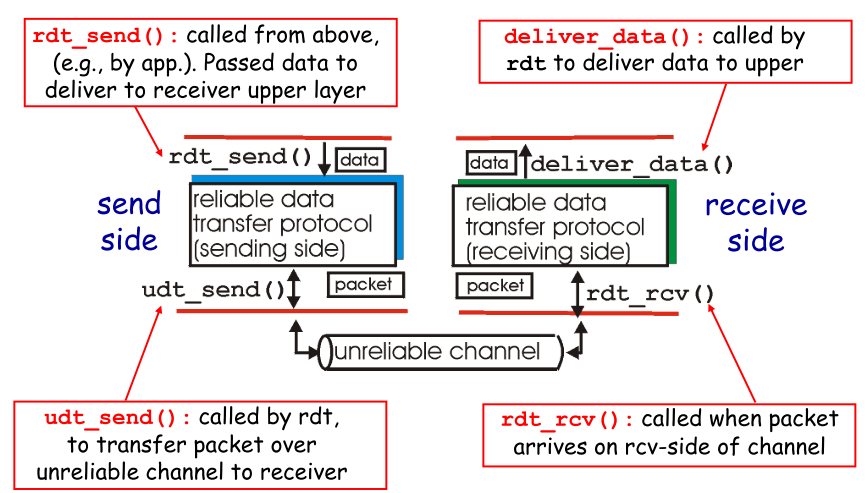 |
|
4.2 rdt1.0
rdt1.0假设了完全可靠信道的可靠数据传输
| 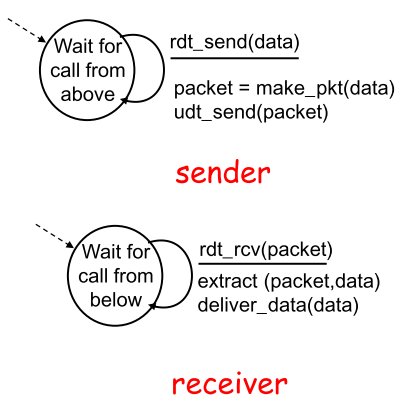 |
|
- sender
接收高层数据,打包后通过信道传输
- receiver
从底层接收packet,从中取数数据后传给较高层 |
| :—-: | —- |
| | 这种理想情况下,receiver无需提供任何信息给sender,因为无需担心出错 |
4.3 rdt2.0
rdt2.0针对有bit差错信道的可靠数据传输
| FSM | 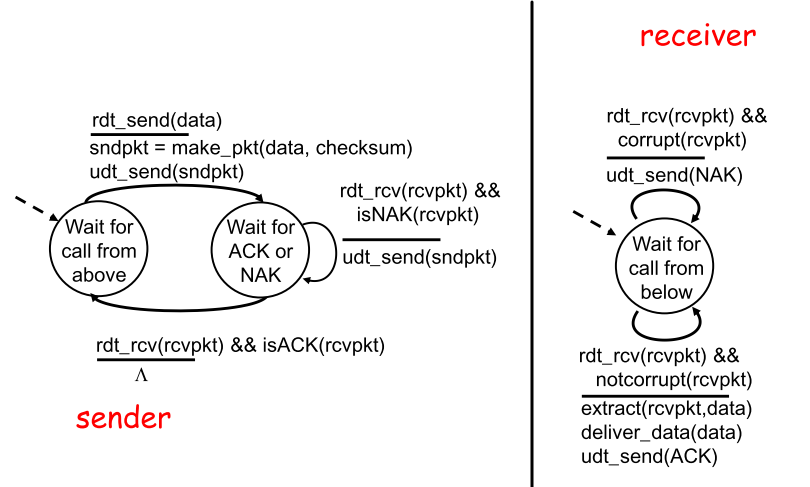 |
|---|---|
| 分析FSM | - sender |
接收上层调用后把数据和checksum打包通过信道发送—>进入wait state:如果收到NAK,则重发packet继续当前state;如果收到ACK—>进入等待命令的下一状态
注意:当**sender等待ACK/NAK时,无法接收上层调用,这种机制叫做”停等”(stop-and-wait)
- receiver
收到packet后,如果pkt中有bit错误,返回NAK;如果没有错误,提取数据,传递数据,返回ACK |
| 理解 | 此时需要考虑到确认信息的需求—自动重传请求协议(Automatic Repeat reQuest, ARQ),协议中有三种应对bit差错的地方:
- 差错检测
- 接收方反馈:
- ACK,
acknowledge:肯定确认,理论上只要一个bit:1
- NAK,
negative ~:否定确定,同样一个bit:0**
|
4.4 rdt2.1
| rdt2.0缺陷 | 可能的解决和新的问题 | 实际方案 |
|---|---|---|
| ACK/NAK本身出现错误 | 给Receiver返回的ACK/NAK也设置checksum.当Sender收到含糊的ACK/NAK分组,则重传pkt 困难在于**receiver不知道上一次ACK/NAK是否被sender正确接收,从而无法区分自己正在接收的pkt**是上次重传还是新的 |
在pkt中添加编号,即把当前pkt的序号放在字段中,结合停等机制,server会重发不确定的pkt,而receiver通过序号就知道接受的是重发pkt还是全新pkt |
FSM
| S | 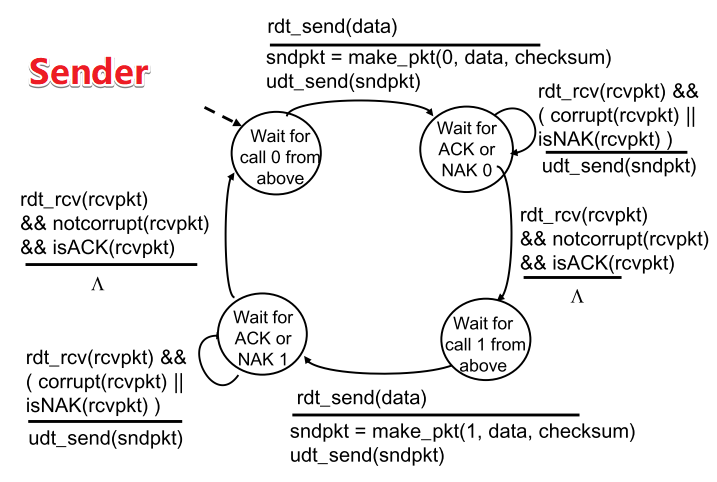 |
等待调用0状态—>打包发送pkt0—> 停等0状态: ①当收到NAK或发现ACK/NAK出错(corrupt),则重新发送pkt(ACK/NAK本身无需携带序号,由于停等机制,sender知道这次ACK/NAK出错发生在最近的pkt0),继续停等0状态 ②当收到ACK且反馈本身无误(notcorrupt)—>进入等待调用1状态 |
|---|---|---|
| Sender端的corrupt表示ACK/NAK混淆 |
receiver端的corrupt表示pkt有误 |
| R | 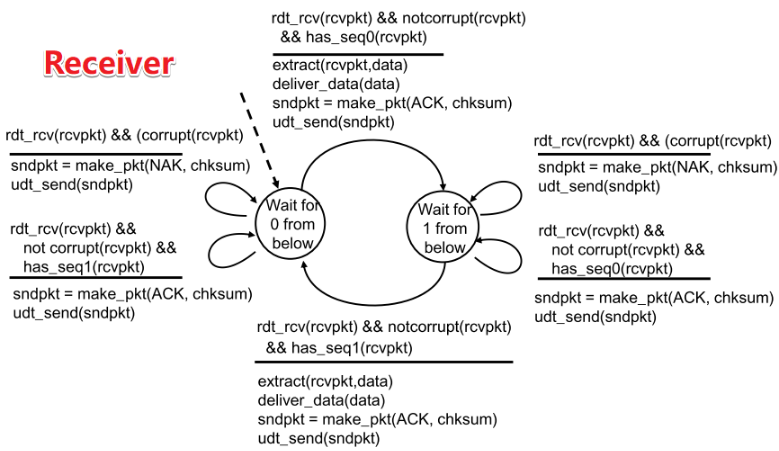 | 等待传入0状态:
| 等待传入0状态:
①如果发现传递出错(corrupt),则打包返回NAK,继续等待传入0状态;(错误分组)
②如果接收到pkt1,传递无误,则返回ACK,继续等待传入0状态(失序分组)
