之前在计组和操作系统都学过Cache映射问题,每本书的定义都不太一样,这里统一总结为CSAPP的描述
场景
指令指示CPU从主存地址A处读取内存字w,此时CPU把A发送给cache:
- 当L1中有w的缓存副本,cache hit
- 当L1无w的缓存副本,cache miss
- L1向main memory请求w的副本,放入自己的cache line后提取出w返回给CPU
关注的点:
cache如何确定请求是否命中,然后提取请求的字—分为三步“组(set)选择,行(block)匹配,字(word)抽取”,在了解过程之前需要认识cache的组织结构
cache结构和分类
结构
| 对一个计算机系统来说: - 主存和cache都被分成等大的block - 当其RAM地址共有m位时,可以产生2个有效地址 - cache被组织成一系列缓存组(cache set),共有S=2个set,每个set中有E个缓存行(cache line) - 每一行包含一个块(block),每一块的数据大小B=2字节,行内还包含一个有效位(valid),指明是否包含有意义信息;一个tag标记,唯一标识当前line中的block - 综合一个cache的结构可用四元组(S,E,B,m)来描述,其总大小解为S×E×B(组数块数每块大小) ⭐行,组,块辨析 - 块:固定大小信息包,在cache和主存中直接传递 - 行:cache中的一个容器,存储块+有效位+tag等 - 组:一个或多个行的 |
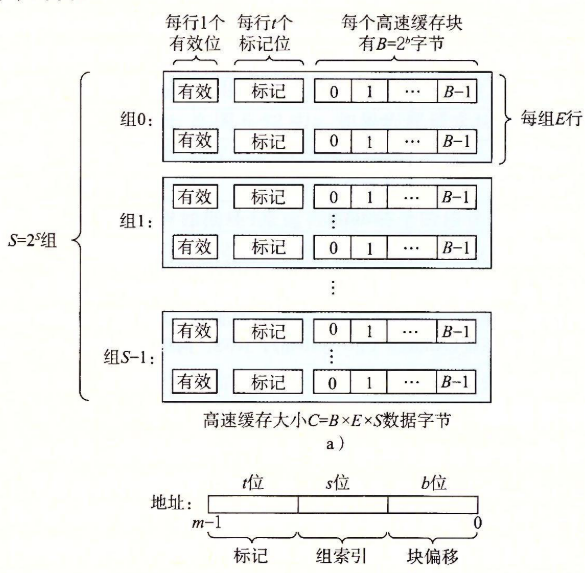 |
|---|---|
分类
根据set和line的不同组织方式,cache和main memory之间的映射有三种方式:
- 直接映射:S组,每组一行,E=1
- 组关联映射:E路组关联,分为S组.每组E行
- 全关联映射:1组,S=1,包含所有行
直接映射
| 概念 | cache的每set只有1行,即只能存放一个block,而主存中的一个块只能映射到Cache的某一特定块中去 极易冲突,效率低下:假设共N块cache,对应RAM中的位置X,映射到cache中Y=XmodN,如右图示意: |
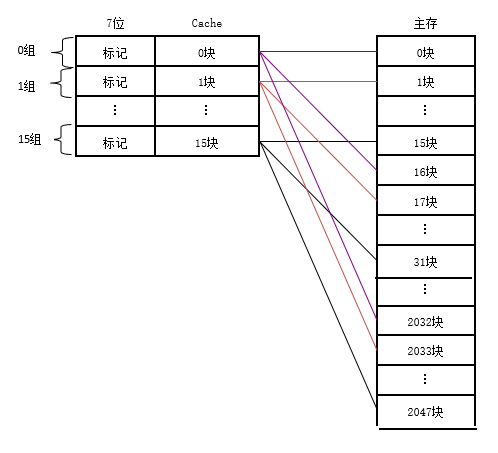 |
|---|---|---|
| 地址A | - 总长m:由RAM大小确定 - set:决定哪一个组—组索引 - tag:决定哪一行(块)—行匹配 - offset: 决定块内字位置—字提取 |
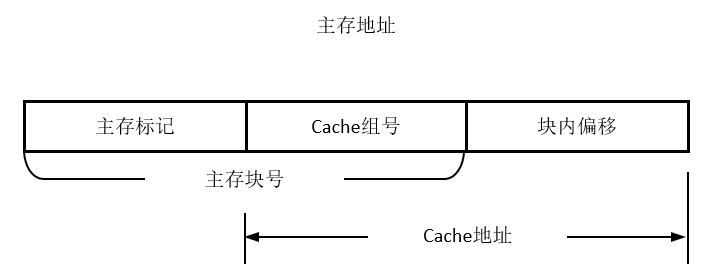 |
