布尔运算
参考 https://docs.python.org/zh-cn/3.9/library/stdtypes.html#boolean-operations-and-or-not
这些属于布尔运算,按优先级升序排列:
| 运算 | 结果 | 注释 |
|---|---|---|
x or y |
if x is false, then y, else x | (1) |
x and y |
if x is false, then x, else y | (2) |
not x |
if x is false, then True, else False |
(3) |
注释:
or这是个短路运算符,因此只有在第一个参数为假值时才会对第二个参数求值。and这是个短路运算符,因此只有在第一个参数为真值时才会对第二个参数求值。not的优先级比非布尔运算符低,因此not a == b会被解读为not (a == b)而a == not b会引发语法错误。
类型是否可变
参考 https://docs.python.org/zh-cn/3.9/reference/datamodel.html#objects-values-and-types
有些对象的 值 可以改变。值可以改变的对象被称为 可变的;值不可以改变的对象就被称为 不可变的。(一个不可变容器对象如果包含对可变对象的引用,当后者的值改变时,前者的值也会改变;但是该容器仍属于不可变对象,因为它所包含的对象集是不会改变的。因此,不可变并不严格等同于值不能改变,实际含义要更微妙。) 一个对象的可变性是由其类型决定的;例如,数字、字符串和元组是不可变的,而字典和列表是可变的。
逻辑值检测
https://docs.python.org/zh-cn/3.9/library/stdtypes.html#truth-value-testing
任何对象都可以进行逻辑值的检测,以便在 [if](https://docs.python.org/zh-cn/3.9/reference/compound_stmts.html#if) 或 [while](https://docs.python.org/zh-cn/3.9/reference/compound_stmts.html#while) 作为条件或是作为下文所述布尔运算的操作数来使用。
一个对象在默认情况下均被视为真值,除非当该对象被调用时其所属类定义了 [__bool__()](https://docs.python.org/zh-cn/3.9/reference/datamodel.html#object.__bool__) 方法且返回 False 或是定义了 [__len__()](https://docs.python.org/zh-cn/3.9/reference/datamodel.html#object.__len__) 方法且返回零。 下面基本完整地列出了会被视为假值的内置对象:
- 被定义为假值的常量:
None和False。 - 任何数值类型的零:
0,0.0,0j,Decimal(0),Fraction(0, 1) - 空的序列和多项集:
'',(),[],{},set(),range(0)查看内置类型源码
1.在开发工具中,打出相关类型的类型字符
2.按住键盘ctrl键,然后鼠标移动到某个类型字符
3.点击鼠标左键
内存分配原理图
同一作用域内,赋值符=会改变变量的引用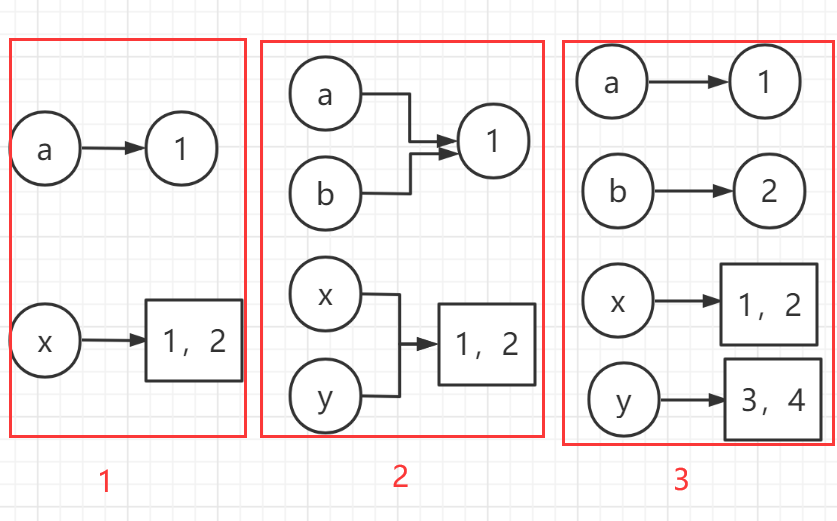 ```python
```pythonpython默认按引用赋值
不可变类型
a = 1 b = a
可变类型
x = [1, 2] y = x
两种类型的结果一致:赋值符=按引用传递
print(‘id(a):’, id(a), ‘id(b):’, id(b)) print(‘id(x):’, id(x), ‘id(y):’, id(y)) print(‘\n’)
b = 2 y = [3, 4]
print(‘id(a):’, id(a), ‘id(b):’, id(b)) print(‘id(x):’, id(x), ‘id(y):’, id(y))
‘’’ id(a): 2214637889840 id(b): 2214637889840 id(x): 2214639660032 id(y): 2214639660032
id(a): 2214637889840 id(b): 2214637889872 id(x): 2214639660032 id(y): 2214639690944 ‘’’
<a name="52GsU"></a># 内置常量> 参考 [https://docs.python.org/zh-cn/3.9/library/constants.html](https://docs.python.org/zh-cn/3.9/library/constants.html)以下值内存中只有一份<br />`False`<br />`True`<br />`None`<a name="r1ahj"></a># 算数运算精度丢失问题浮点数(小数)在计算机中实际是以二进制存储的,并不精确。<br />比如0.1是十进制,转换为二进制后就是一个无限循环的数:<br />`0.00011001100110011001100110011001100110011001100110011001100`<br />python是以双精度float(64bit)来保存浮点数的,后面多余的会被砍掉,所以在电脑上实际保存的已经小于0.1的值了,后面拿来参与运算就产生了误差。
from decimal import Decimal
print(0.1 + 0.2) # 0.30000000000000004
a = Decimal(str(0.1)) # Decimal只接受字符串类型 b = Decimal(str(‘0.2’)) print(a + b) # 0.3