③如果发现pkt0,传递无误—>提取数据,传递数据,返回ACK(正常分组)—>进入等待传入1状态
|
4.5 rdt2.2
优化rdt2.1得到2.2:NAK省略/冗余ACK
| FSM |  |
|---|---|
| 分析FSM | - Sender |
等待调用0状态—>打包发送pkt0—>
停等0状态:
①当收到ACK1或ACK/NAK混淆时,重发pkt0,继续停等0状态
②当收到ACK0且反馈本身无误(notcorrupt)—>进入等待调用1状态
- Receiver
等待传入0状态:
①收到pkt1或传递出错,发送ACK1
②收到pkt0且传递无误—>提取数据,传递数据,返回ACK0—>进入等待传入1 |
| 理解 | 冗余ACK体现在:
进入①前,Sender必定收到了ACK1,再次进入①收到ACK1,说明Receiver没有正确接收pkt0 |
4.6 rdt3.0
rdt3.0即比特交替协议(alternating-bit protocol)实现了有bit差错和丢包的可靠数据传输
| 问题 | 需要做什么 | 想法:时限+重传+冗余pkt |
|---|---|---|
- bit受损/丢失 - 丢包 |
- bit检测/应对 - 丢包检测/应对 |
让sender负责检测和恢复丢包,无论pkt或者receiver的ACK丢失,sender都无法收到合适的响应,设定一个时限,当超过后,就认为发生丢包,进行重传.由于时延的不确定,需要考虑到延迟过大导致误以为丢包后重复传输pkt产生的冗余pkt,为实现基于时间的重传,需要timer ①每次发送一个pkt(新pkt或重传pkt)时启动 ②可以响应特定动作从而中断 ③终止 |
FSM
| FSM | 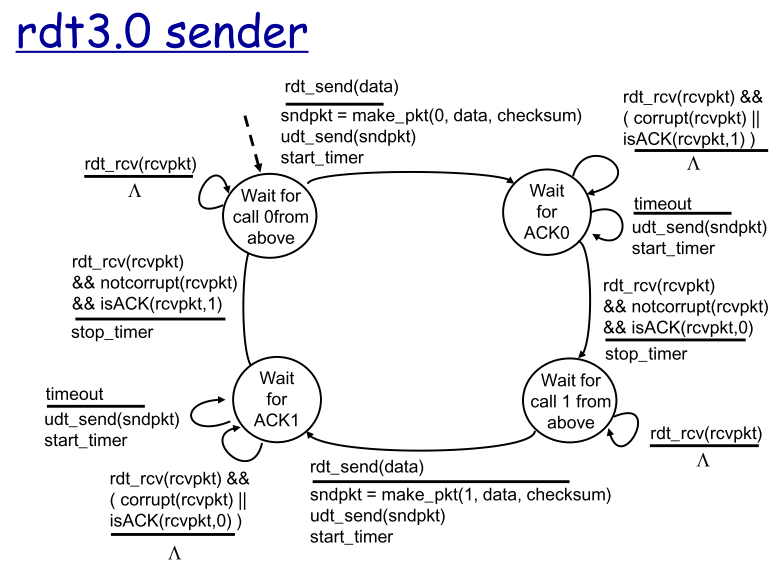 |
|---|---|
| 分析FSM | - Sender |
基本类似rdt2.2版本,等待调用0状态->打包发送pkt0,开始计时—>
停等0状态:
①收到ACK1或ACK/NAK混淆,触发计数器进入②(计时一直进行)
②时间到,重发pkt0,重新计时
③收到ACK0且反馈本身无误,停止计时—>进入等待调用1状态
- Receiver
等待传入0状态:
①收到pkt1或传递出错,返回ACK1,保持等待0
②收到pkt0且传递无误,返回ACK0—>进入等待传入1状态 |
总结rdt3.0的四种运行,分组号总在01间交替,因此叫比特交替协议
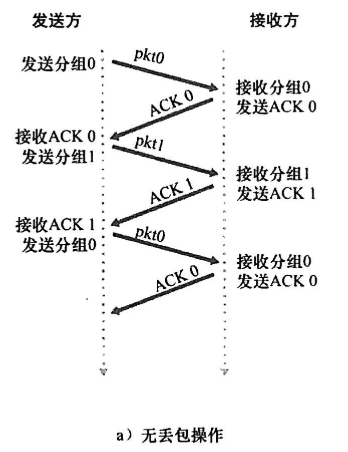 |
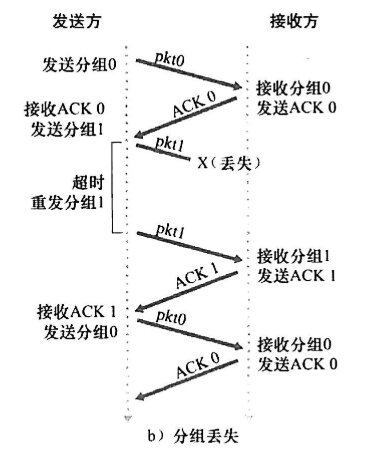 |
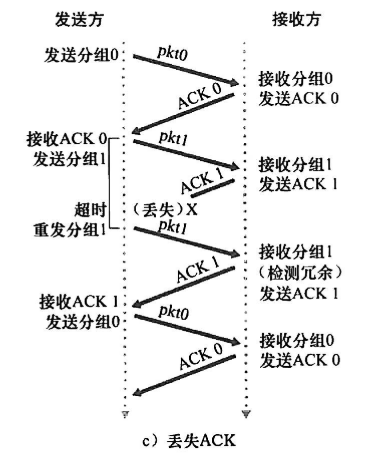 |
 |
|---|---|---|---|
5. 停等协议改进⭐
5.1 利用率与流水线
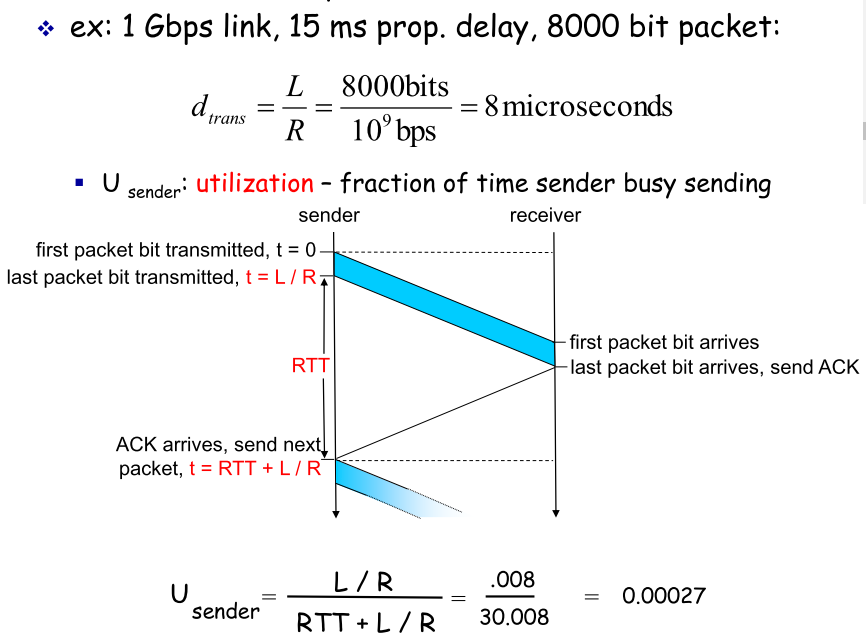 rdt3.0只是功能上正确的协议,性能孱弱,左图说明了其在传输文件时低下的利用率(utilization),问题在于它的停等机制,让sender必须在接收到ACK后才能发出下一个pkt |
改进思路:流水线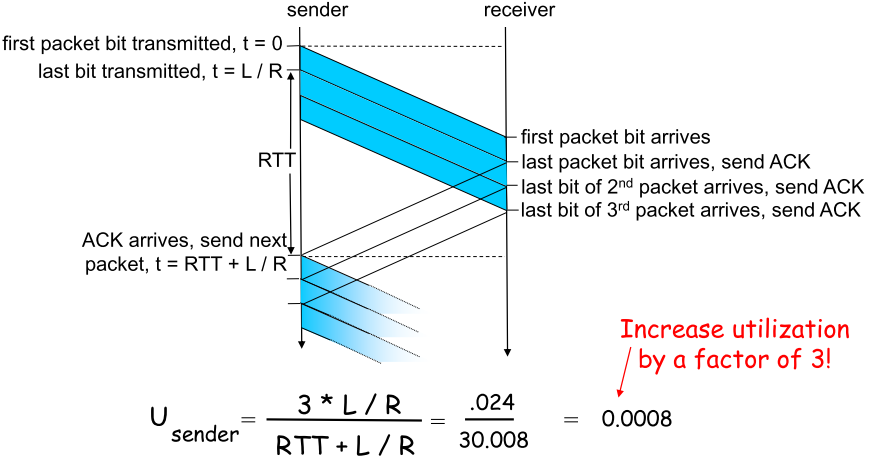 - 必须增加序号:流水线使得同时在link上的未确定pkt有多个,不能只是用0,1 - sender/receiver都必须缓存多个pkt,因此sender必须缓冲那些已经发送但是没有确认的pkt |
|---|---|