| 举例 | 在一台32位机器上,假设每字是4字节,已知RAM大小2bits,cache有16块,求cache的地址 总长14bits,16=2,4位set,由已知每块有8个words,则3位offset,14-4-3=7,7位用于标记块(tag) |
|
| cache hit | ||
| 组索引 | 下图当地址的set为0001时,映射到cache的set1中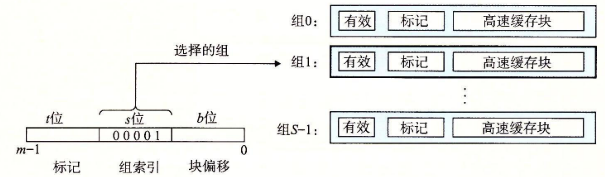 |
|
| 行匹配 | 索引到指定set后需要确定组i中是否有一行包含请求的字w的副本,此时 1. 检测有效位是否为1 1. 核对tag位,确定block |
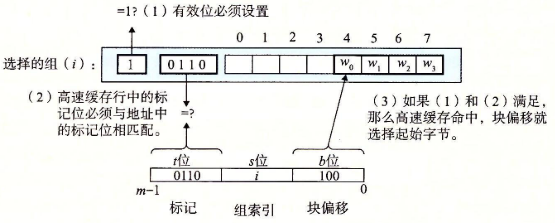 | |
| 字提取 | 满足1,2后通过offset确定块内字,如👆offset=100,即偏移4字节,即第二个word | |
| cache miss | | |
| 行替换 |
| |
| 字提取 | 满足1,2后通过offset确定块内字,如👆offset=100,即偏移4字节,即第二个word | |
| cache miss | | |
| 行替换 |
- 当不满足1,此时发生冷不命中—>重新取一块填补空行
- 当不满足2,此时发生冲突不命中—>**替换当前行
| |
组关联映射
| 概念 | 对比直接映射:
直接映射高冲突率是因为每个set只有一行,当允许每个set有多行,此时多行可同时存在cache中,可明显降低冲突率
E路组关联,即分为S组.每组E行,如右图位2路组关联映射 | 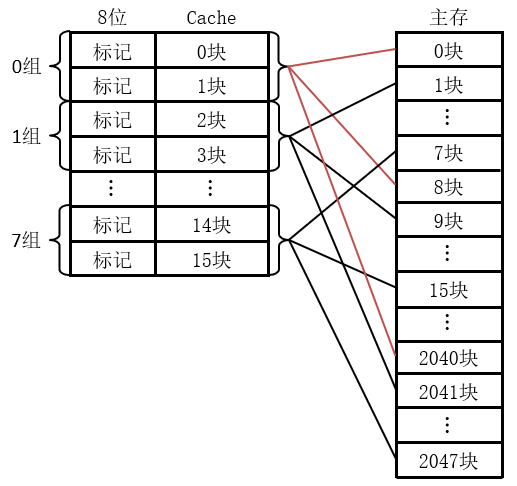 |
| :—-: | —- | :—-: |
| 地址A |
|
| :—-: | —- | :—-: |
| 地址A |
- 总长m:由RAM大小确定
- set:决定哪一个组—组索引
- tag:决定哪一行(块)—行匹配
- offset: 决定块内字位置—字提取
| |
| 举例 | RAM大小2bits,16块cache,每块8个字,求2路组关联映射地址组成
总长14bits,16/2=2,3位set,由已知每块有8个words,则3位offset,14-4-3=7,7位用于标记块(tag) | |
| cache hit | | |
| 组索引 | 下图当地址的set为0001时,映射到cache的set1中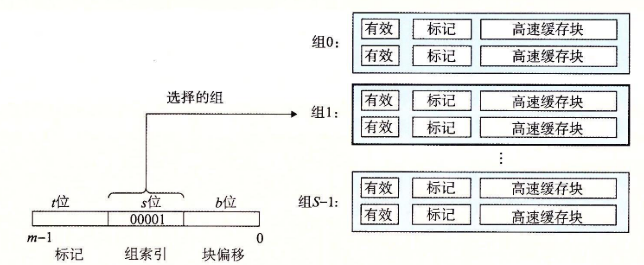 | |
| 行匹配 | 索引到指定set后需要确定组i中是否有一行包含请求的字w的副本,此时
| |
| 行匹配 | 索引到指定set后需要确定组i中是否有一行包含请求的字w的副本,此时
1. 检测有效位是否为1
1. 核对tag位,确定block
