排序
session.query(模型).order_by(字段).all()
- 默认排序顺序 升序 asc
- 降序 desc()
1.order_by:可以指定根据这个表中的某个字段进行排序,如果在前面加了⼀
个-,代表的是降序排序。
2.在模型定义的时候指定默认排序:有些时候,不想每次在查询的时候都指定排
序的方式,可以在定义模型的时候就指定排序的方式。__mapper_args__
class Article(Base):__tablename__ = 'article'id = Column(Integer, primary_key=True, autoincrement=True)title = Column(String(50))# create_time = Column()def __str__(self):return "Article(title:%s)" % self.title__mapper_args__ = {"order_by": id.desc()# "order_by": id}
limit
可以限制每次查询的时候只查询几条数据
# 前三条数据articles = session.query(Article).limit(3).all()
offset
可以限制查找数据的时候过滤掉前面多少条。
articles = session.query(Article).offset(2).limit(3)
切片
效率没有offset+limit高,因为切片是先从数据库先查询出所有,然后再进行切片,offset+limit
是在数据库中构造limit语句,先偏移然后只查询需要的数据条数
articles = session.query(Article).all()[2:5]
分组
准备模型类和数据
class User(Base):__tablename__ = "users"id = Column(Integer, primary_key=True, autoincrement=True)username = Column(String(50), nullable=False)gender = Column(Enum('男', '女'))age = Column(Integer)Base.metadata.drop_all()Base.metadata.create_all()session = sessionmaker(bind=engine)()import randomfor x in range(10):user = User(username='juran%s' % x, gender=random.choice(['男', '女']), age=random.randint(12, 26))session.add(user)session.commit()
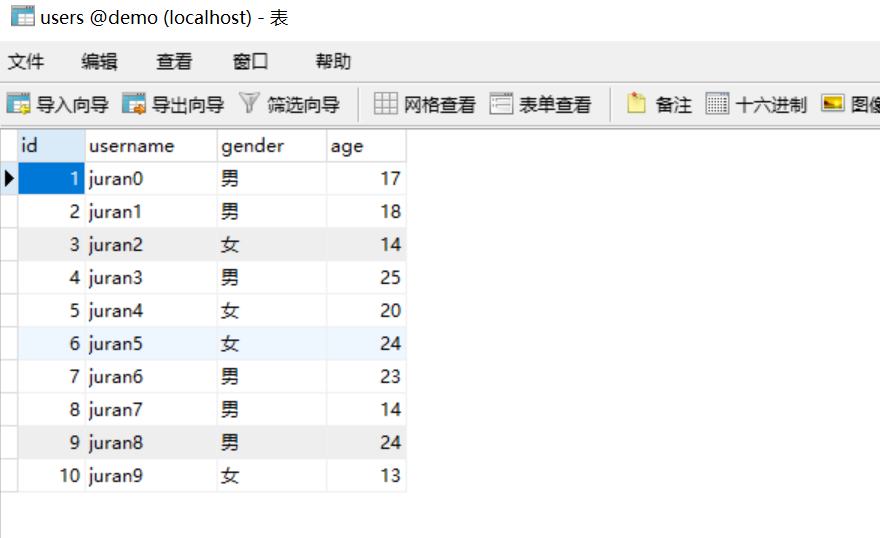
group_by
# 按照性别来进行分组, 求男女的人数# 聚合函数 一般会和分组进行使用from sqlalchemy import funcresult = session.query(User.gender, func.count(User.id)).group_by(User.gender).all()# SELECT gender FROM users GROUP BY users.genderprint(result) # [('男', 6), ('女', 4)]
having
from sqlalchemy import funcresult = session.query(User.age, func.count(User.id)).group_by(User.age).having(User.age < 18).all()# SELECT users.age , count(users.id) FROM users GROUP BY users.age HAVING users.age < 8print(result) # [(17, 1), (14, 2), (13, 1)]
子查询
不推荐,语法(select ……) 作为一个整体,效率和两次SQL差不多,但语法更复杂
准备模型类和数据
class User(Base):__tablename__ = "users"id = Column(Integer, primary_key=True, autoincrement=True)username = Column(String(50), nullable=False)city = Column(String(50))age = Column(Integer)def __str__(self):return "User(username:%s)" % self.username
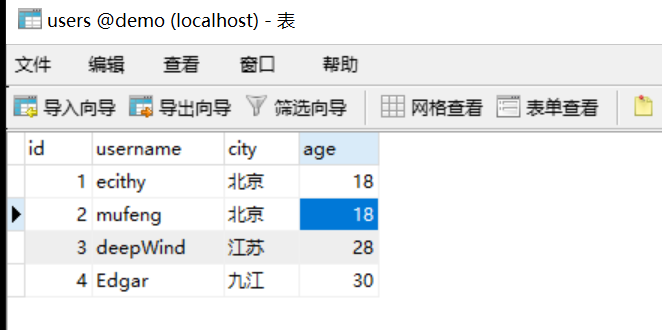
# 查询和ecithy 相同的城市和年龄的人# user = session.query(User).filter(User.username == 'ecithy').first()result = session.query(User.username).filter(User.city == user.city, User.age == user.age).all()# SELECT users.username FROM users WHERE users.city = '北京' and users.age = 18for data in result:print(data)sub = session.query(User.city.label('city'), User.age.label('age')).filter(User.username == 'ecithy').subquery()# c columnresult = session.query(User).filter(User.city == sub.c.city, User.age == sub.c.age).all()for data in result:print(data)
join⽅法
作用:把两张表字段相等的数据连接成一张表
join查询分为两种,⼀种是inner join,另⼀种是outer join。默认的是inner
join,如果指定left join或者是right join则为outer join。如果想要查询User及
其对应的Address,则可以通过以下方式来实现
session.query(User,Address).filter(User.id==Address.user_id).all():
总结
子查询和join查询具体选择哪个,需要根据实际情况看两张表的数据大小和SQL语句查询的具体需求。一般推荐join效率更高。

若有收获,就点个赞吧
0 人点赞