5.1 GBN—滑动窗口协议
GBN即回退N步
| 模式 | 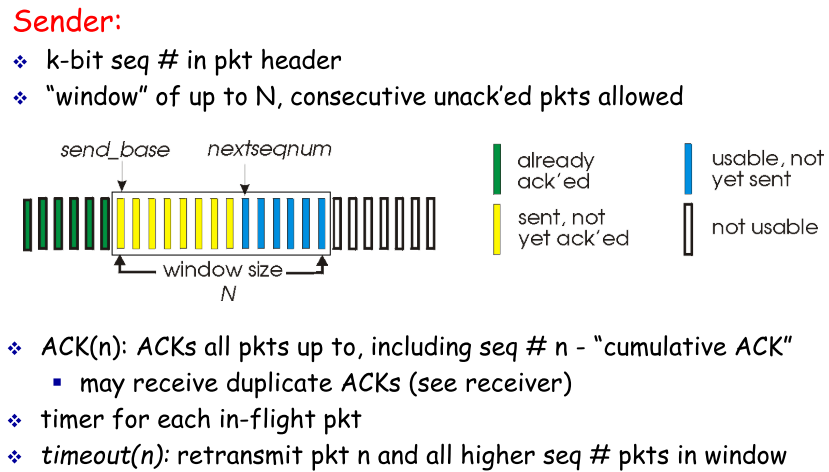 |
|
- base:标识已发送但还未ack的pkt
- nextseq:标识待发送的pkt
- N:窗口尺寸,即缓冲大小,
seq
|
| :—-: | :—-: | —- |
| 可靠性 | 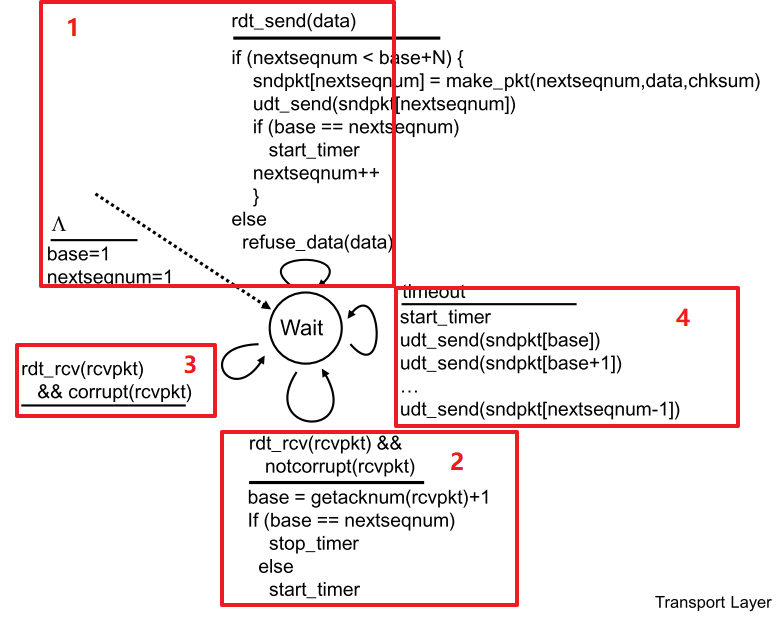 | sender
| sender
1. 初始base=(next)seq=1,此后只要seq
1. 收到任何ACK重置timer
1. 当时间到,重发当前窗口从[base]~[seq-1]的所有pkt
|
| | 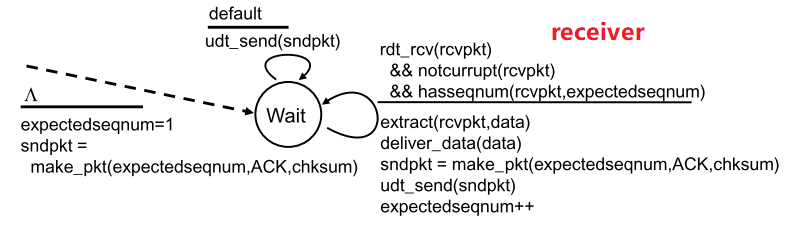 | receiver
| receiver
1. 初始化(expect)seq=1;
1. 接收到正确且合序的pkt,提取数据,返回对应pkt,seq++;
1. 其余默认情况下返回当前最大正确顺序seq的pkt;
|
| 特征 |
1. 顺序性:对于sender,必须收到base的ack才能窗口右移,否则do nothing;对于receiver,必须接收expectseq的pkt才能返回pkt并seq++
1. 按窗口重发:当timeout时,无论处于sender的[base]~[seq-1]的pkt是否能正确到达,重发所有(回退)
1. 积累确认,对序号为n的分组确认时,表明接收方对n和n之前所有的pkt都正确接收
| |
| 示意 | 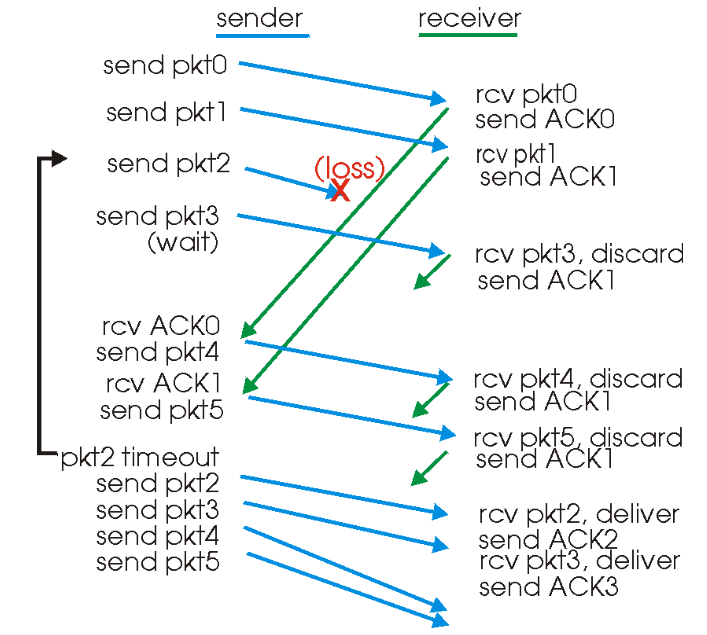 | |
| |
5.2 SR—选择重传
SR—Selective Repeat
| 模式 | 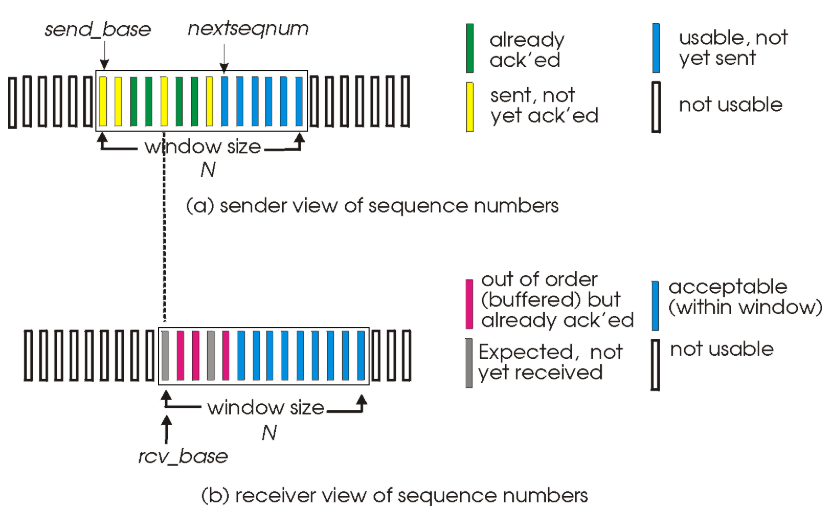 SR下receiver也设置了buffer,从而使得双方可以乱序发送/接收 |
|
|---|---|---|
| 可靠性 |  |
- sender |
只有收到窗口中最小pkt的ack后base++;当timeout后,重发当前最小未确认的pkt,重启计时器
- receiver
对于在窗口中的pkt,正确接收后返回ack,不用考虑顺序;对于冗余/错误pkt,do nothing由sender的timer处理,时间到后对面自然会重发 |
| 模式 | 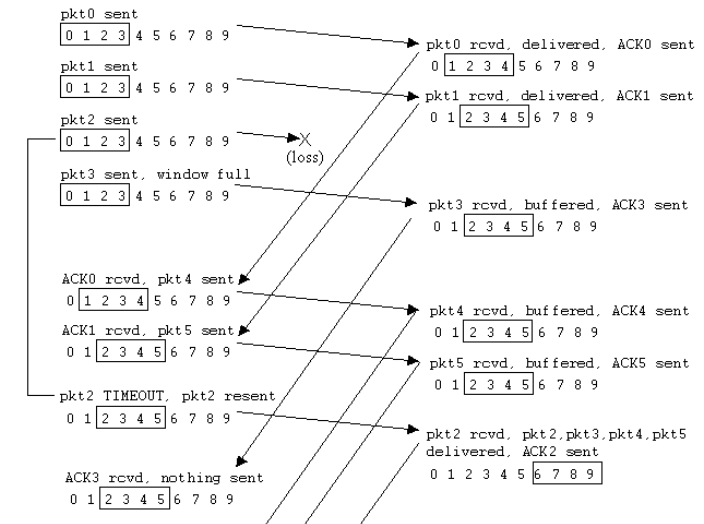 | |
| |
- 收发不同步的衍生问题**(ch3课后p22,23)**
|
 |
| :—-: |
| 解:这道题先分析b更合适,注意在GBN下:
|
| :—-: |
| 解:这道题先分析b更合适,注意在GBN下:
b).接收方expseq=k,说明从pkt[k-N]~pkt[k-1]都已经确认接收返回ACK,则取值范围[k-N,k-1]
a).由b),接收方返回了N个ACK,但不能保证都正确抵达:
- 最坏:N个ACK都出问题,sender的base还是k-N,则seq取值范围[k-N,k-1]
- 最好:N个ACK都正确接收,窗口已经移动N位,base=k,此时seq的变化范围[k,k+N-1]
| | |
| SR接收方窗口大小问题—分组序号有限:0,1,2,3且receiver窗口大小为3.
|
| SR接收方窗口大小问题—分组序号有限:0,1,2,3且receiver窗口大小为3.