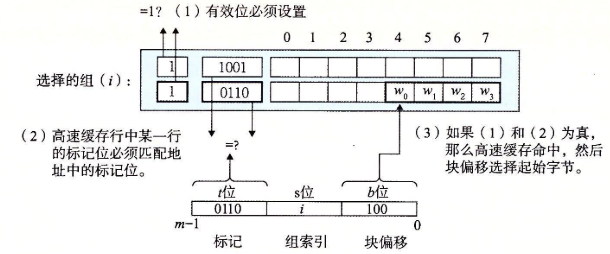 | |
| 字提取 | 满足1,2后通过offset确定块内字,如👆offset=100,即偏移4字节,即第二个word | |
| cache miss | | |
| 行替换 |
| |
| 字提取 | 满足1,2后通过offset确定块内字,如👆offset=100,即偏移4字节,即第二个word | |
| cache miss | | |
| 行替换 |
- 当不满足1,此时发生冷不命中—>重新取一块填补空行
- 当不满足2,此时发生冲突不命中—>通常**LRU替换组内行
| |
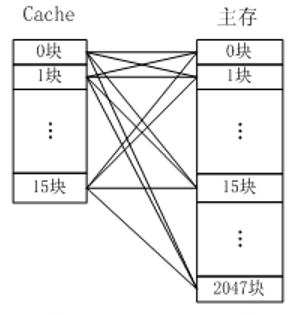
全关联映射
| 概念 | 只有1个set,当前set包含所有的行 - 全关联允许主存中数据块放到cache中任何位置,但是访问时需要将所有cache遍历一次,需要硬件支持 |
 |
|---|---|---|
| 地址A | - 总长m:由RAM大小确定 - tag:决定哪一行(块)—行匹配 - offset: 决定块内字位置—字提取 |
 |
| 举例 | RAM大小2bits,16块cache,每块8个字,求全关联映射地址组成 总长14bits,3位offset,14-3=11,11位用于标记块(tag) |
|
| cache hit | ||
| 组索引 | 全关联没有set位,默认set=0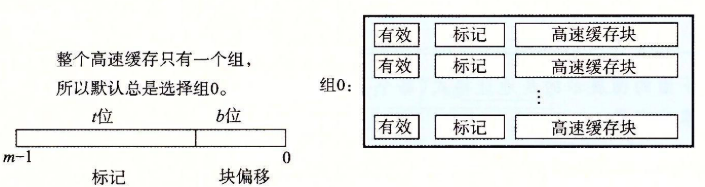 |
|
| 行匹配 | 索引到指定set后需要确定组i中是否有一行包含请求的字w的副本,此时 1. 检测有效位是否为1 1. 核对tag位,确定block |
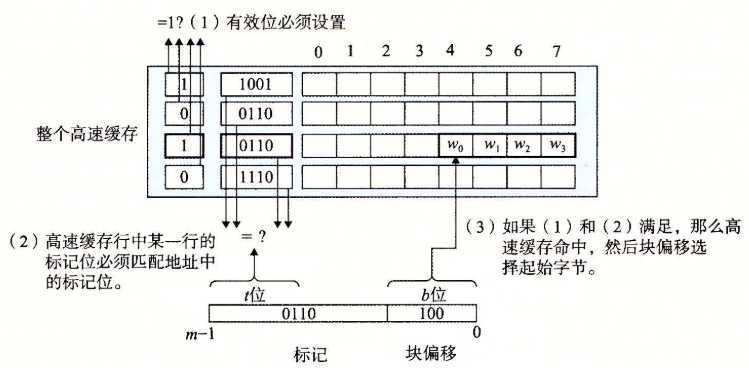 | |
| 字提取 | 满足1,2后通过offset确定块内字,如👆offset=100,即偏移4字节,即第二个word | |
| cache miss | | |
| 行替换 |
| |
| 字提取 | 满足1,2后通过offset确定块内字,如👆offset=100,即偏移4字节,即第二个word | |
| cache miss | | |
| 行替换 |
- 当不满足1,此时发生冷不命中—>重新取一块填补空行
- 当不满足2,此时发生冲突不命中—>通常**LRU替换组内行
| |
写策略
当cache中的字w被更新后需要保证主存中的对应块也被更新,有两种策略:write back和write through
write through
即当cache更新后,立即把block写回到下一级的cache或主存中
write back