<a name="uUZA3"></a># 垃圾回收机制<a name="QnKSy"></a>## 什么是垃圾回收机制垃圾回收机制(简称GC)是Python解释器自带一种机,专门用来回收不可用的变量值所占用的内存空间<a name="h4J4G"></a>## 为什么要用垃圾回收机制程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃,因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。<a name="uAqrL"></a>## 理解GC原理需要储备的知识堆区与栈区<br />在定义变量时,变量名与变量值都是需要存储的,分别对应内存中的两块区域:堆区与栈区。
1、变量名与值内存地址的关联关系存放于栈区
2、变量值存放于堆区,内存管理回收的则是堆区的内容,
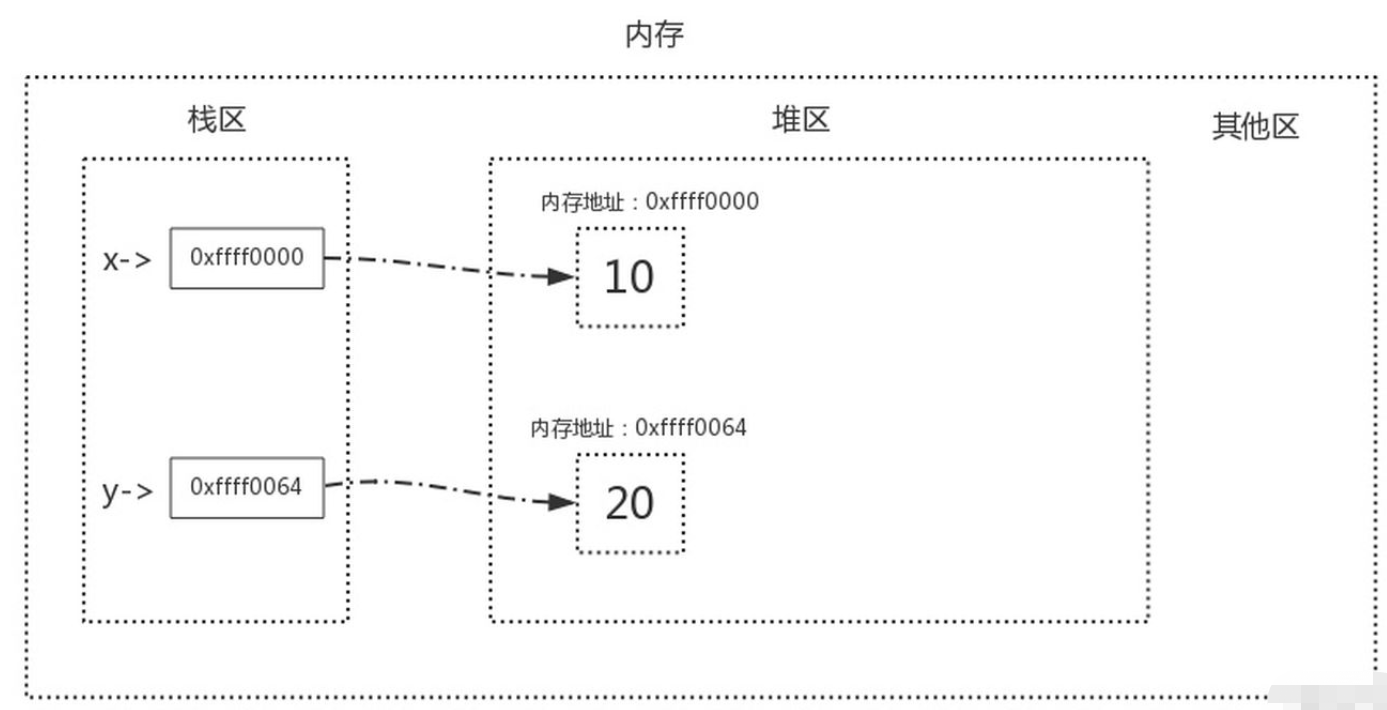<br />当我们执行x=y时,内存中的栈区与堆区变化如下<br />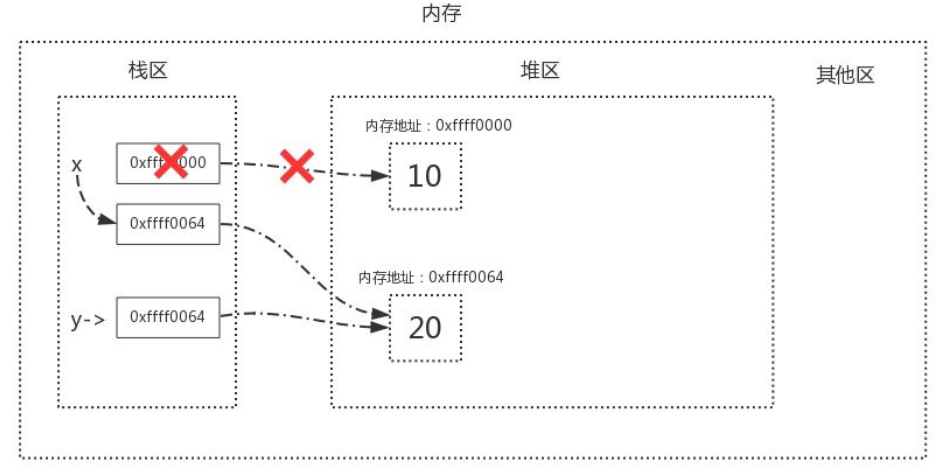<br />**直接引用与间接引用**<br />直接引用指的是从栈区出发直接引用到的内存地址。<br />间接引用指的是从栈区出发引用到堆区后,再通过进一步引用才能到达的内存地址。```pythonx = 10 # 值10被变量名x直接引用l2 = [20, 30] # 列表本身被变量名l2直接引用,包含的元素被列表间接引用l1 = [x, l2] # 列表本身被变量名l1直接引用,包含的元素被列表间接引用
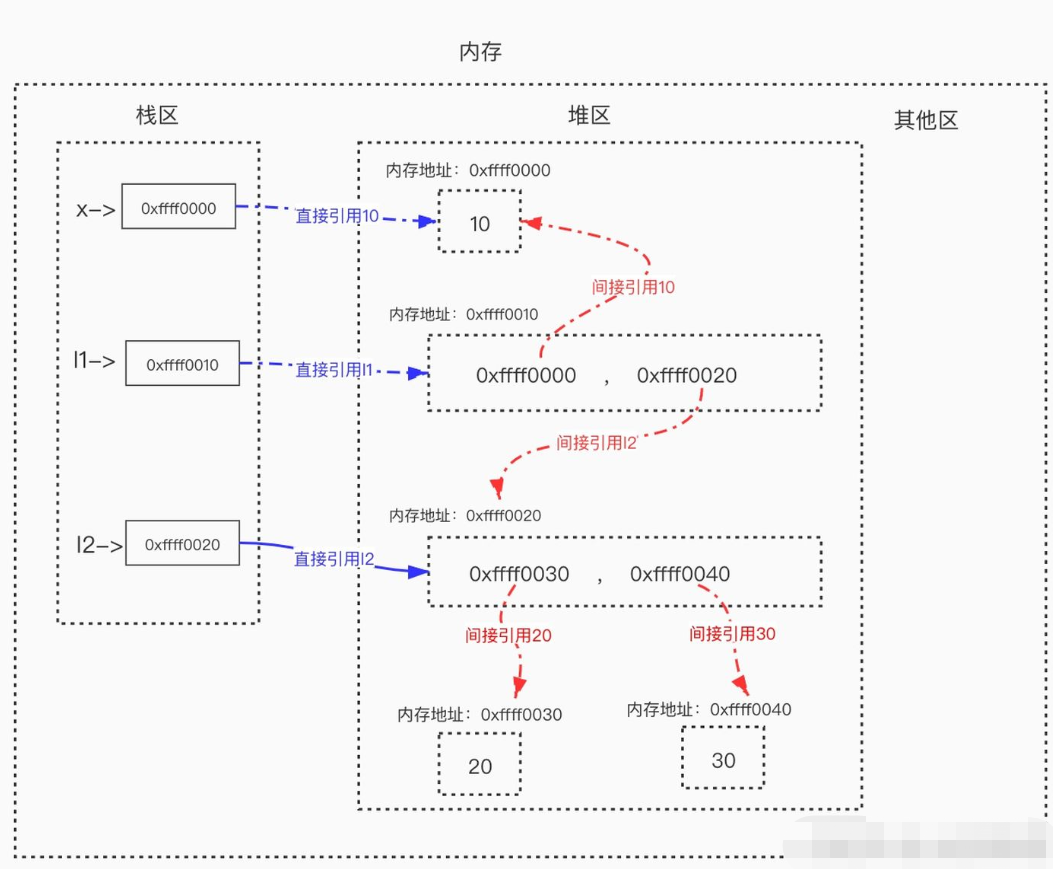
垃圾回收机制原理分析
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
引用计数
引用计数就是:变量值被变量名关联的次数
如:age=18
变量值18被关联了一个变量名age,称之为引用计数为1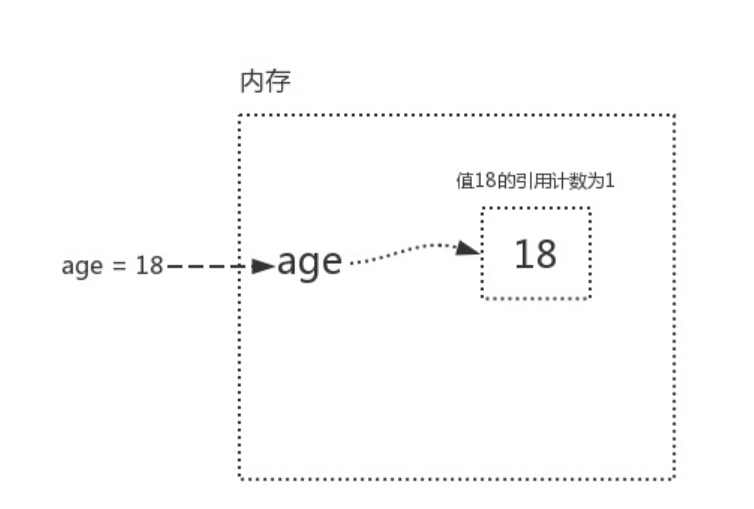
引用计数增加:
age=18 (此时,变量值18的引用计数为1)
m=age (把age的内存地址给了m,此时,m,age都关联了18,所以变量值18的引用计数为2)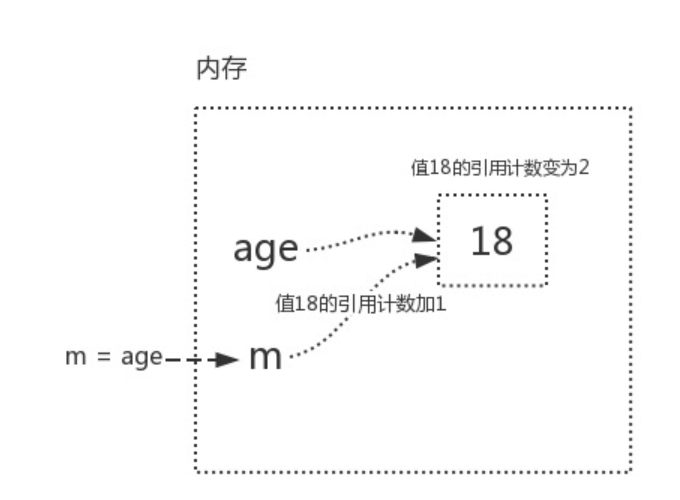
引用计数减少:
age=10(名字age先与值18解除关联,再与3建立了关联,变量值18的引用计数为1)
del m(del的意思是解除变量名x与变量值18的关联关系,此时,变量18的引用计数为0)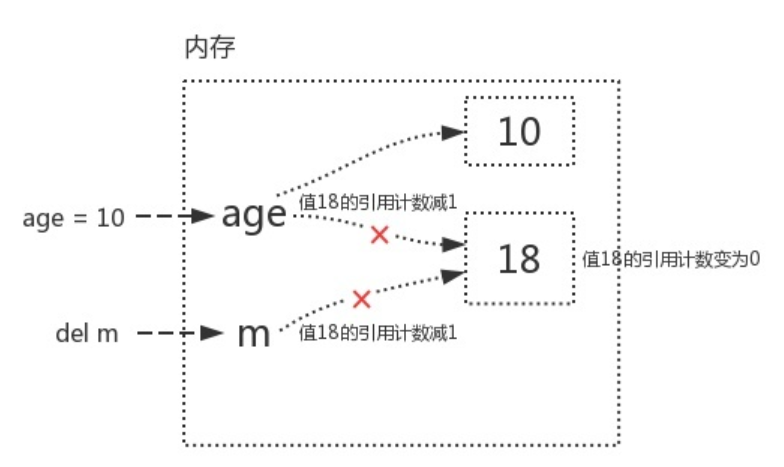
值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
引用计数的问题与解决方案
问题一:循环引用
引用计数机制存在着一个致命的弱点,即循环引用(也称交叉引用)