a)receiver的三个ACK全部丢失,因此sender需要重传第一次的seq为012的pkt012
b)sender发送pkt3丢失,产生不同步,sender发送pkt4(seq0).receiver需要确认seq3和第二次出现的seq0==>对于receiver来说,无法辨别这时的seq0是新pkt或者重传 | | |
| 解:结合上一题,依旧设此时expseq=k,窗口大小N
|
| 解:结合上一题,依旧设此时expseq=k,窗口大小N
考虑极端情况下,s和r”最不同步”的情况即receiver接受了N个pkt,返回的N个ACK全部丢失.此时receiver窗口最右端为k+N-1;sender的seq最坏为k-N,此时最大不同步距离为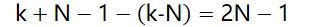
包含2N个不同序列号,则为了避免发生序号重叠,应该保证序号空间范围k≥2N |
6. 面向连接的传输—TCP
6.1 TCP概览
| 组成 |
- 一台host上的(发送)buffer,变量和进程socket
- 另一台host上的(接收)buffer,变量,进程socket
注意:两台host之间的网络元素(routers,switchers)都没有为连接分配cache和变量
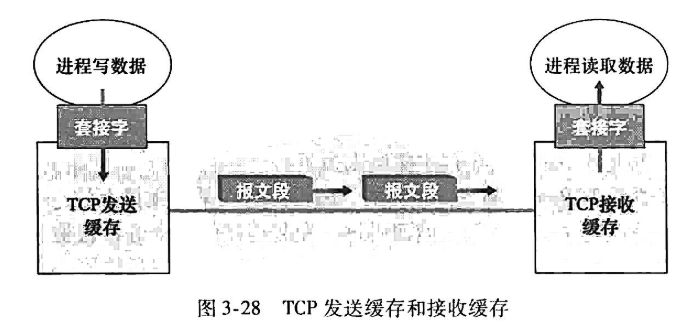 | |
| :—-: | —- | —- |
| 特点 |
| |
| :—-: | —- | —- |
| 特点 |
- 面向连接的:两个进程在数据传输之前,必须相互”握手”—相互发送预备报文段以确保数据传输的参数
- 一一对应:一个sender,一个receiver
- 可靠的有序字节流
- send/receive buffer
- full duplex data(全双工数据):在一条链接中的双向数据流;
- MSS:maxmium segment
size最大报文段长度,TCP可从buffer中提取放入segment中数据数量的最大限制
- 流控
| |
| 流程 | 三次握手 |  |
| | 连接建立 |
|
| | 连接建立 |  |
| | 数据封装传递 |
|
| | 数据封装传递 |  |
| 对比UDP |
|
| 对比UDP |
- TCP提供:可靠有序传输,流控,拥塞控制,
- UDP仅提供:process2process投递, 数据校验(checking)
| |
6.2 TCP seg结构
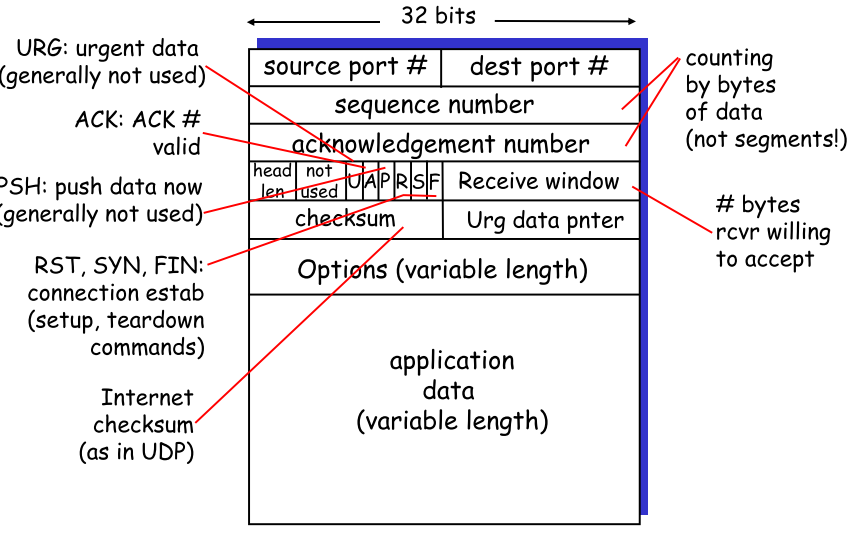
- TCP的seq和ACK
|
- seq:字节流,指示seg中第一个byte的数据
- ACK:期待从对方接收的下一个byte数据
右图👉
A:发出C,C的第一个byte为42,A期待收到79
B:发出C,C的第一个byte为79,B期待收到43 | 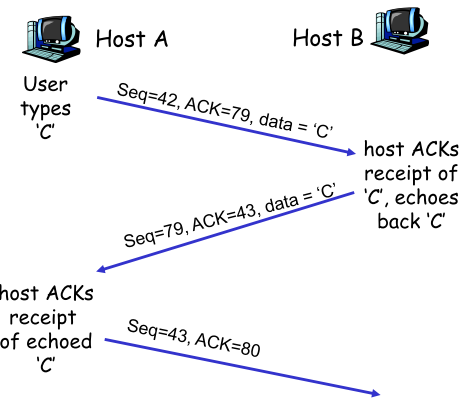 |
| —- | :—-: |
|
| —- | :—-: |
- TCP的RTT和timeout实现
| RTT |

sampleRTT是直接采样得出 | | —- | —- | | timeout | |
|
6.3 可靠数据传输⭐
网络层的IP服务不可靠,TCP在不可靠之上建立可靠数据传输服务:确保一个进程从其接收缓存中读出的data flow是无损,无间隙,非冗余,按序的数据流
**
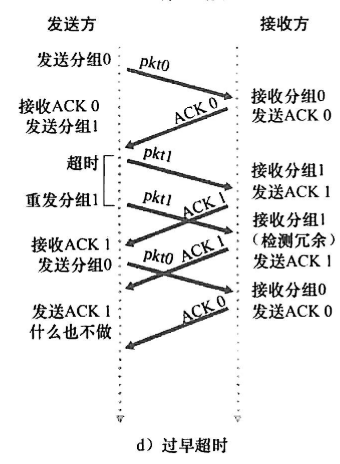
