词法分析器:从源码中读取字符,转换成逻辑单元/词法单元(tokens)
3.1 词法单元,词素,模式
| Token | 词法单元 |
|---|---|
| Lexeme | 词素,源程序的字符序列,可用于匹配 |
| Pattern | 模式,描述一个Token的Lexeme可能具有的形式,可匹配多个符号串 |
3.2 词法单元说明
Regular Expression, 正则表达式
| 意义 | 代表了字符串的patterns |
|---|---|
| 组成 | 一系列定义好的字符组合成正则式r |
| 其他概念 | - 与regex匹配的字符串叫做r的语言language,L(R) - 可用字符叫做符号symbols - 可用字符集合叫做字母表alphabet,Σ |
| 注意 | - 单字符集合的regex匹配自己本身: - L(a)={a},表示与正则式a匹配的字符串只有a - 空字符使用ε,L(ε)={ε} |
regex的运算
| 运算 | 优先级 | 描述 |
|---|---|---|
| 选择运算 | 最低 | “r|s”,表示匹配r或s中的一个,不能同时匹配也不能匹配ε |
| 连接运算 | 中等 | “rs”,表示匹配rs的连接,不能只匹配其中一个 |
| 闭包/重复 | 最高 | “r“,表示对前的r重复0到有限次的匹配 - ⭐L((ab)*)={ε,ab,abab,…} |
3.3 tokens的识别—状态转换图
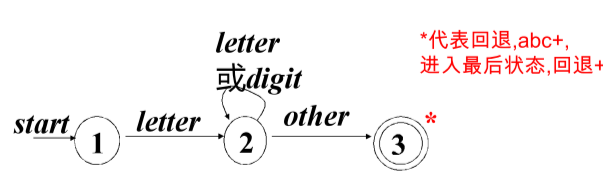
| 转换 transition | 箭头+匹配条件 |
|---|---|
| 开始状态 start | start |
| 接收状态 accepting | 两个同心圆,代表识别的结束 |
| 回退 backtracking | 接收状态+*,表示回退,即不接受最后一个传入字符 |
3.4 正规式->自动机
参考链接: 编译原理:有穷自动机(DFA与NFA)
- 确定性有穷自动机(DFA):从每一个状态只能发出一条具有某个符号的边,不能出现同一个符号出现在同一状态发出的两条边上
- 非确定性有穷自动机(NFA):允许从一个状态发出多条具有相同符号的边,甚至允许发出标有ε符号的边,即NFA可以不输入任何字符就自动沿ε边转换到下一个状态
Rex to NFA
三种运算的转换
| rs | 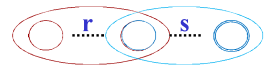 |
|---|---|
| r|s | 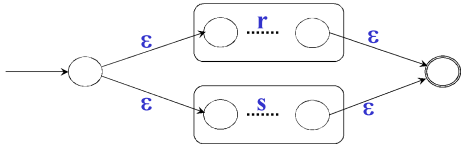 |
| r* | 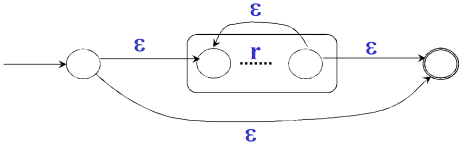 |
举例:letter(letter|digit) *(注意优先级)**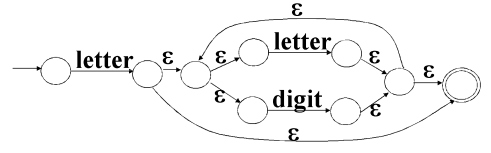
NFA to DFA
概念
| ε-closure | 状态集T的ε闭包,可由0或多次ε转换从T中状态到达的所有状态集合 |
|---|---|
| move[T,a] | 所有可以从T中某一状态出发,经过一条a(可跳过a边前的任意条ε边)可抵达的所有状态集合 |
| Dtran[T,a] | Dtran[T,a]=ε-closure(move[T,a]) Dtran[T,a]就是状态集T经过一条a可达到的所有状态的集合 |
子集构造法
- 构造转换表
- 确定表头:表列数=字母表字符数+1
- 填表:一行一列为ε-closure(S0),初始状态的闭包,依次求Dtran[]
- 循环:直到所有Dtran[]都在第1列上出现过为止
- 重命名状态
每列子集都作为状态重新编号,把第1行第1列作为初态,以1代表,凡含有接收态的状态都作终态,其余为非初非终态

若有收获,就点个赞吧
0 人点赞