当cache更新后,推迟下一级block更新,直到当前block需要被换出时才写回
选择题知识点
- 编写cache友好程序使得命中率提升,可以减少wall time
⭐给定以下代码,当使用32字节cache line的全关联映射时,数组a需要从主存中取多少字节数据
int a[100];for (i = 0; i < 17; sum += a[i], i++);
最多96次,首先未说明cache是否为空,假设最坏情况,初始为空,每次循环时取一行,即32字节,其中可包含8个int,循环需要读取数组a[0]~a[16],此时未命中情况为a[0],a[8],a[16]总共读取了a[0]~a[23],对应4*24=96字节
LRU是最有效的cache替换策略,是因为考虑了”引用局部性”
⭐给定代码
int data[1 << 20];void callee(int x) {int i, result;for (i = 0; i < (1 << 20); i += x) {result += data[i];}}
通过以上函数可确定的是:cache line大小
需要明确,循环执行时间长短由数组的内存访问次数决定,通过给定不同的步长x进行时间统计,当x大于cache line时,每次循环都miss,此时时间会明显变长,x即为cache line大小当需要行替换时,最实际的实现是:随机替换(LRU实现困难)
- 计算机中cache级别各不相同,且不一定有data cache和instruction cache
- 一个code+data<256k字节的程序在cache空间512k字节的全关联映射下:无法确定fetch情况,信息太少
- ⭐在32位机上,当cache有128行32字节cache line时,给定下方代码,假设a[],b[]起始地址位0x800000和0x801000,则执行结束时cache需要从主存中取多少字节
1088字节,由已知,内存地址32位,128=2,中7位作为set,每个block8个字,需3位offset,则tag有22位.补全ab起始地址,为0x00800000和0x00801000int b[1024];int a[1024];for (i = 0; i < 17; sum += a[i] + b[i], i++);
开始循环时a[0]和b[0]的set都相同,占据同一行,a[0]发生冷不命中,b[0]发生冲突不命中
a[1]对应0x00800001,b[1]对应0x00801001,还是占据开始的set,a[1],b[1]都发生冲突不命中
…以此类推,17次循环每次都发生两次cache miss,每次都读取232字节的数据,总共读取232*17=1088字节数据

若有收获,就点个赞吧
0 人点赞