TCP**重传:只能被timeout和duplicate acks触发 | ACK丢失 | 早熟(timeout过早) | 积累ACK** | | —- | —- | —- | |
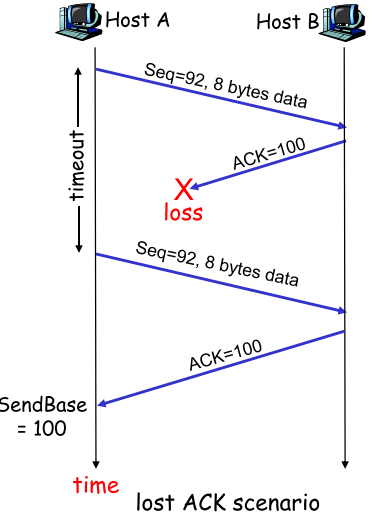 |
| 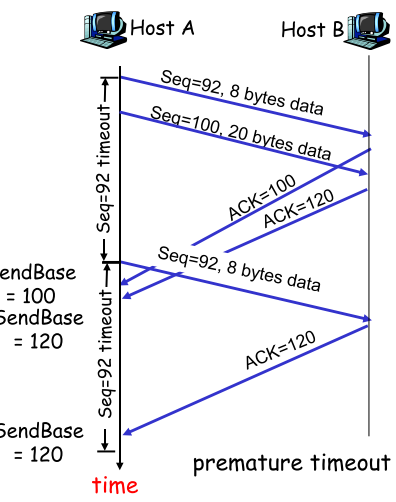 |
| 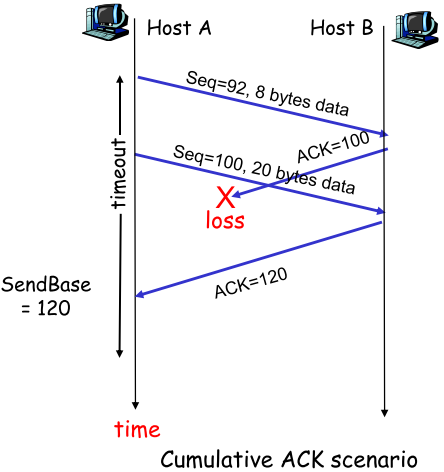
只要sender收到的ACK正确无误,则说明receiver对之前的PKT都正确接收,则sender可以放心的一次性确认,不用在乎中间ACK丢失 |快速重传**(Fast retransmit)** |
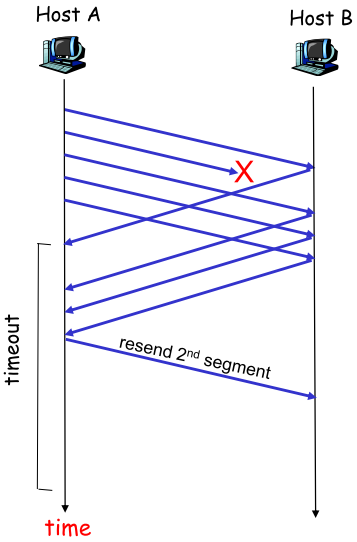 | 如果完全依靠timeout触发重传,效率不够高,比如窗口第一个pkt丢失,可能发出多个pkt后才能timeout.GBN因此引入快速重传,当sender收到多个冗余ACK后,判断该pkt丢失,不管timeout,立即重传 |
| :—-: | —- |
| 如果完全依靠timeout触发重传,效率不够高,比如窗口第一个pkt丢失,可能发出多个pkt后才能timeout.GBN因此引入快速重传,当sender收到多个冗余ACK后,判断该pkt丢失,不管timeout,立即重传 |
| :—-: | —- |
6.4 TCP流量控制⭐
| 背景 | 由于TCP在sender/receiver都具有buffer,为了避免处理速度不一致导致receiver端buffer溢出数据丢失,需要进行流控,使得两端速度相一致,流控算法即GBN/SR |
|---|---|
| 实现 | 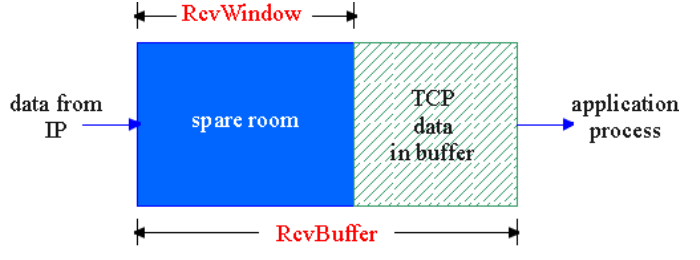 TCP让sender维护一个接收窗口(receiver window),用于提示receiver还有多少buffer可用,且全双工通信使得两端发送方各自维护一个窗口 |
| 场景 | A发送文件给B:B为连接分配RcvBuffer,B上进程定期从中读取数据,定义变量: - LastByteRead:B从buffer中读出的data flow最后一个byte编号 - LastByteRcvd:从网络到达且放入B接收缓存中数据流的最后一个Byte编号 |
为了不溢出,必须保证(rwnd标识接收窗口)
Last**ByteRcvd-LastByteRead≤RcvBuffer
rwnd = RcvBuffer-[LastByteRcvd**-LastByteRead |
6.5 TCP连接管理
三次握手 |
 |
|
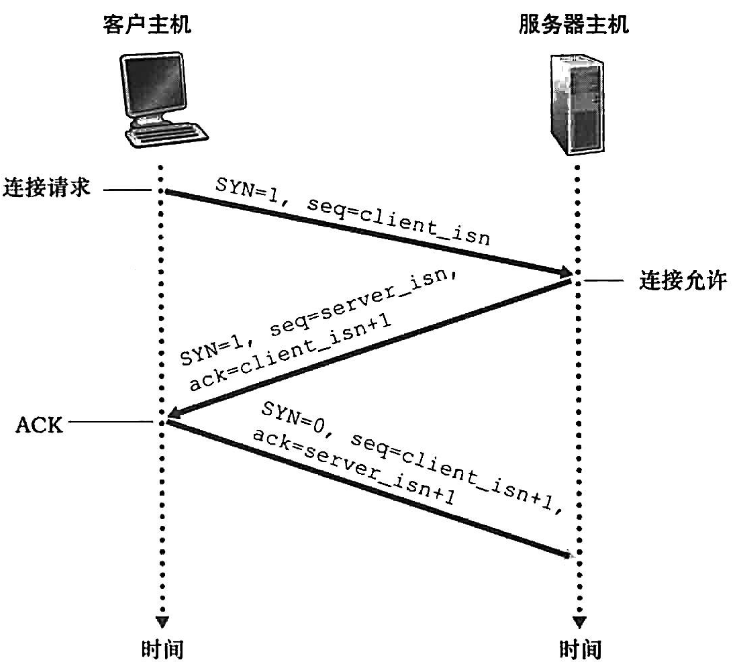
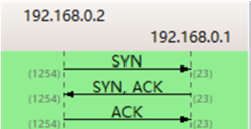
- 第一步: client发送一个特殊的TCP报文段,其中不含app层数据,但header中包含一个标志位SYN,被设为1
SYN=1,seq=client_isn
- 第二步: server收到特殊seg,从中提取SYN,为TCP连接分配buffer和变量,向client发送允许连接报文段SYNACK,不含数据
SYN=1,seq=server_isn,ACK=client_isn+1
- 第三步: client收到SYNACK,也为连接分配buffer和变量,同时发送另一个seg给server,对server的seg进行确认,此时连接已经建立,SYN置为0,可以携带数据