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2>>> l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1>>> l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1>>> l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2>>> l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2# l1与l2之间有相互引用# l1 = ['xxx'的内存地址,列表2的内存地址]# l2 = ['yyy'的内存地址,列表1的内存地址]>>> l1['xxx', ['yyy', [...]]]>>> l2['yyy', ['xxx', [...]]]>>> l1[1][1][0]'xxx'
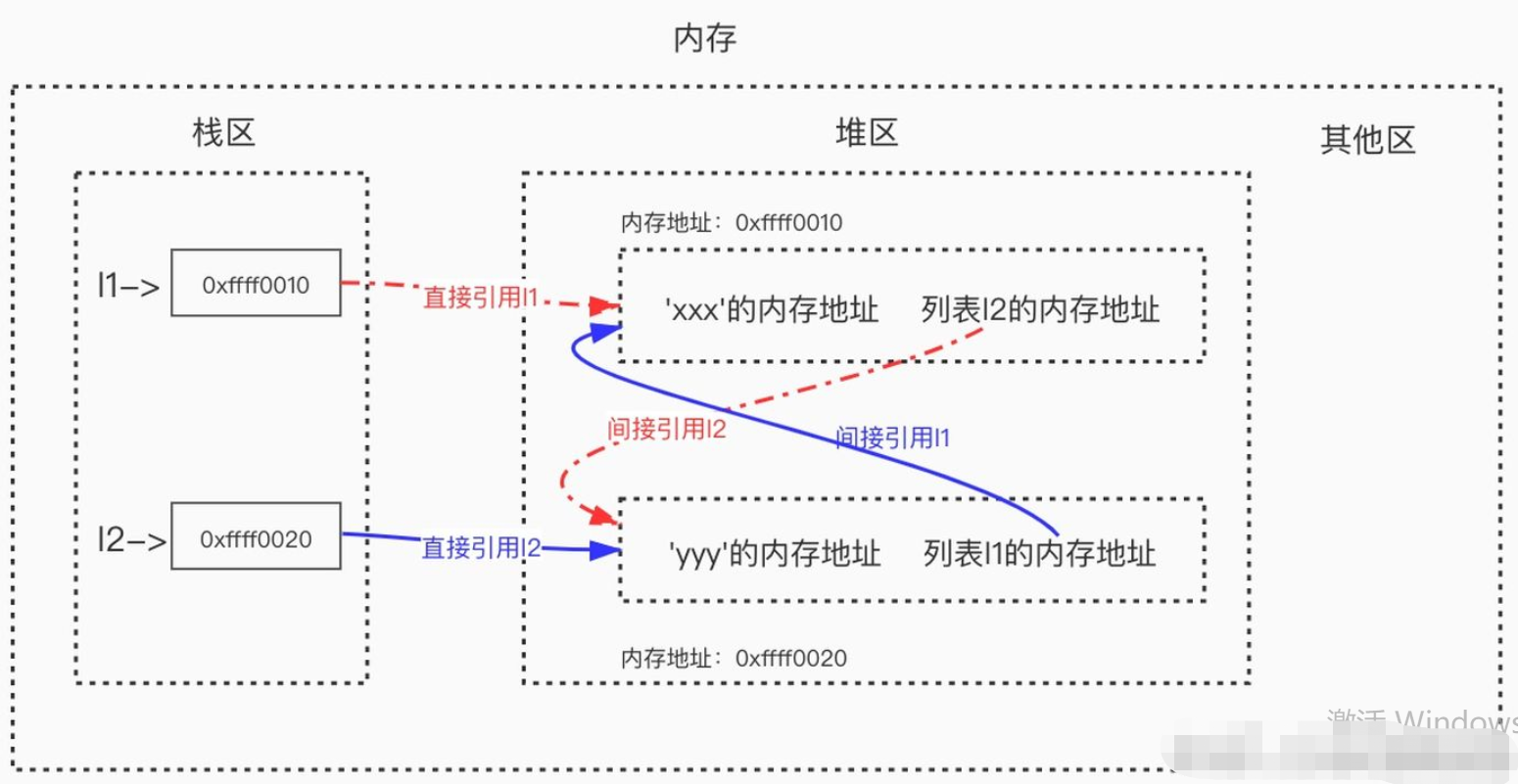
循环引用会导致:值不再被任何名字关联,但是值的引用计数并不会为0,应该被回收但不能被回收,什么意思呢?试想一下,请看如下操作
>>> del l1 # 列表1的引用计数减1,列表1的引用计数变为1>>> del l2 # 列表2的引用计数减1,列表2的引用计数变为1
此时,只剩下列表1与列表2之间的相互引用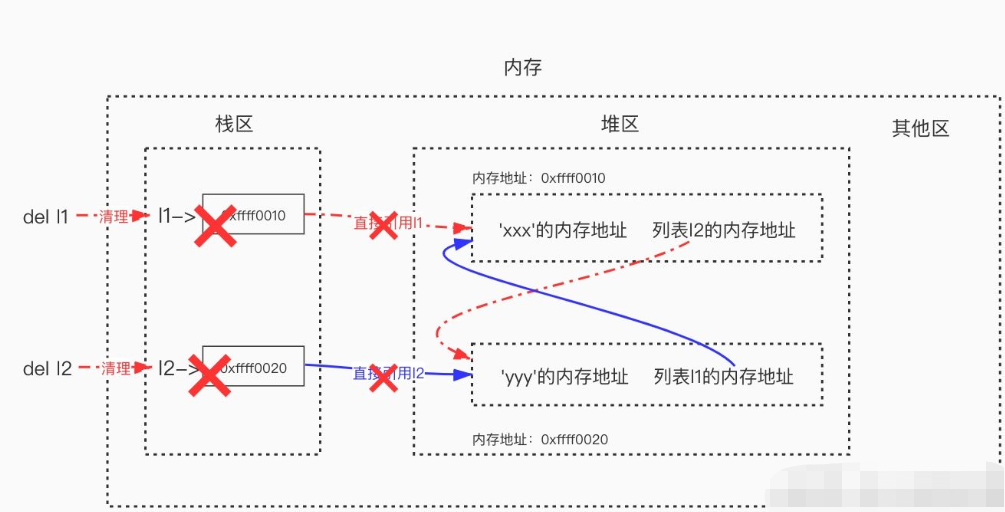
但此时两个列表的引用计数均不为0,但两个列表不再被任何其他对象关联,没有任何人可以再引用到它们,所以它俩占用内存空间应该被回收,但由于相互引用的存在,每一个对象的引用计数都不为0,因此这些对象所占用的内存永远不会被释放,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区别。 所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
解决方案:标记-清除
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。
标记/清除算法的做法是当应用程序可用的内存空间被耗尽时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
#1、标记通俗地讲就是:栈区相当于“根”,凡是从根出发可以访达(直接或间接引用)的,都称之为“有根之人”,有根之人当活,无根之人当死。具体地:标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。#2、清除清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
基于上例的循环引用,当我们同时删除l1与l2时,会清理到栈区中l1与l2的内容以及直接引用关系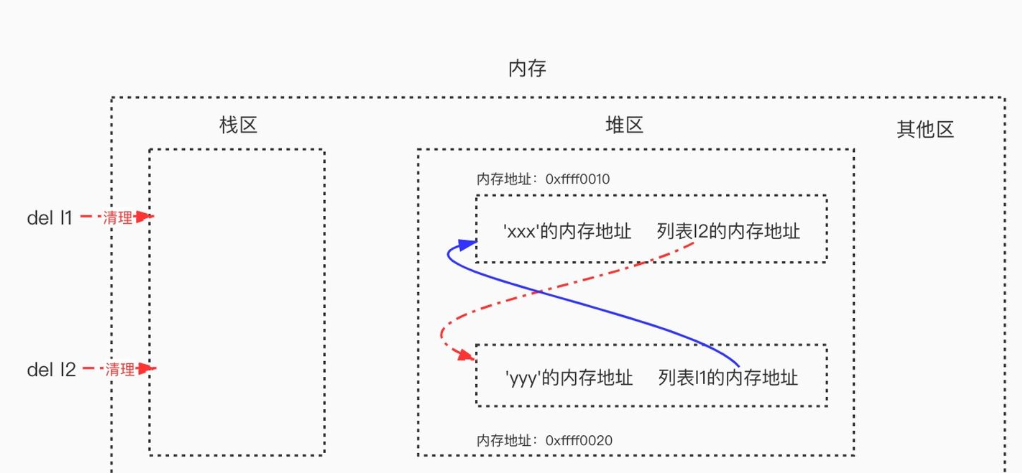
这样在启用标记清除算法时,从栈区出发,没有任何一条直接或间接引用可以访达l1与l2,即l1与l2成了“无根之人”,于是l1与l2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
问题二:效率问题
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
解决方案:分代回收
分代:
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低,具体实现原理如下:
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
回收:
回收依然是使用引用计数作为回收的依据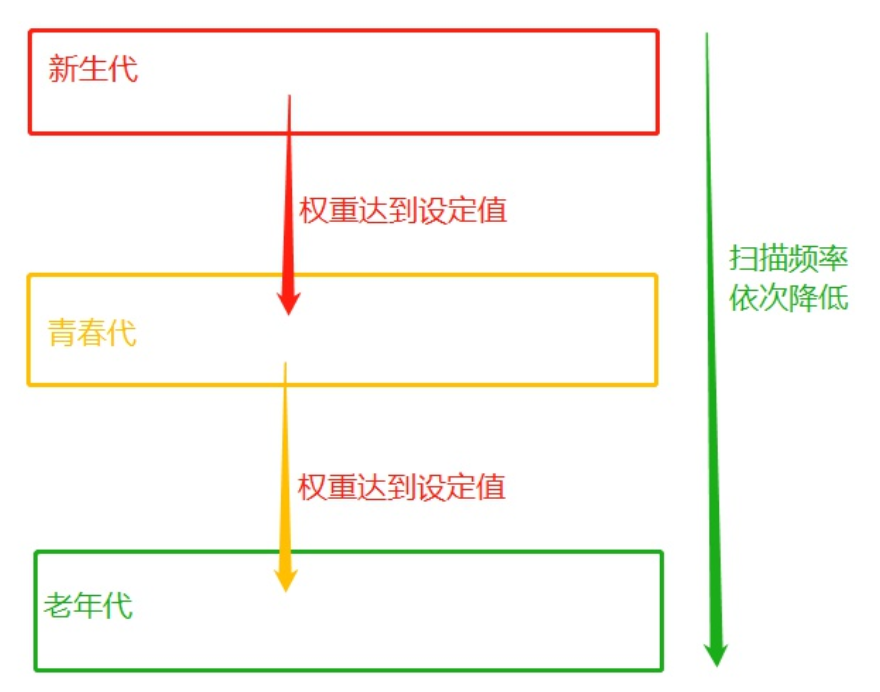
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
#例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,这就到导致了应该被回收的垃圾没有得到及时地清理。没有十全十美的方案:毫无疑问,如果没有分代回收,即引用计数机制一直不停地对所有变量进行全体扫描,可以更及时地清理掉垃圾占用的内存,但这种一直不停地对所有变量进行全体扫描的方式效率极低,所以我们只能将二者中和。综上垃圾回收机制是在清理垃圾&释放内存的大背景下,允许分代回收以极小部分垃圾不会被及时释放为代价,以此换取引用计数整体扫描频率的降低,从而提升其性能,这是一种以空间换时间的解决方案
intern机制
参考 https://docs.python.org/zh-cn/3.9/library/sys.html#sys.intern
作用:优化
对于短字符串,将其赋值给多个不同的对象时,内存中只有一个副本,多个对象共享该副本。长字符串不遵守驻留机制。
驻留适用范围
由数字,字符和下划线(_)组成的python标识符以及整数[-5,256]。
整数
在python里,有一个神奇的机制:常量池
Python 内部做了一些优化,Python把常用的整数对象都预先缓存起来
特点:
1.整数范围: -5 — 257
2.它永远不会被GC机制回收, 只要定义的整数变量在 范围: -5 — 256内,会被全局解释器重复使用, 257除外
3.只要在这个 -5 — 256 范围内,创建同一区域代码块的变量的值如果是相等的,那么不会创建新对象(python万物皆对象,数值也是对象),直接引用。
a = 6b = 6print(a is b) # True
def test_a():a = 123print(id(a))def test_b():b = 123print(id(b))c = 123print(id(c)) # 2047782246576test_a() # 2047782246576test_b() # 2047782246576
字符串
>>> str1='jiumo'>>> str2='jiumo'>>> str1 is str2True>>> id(str1)1979078421896>>> id(str2)1979078421896
>>> str3='jiumo wbw'>>> str4='jiumo wbw'>>> str3 is str4False>>> id(str3)1979078402432>>> id(str4)1979078403832
可以看出非数字,字符和下划线(_)组成的字符串并不会触发驻留。python中用is可以比较两个字符串是否是同一个对象,也就是内存地址是否一样。