SYN=0,seq=client_isn+1,ACK=server_isn+1
- 之后: 此后可以互相发送seg,在每个seg中SYN都被置为0
| | :—-: | —- | | | WireShark抓包:
| WireShark抓包:
- 阶段一:Seq=0,ACK=0,SYN=1
- 阶段二:Seq=0,ACK=1,SYN=1
- 阶段三:Seq=1,ACK=1,SYN=0
| | | |
| |四次挥手 |
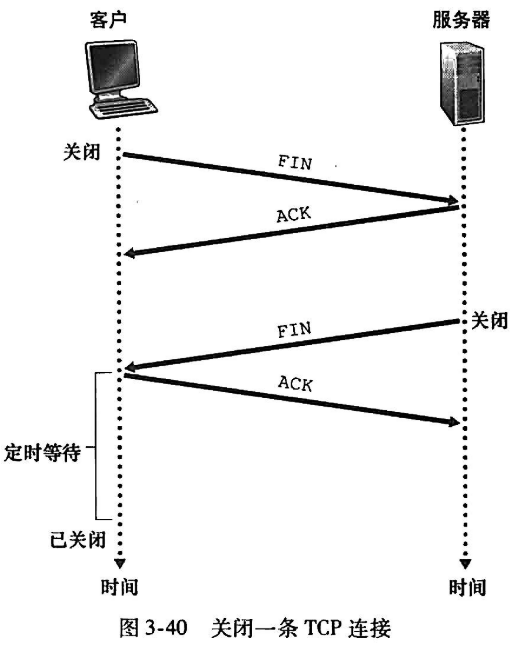 | client应用进程关闭socket
| client应用进程关闭socket
- 第一步
TCP向server端进程发送一个特殊seg,header中包含标志位FIN,设为1
- 第二步
server收到FIN,回复ACK然后
- 第三步
server发送自己的终止seg,FIN设为1
- 第四步
client收到FIN,回复ACK
server收到ACK,连接关闭 | | :—-: | —- |TCP状态序列 | client | server | | —- | —- | |
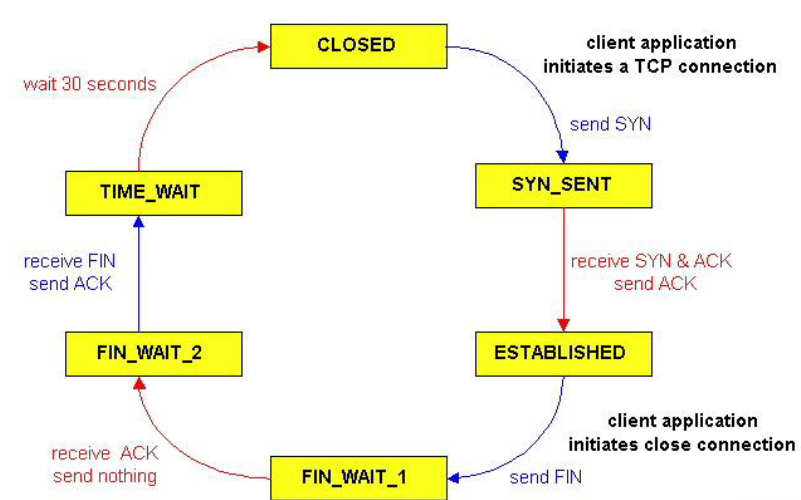 |
| 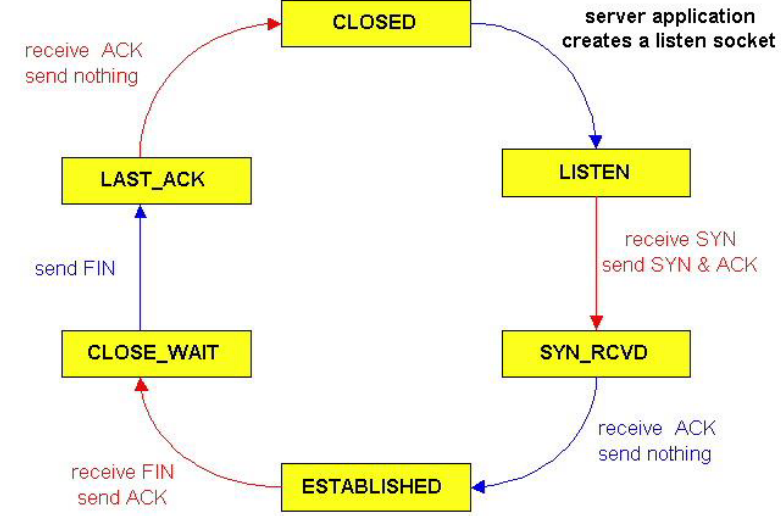 |
|
7. 拥塞控制
拥塞现象是指到达通信子网中某一部分的分组数量过多,使得该部分网络来不及处理,以致引起这部分乃至整个网络性能下降的现象,严重时甚至会导致网络通信死锁
**拥塞控制是链路上的控制;流量控制是S/R端的控制
7.1 三个拥塞场景
| 2发送方,1无限缓存路由
(路径带宽R,λ**in**单位byte/s)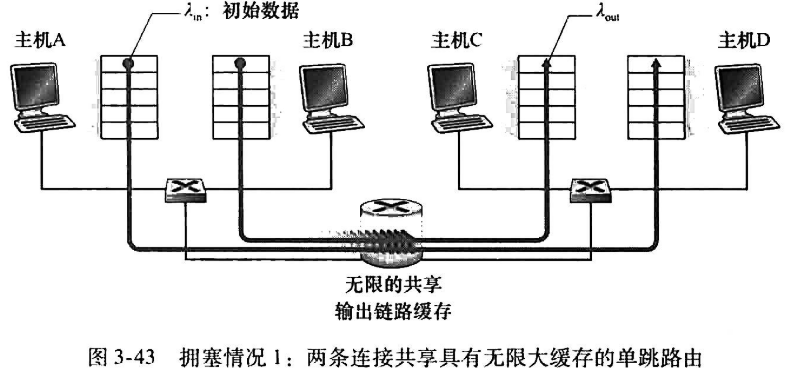 |
| —- |
| 实际拥塞情况:左—troughout与发送速率关系;右—delay与发送速率关系
|
| —- |
| 实际拥塞情况:左—troughout与发送速率关系;右—delay与发送速率关系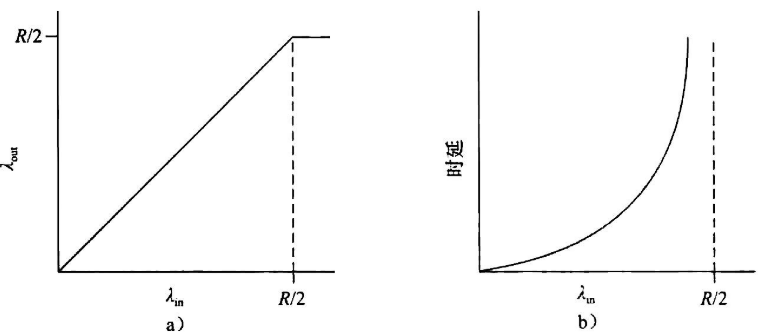
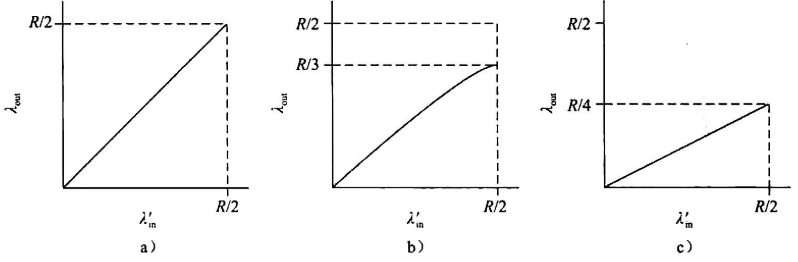
分析:
a)两条路径同时发送,每条路径带宽最大R/2,因此左图在小于R/2时吞吐量与速率成线性关系,当到达R/2后,无法超出带宽,保持R/2
b)当λin接近R/2时流量强度接近并超过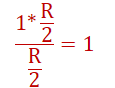 ,不可避免的开始排队并发展成无限期排队(参考:Ch1:流量强度) |
| 2发送方,1有限缓存路由
,不可避免的开始排队并发展成无限期排队(参考:Ch1:流量强度) |
| 2发送方,1有限缓存路由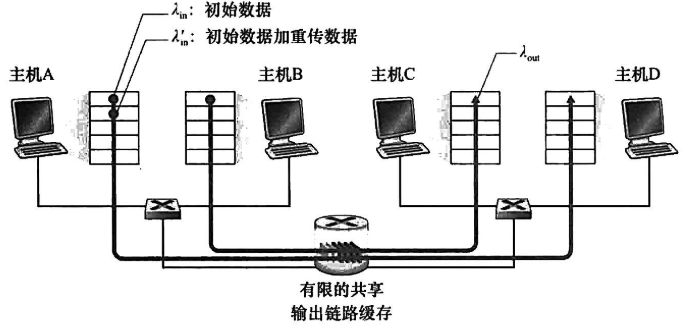 |
| 由于缓存有限,会发生丢包,该情况下引入”重传”机制:
|
| 由于缓存有限,会发生丢包,该情况下引入”重传”机制:
- λ**in表示sender应用层->传输层传递初始msg速率
- λin‘表示sender传输层->网络层传输初始seg或重传seg速率,也叫网络的供给载荷(offered load)
- λ**out表示receiver把报文段从传输层->应用层速率
分析
a)假设hostA只在buffer空闲时发送分组,此时λ**in=λin‘
b)假设hostA在确认一个packet丢失后才重发,当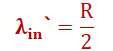 时(初始数据+重发数据)等价于网络中每发送0.5R数据,其中有0.333Rbyte/s是初始数据,0.166Rbytes/s是重发数据
时(初始数据+重发数据)等价于网络中每发送0.5R数据,其中有0.333Rbyte/s是初始数据,0.166Rbytes/s是重发数据
c)假设hostA的timer设置较短,会提前重传,此时效率更为低下 |
| 4发送方,N有限缓存路由&多跳路径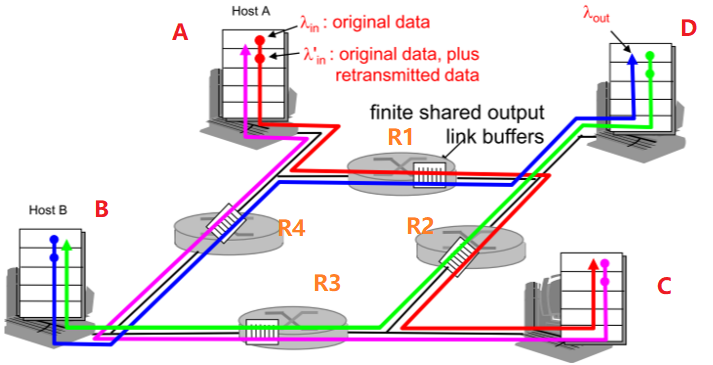 |
| 考虑A->C,经过R1,R2,此时R2被共享,区分:此时可以看到每个路径的带宽R可被一个host完全占有
|
| 考虑A->C,经过R1,R2,此时R2被共享,区分:此时可以看到每个路径的带宽R可被一个host完全占有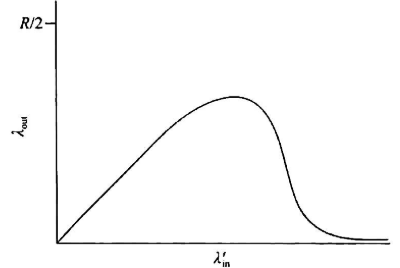
- 当λin‘较小时,对吞吐量的影响类似上一情况
- 当λin‘较大时:
- 理论通过R2的A-C流量最多为R(R1到R2)
- 但此时如果B-D的供给载荷增大,二者会竞争,甚至死锁,A-C的吞吐量可能趋于**0,即如图所示情况
- 此外**,当分组仅丢失在第二跳时,第一条的传输也完全无意义**
|
7.2 拥塞控制方法
| e2e控制⭐ | - 网络层未给运输层拥塞控制提供显式支持 - 端系统通过观察网络行为(丢包,时延)推断 - TCP拥塞控制采用此方法 |
|---|---|
| **network-assisted |
** | <br />- router向sender提供显式的反馈,比如一个bit来只是链路的拥塞情况<br /> |
7.3 TCP拥塞控制⭐
- 思想
因为TCP连接每一端保存:接收buffer+发送buffer+变量(LastByteRead,rwnd)
在sender端额外加入拥塞窗口**(congestion window,cwnd),**保证
| 理解:此约束通过限制sender未确认的数据量间接限制了sender的发送速度:对于一个丢包和发送delay均可不计算的连接,在每个往返时间RTT的起始点,最多可以发送cwnd字节数据,该RTT结束时sender接收确认报文.因此sender发送速率大概为cwnd/RTT字节/s,通过调整cwnd可以调节发送速率 |
|---|
- TCP**拥塞控制算法(DFA真的无法理解可以略过,直接看图下的过程分析**)
主要有三个部分①慢启动②拥塞避免③快速恢复,①②是TCP强制部分,区别在于对收到ACK做出反应时增加cwnd长度的方式,③是推荐部分,非必需
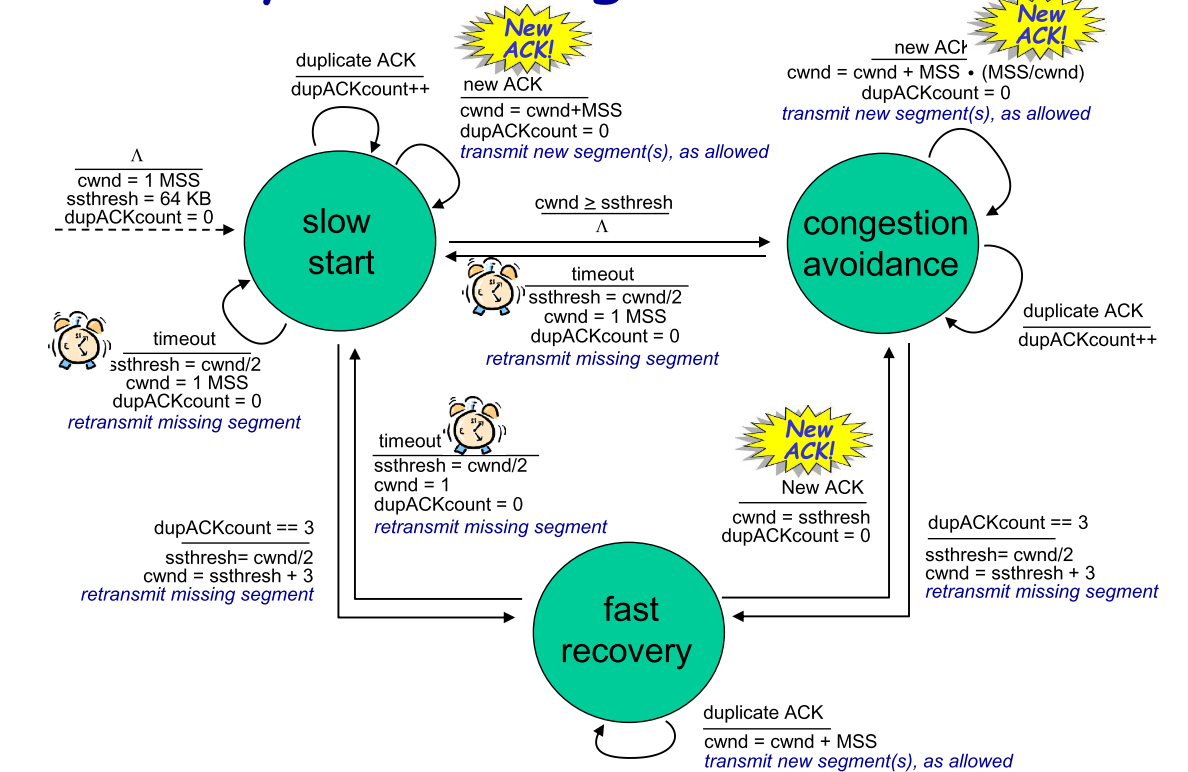
| 慢启动 |
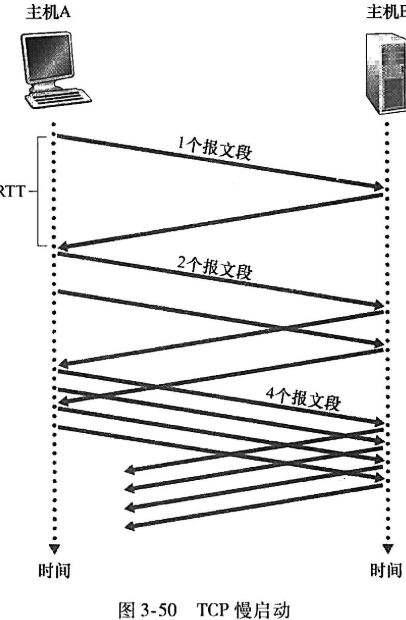
- 初始:给cwnd起始设置为1MSS(最大报文段长度)的较小值,使得初始速率为MSS/RTT
- 传输:之后每次sender确认一个seg后,把cwnd增加一个MSS
(第二次,sender发出两个seg,因此会有两个ACK,sender对cwnd加两个MSS,下次同时发出四个seg…依次类推达到cwnd每次翻倍的效果)
- 结束:发生拥塞后,有三种结束慢启动增长cwnd的方式
1. 当发生timeout标识的拥塞sender把cwnd重置为1—>重启慢启动过程;同时设置ssthresh为cwnd/2