驻留时机
python中的驻留发生在compile_time,而不是run_time。
>>> str1='jiu'+'mo'>>> str1 is 'jiumo'True>>> str3='jiu'>>> str4=str3+'mo'>>> str4 is 'jiumo'False
优缺点
字符串驻留机制的优缺点如下:
优点:能够提高一些字符串处理任务在时间和空间上的性能,
缺点:在创建或驻留字符串时的会花费更多的时间。
- python标识符的不可变性导致了字符串的改动不是采用replace,而是重新创建对象。为了节省内存,涉及到字符串的改动时通常用join()而非+。因为+会多次创建对象,而join()只创建一次对象。
- 驻留机制会提升一些时间和空间上的性能,但驻留对象也有所消耗。
注意事项
1、连接字符串
由于字符串的改动不是inplace的操作,需要新建对象,因此不推荐使用+来拼接字符串,推荐使用join函数,因为join函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一次对象。
2、字符串驻留限制
仅包含下划线(_)、字母和数字的字符串会启用字符串驻留机制驻留机制。因为解释器仅对看起来像python标识符的字符串使用intern()方法,而python标识符正是由下划线、字母和数字组成。
总结
当进行两个值的 判断时,如果不确定是否内存地址相同,不建议使用is,而应使用 ==
深浅拷贝
浅拷贝
- 不可变类型,不拷贝。 ```python import copy
v1 = “mf” print(id(v1)) # 140652260947312
v2 = copy.copy(v1) print(id(v2)) # 140652260947312
按理说拷贝v1之后,v2的内存地址应该不同,但由于python内部优化机制,内存地址是相同的,因为对不可变类型而言,如果以后修改值,会重新创建一份数据,不会影响原数据,所以,不拷贝也无妨。- **可变类型,只拷贝第一层。**```pythonimport copyv1 = ["mf", "root", [44, 55]]print(id(v1)) # 140405837216896print(id(v1[2])) # 140405837214592v2 = copy.copy(v1)print(id(v2)) # 140405837214784print(id(v2[2])) # 140405837214592
import copya = [1, 2, 3, 4, ['a', 'b']] #原始对象b = a #赋值,传对象的引用c = copy.copy(a) #对象拷贝,浅拷贝d = copy.deepcopy(a) #对象拷贝,深拷贝a.append(5) #修改对象aa[4].append('c') #修改对象a中的['a', 'b']数组对象print( 'a = ', a )print( 'b = ', b )print( 'c = ', c )print( 'd = ', d )