1. 当cwnd==ssthresh(**慢启动阈值**)时结束慢启动且sstresh=cwnd/2—>拥塞避免
1. 如果发生快速重传(Fast retransmit)—>快速恢复
|  |
| :—-: | —- | :—-: |
| 拥塞避免 |
|
| :—-: | —- | :—-: |
| 拥塞避免 |
- 传输:如果进入拥塞避免,此时如果cwnd继续翻倍,很容易又进入拥塞,因此采用每次cwnd增长一个MSS,通用实现一般是接收到ACK后对cwnd增加MSS(MSS/cwnd)
(当MSS=1000,cwnd=8000:假设一个RTT发送8个segs,当一个seg的ACK传达到sender,cwnd增加1000(1000/8000)=125,当RTT结束,cwnd共增加1000)
- 结束:丢包事件发生
1. 当由超时引发(说明拥塞):同上cwnd**=1,sstresh=cwnd/2—>**慢启动
1. 当被3冗余ACK触发(说明只是出错,不一定拥塞),反应不应剧烈—>快速恢复**:cwnd减半,每个冗余ACK使cwnd++,最终产生的效果为cwnd=1/2cwnd+3,sstresh=1/2cwnd—>拥塞避免
| |
| 快速恢复 |
- 进入快速恢复后,立刻重传丢失的seg,重传完毕—>cwnd减半,每个冗余ACK使cwnd++,最终产生的效果为cwnd=1/2cwnd+3,sstresh=1/2cwnd—>拥塞避免
- 如果重传未抵达就发生timeout,则cwnd=1,sstresh=cwnd/2—>慢启动
| |
| 小结 | TCP拥塞控制称为”additive increase,multiplicative decrease”(加性增,乘性减,AIMD),因此期cwnd变化情况如右图所示* | 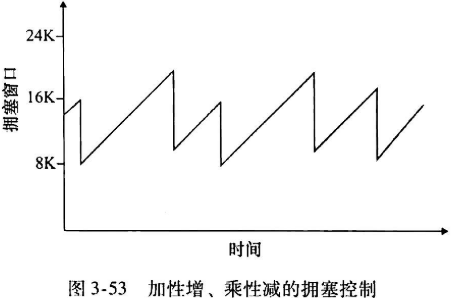 |
|
- TCP吞吐量(**不做要求,记住公式**)
设cwnd长度为w字节,AIMD机制使得连接传输速率在w/2RTT(减半)和W/RTT(起始)之间变化(递增),因此:
- 经高带宽路径的TCP(long,fat pipe)(不做要求)
假设1500字节的seg和100ms的RTT,10Gbps发送速率.要求达到10Gbps的吞吐量,上述公式求得W应该达到83333个seg,此时关注seg的丢失,需要保证考虑丢失的情况下依然保证10Gbps的速率

7.4 TCP公平性
| 公平性 | 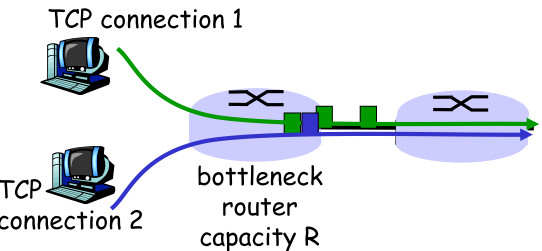 |
如果K个TCP连接共享带宽为R的瓶颈链路,每条链接应该达到R/K的平均速率 |
|---|---|---|
| TCP |
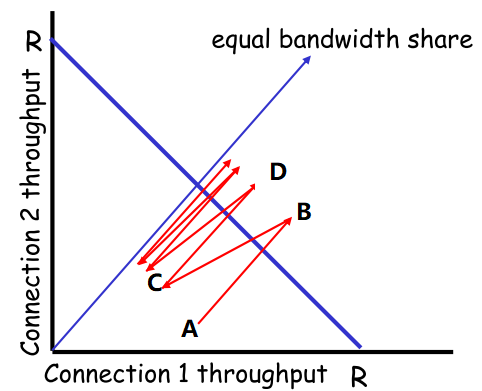 |
红线:实际吞吐量 蓝线:平均值 - A->B:起始,此时连接1,2共同进入慢启动,带宽和 - C->D:与A->B类似 |
因此TCP实现了公平性 |
| 并行TCP
|
- 因为无法阻止TCP应用创建多个并行连接,公平性无法解决
- 一个app可以创建多个TCP连接传输一个对象,从而抢占大部分带宽
| |
| UDP | 实时多媒体(Internet电话,视频会议)不愿意在TCP运行,因为不想被传输速率遏制.使用UDP时:即便网络拥塞,数据也要以恒定速率发送,即便丢包,不愿意把速率降至”公平”,以保证不丢包 | |
MindMap

若有收获,就点个赞吧
0 人点赞