('a = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])('b = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])('c = ', [1, 2, 3, 4, ['a', 'b', 'c']])('d = ', [1, 2, 3, 4, ['a', 'b']])
编码
三大核心硬件
所有软件都是运行硬件之上的,与运行软件相关的三大核心硬件为cpu、内存、硬盘,我们需要明确三点
#1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的#2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行#3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
什么是字符编码
人类在与计算机交互时,用的都是人类能读懂的字符,如中文字符、英文字符、日文字符等
而计算机只能识别二进制数,详解如下
计算机底层只认识机器码,诸如00001111,语言解释器根据这套编码将字符转换为机器码。
毫无疑问,由人类的字符到计算机中的数字,必须经历一个过程,如下:
翻译的过程必须参照一个特定的标准,该标准称之为字符编码表,该表上存放的就是字符与数字一一对应的关系。
字符编码中的编码指的是翻译或者转换的意思,即将人能理解的字符翻译成计算机能识别的数字
编码发展史
阶段一:一家独大
ASCII:美国的编码,计算机起源于美国,开始网络也没有,计算机的语言和人类语言是不一样的,计算机实际就是用0和1来的组成来表示人来语言的,而美国的语言是英语,文字由字母、数字和英语字符构成,因此,用8个数字(8bit,也就是一个字节即1byte)就可以表示2的8次方个(256种)字符,英语单词目前有几万个,但是不到2的16次方(65536)种形式,因为英语由26个字母组成,计算机不需要表示单词,直接用单个字母表示,26个字母加上一些标点等符号,形式不到256种,因此(8bit)256种形式就能满足需求。
阶段二:诸侯割据、天下大乱
万国码
为了让计算机能够识别中文和英文,中国人定制了GBK
# GBK表的特点:1、只有中文字符、英文字符与数字的一一对应关系2、一个英文字符对应1Bytes一个中文字符对应2Bytes补充说明:1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
每个国家都各自的字符,为让计算机能够识别自己国家的字符外加英文字符,各个国家都制定了自己的字符编码表
# Shift_JIS表的特点:1、只有日文字符、英文字符与数字的一一对应关系# Euc-kr表的特点:1、只有韩文字符、英文字符与数字的一一对应关系
此时,美国人用的计算机里使用字符编码标准是ASCII、中国人用的计算机里使用字符编码标准是GBK、日本人用的计算机里使用字符编码标准是Shift_JIS,如下图所示,
阶段三:分久必合
unicode于1990年开始研发,1994年正式公布,具备两大特点:
#1. 存在所有语言中的所有字符与数字的一一对应关系,即兼容万国字符#2. 与传统的字符编码的二进制数都有对应关系,详解如下
很多地方或老的系统、应用软件仍会采用各种各样传统的编码,这是历史遗留问题。此处需要强调:软件是存放于硬盘的,而运行软件是要将软件加载到内存的,面对硬盘中存放的各种传统编码的软件,想让我们的计算机能够将它们全都正常运行而不出现乱码,内存中必须有一种兼容万国的编码,并且该编码需要与其他编码有相对应的映射/转换关系,这就是unicode的第二大特点产生的缘由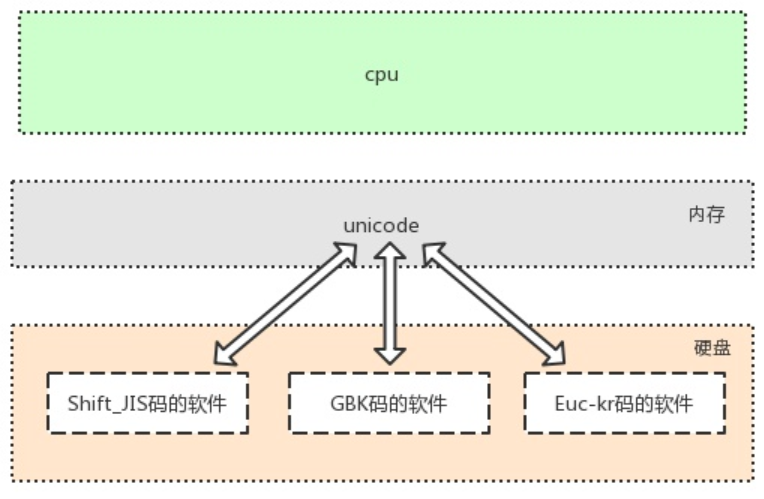
本编辑器输入任何字符都是最新存在于内存中,是unicode编码的,存放于硬盘中,则可以转换成任意其他编码,只要该编码可以支持相应的字符
# 英文字符可以被ASCII识别英文字符--->unciode格式的数字--->ASCII格式的数字# 中文字符、英文字符可以被GBK识别中文字符、英文字符--->unicode格式的数字--->gbk格式的数字# 日文字符、英文字符可以被shift-JIS识别日文字符、英文字符--->unicode格式的数字--->shift-JIS格式的数字
编码与解码
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode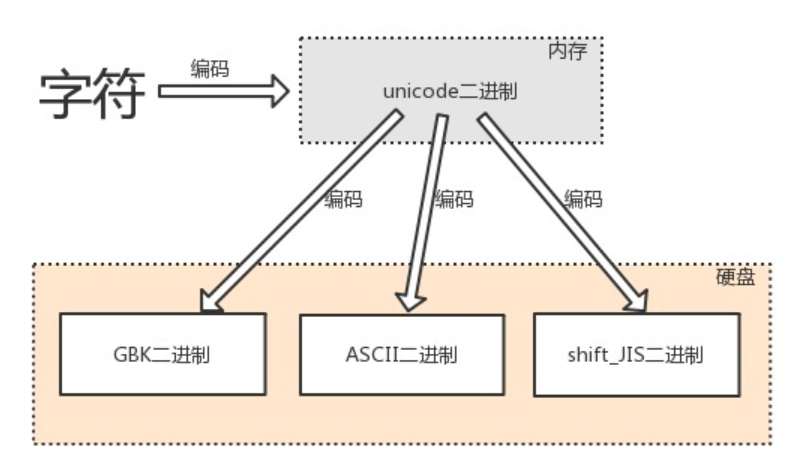
由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode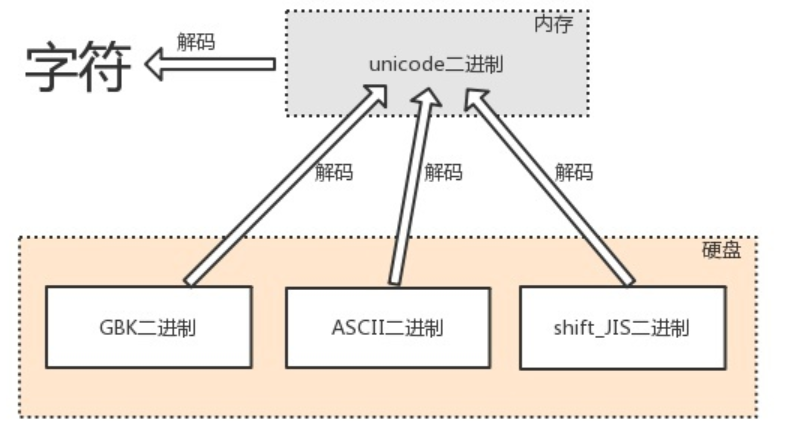
utf-8的由来
理论上是可以将内存中unicode格式的二进制直接存放于硬盘中的,但由于unicode固定使用两个字节来存储一个字符,如果多国字符中包含大量的英文字符时,使用unicode格式存放会额外占用一倍空间(英文字符其实只需要用一个字节存放即可),然而空间占用并不是最致命的问题,最致命地是当我们由内存写入硬盘时会额外耗费一倍的时间,所以将内存中的unicode二进制写入硬盘或者基于网络传输时必须将其转换成一种精简的格式,这种格式即utf-8(全称Unicode Transformation Format,即unicode的转换格式)
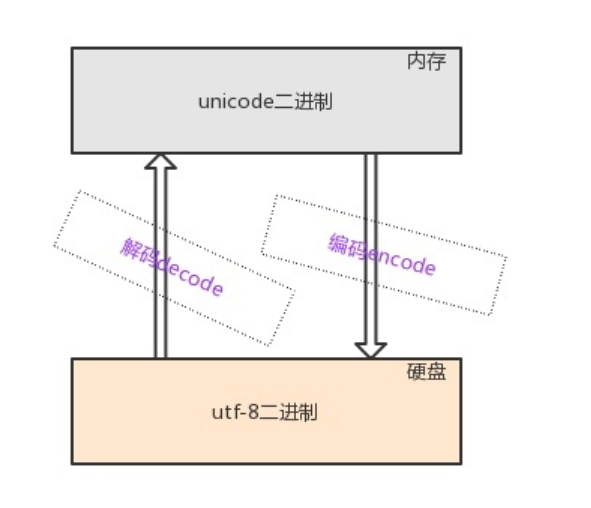
那为何在内存中不直接使用utf-8呢?
utf-8是针对Unicode的可变长度字符编码:一个英文字符占1Bytes,一个中文字符占3Bytes,生僻字用更多的Bytes存储unicode更像是一个过渡版本,我们新开发的软件或文件存入硬盘都采用utf-8格式,等过去几十年,所有老编码的文件都淘汰掉之后,会出现一个令人开心的场景,即硬盘里放的都是utf-8格式,此时unicode便可以退出历史舞台,内存里也改用utf-8,天下重新归于统一
补充
所以开发者挑选内存条的时候,尽可能大点,因为内存是Unicode编码,多占很多空间,数据占用的内存空间实际比硬盘或者网络中数据大一些

若有收获,就点个赞吧
0 人点赞
