- 目的:更直观的方式来判断拟合规律
- 方法:通过逐渐增加数据(特征),观察得到的模型在训练数据集和测试数据集上的表现。
绘制学习曲线
```python import numpy as np import matplotlib.pyplot as plt
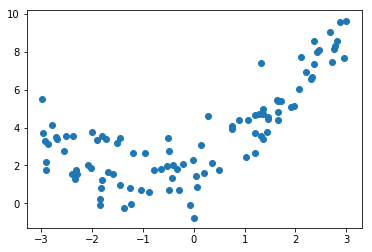
np.random.seed(666) x = np.random.uniform(-3.0, 3.0, size=100) X = x.reshape(-1, 1) y = 0.5 x*2 + x + 2 + np.random.normal(0, 1, size=100)
plt.scatter(x, y) plt.show()
```pythonfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=10)X_train.shape # (75, 1)from sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_errortrain_score = []test_score = []for i in range(1, 76):lin_reg = LinearRegression()lin_reg.fit(X_train[:i], y_train[:i])y_train_predict = lin_reg.predict(X_train[:i])train_score.append(mean_squared_error(y_train[:i], y_train_predict))y_test_predict = lin_reg.predict(X_test)test_score.append(mean_squared_error(y_test, y_test_predict))plt.plot([i for i in range(1, 76)], np.sqrt(train_score), label="train")plt.plot([i for i in range(1, 76)], np.sqrt(test_score), label="test")plt.legend()plt.show()
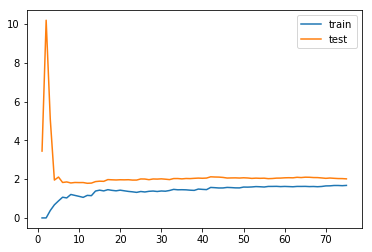
封装学习曲线
def plot_learning_curve(algo, X_train, X_test, y_train, y_test):train_score = []test_score = []for i in range(1, len(X_train)+1):algo.fit(X_train[:i], y_train[:i])y_train_predict = algo.predict(X_train[:i])train_score.append(mean_squared_error(y_train[:i], y_train_predict))y_test_predict = algo.predict(X_test)test_score.append(mean_squared_error(y_test, y_test_predict))plt.plot([i for i in range(1, len(X_train)+1)],np.sqrt(train_score), label="train")plt.plot([i for i in range(1, len(X_train)+1)],np.sqrt(test_score), label="test")plt.legend()plt.axis([0, len(X_train)+1, 0, 4])plt.show()
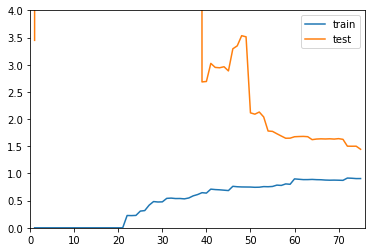
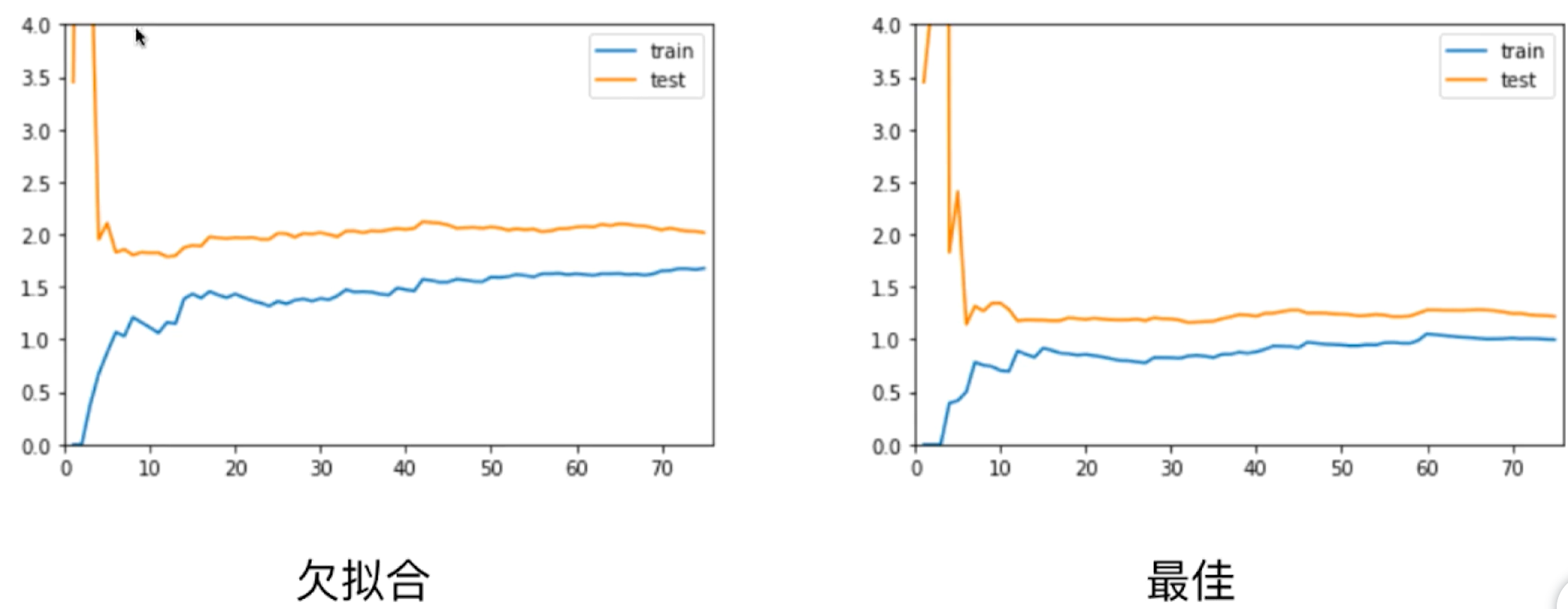
欠拟合学习曲线
plot_learning_curve(LinearRegression(), X_train, X_test, y_train, y_test)
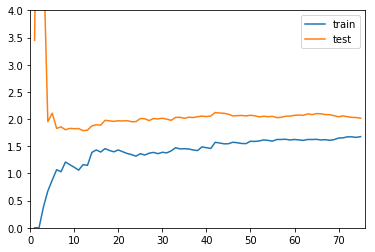
- 测试集、训练集上误差大且接近,说明模型拟合效果不好
恰拟合学习曲线
```python二阶多项式学习曲线
from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline
def PolynomialRegression(degree): return Pipeline([ (“poly”, PolynomialFeatures(degree=degree)), (“std_scaler”, StandardScaler()), (“lin_reg”, LinearRegression()) ])
poly2_reg = PolynomialRegression(degree=2) plot_learning_curve(poly2_reg, X_train, X_test, y_train, y_test)
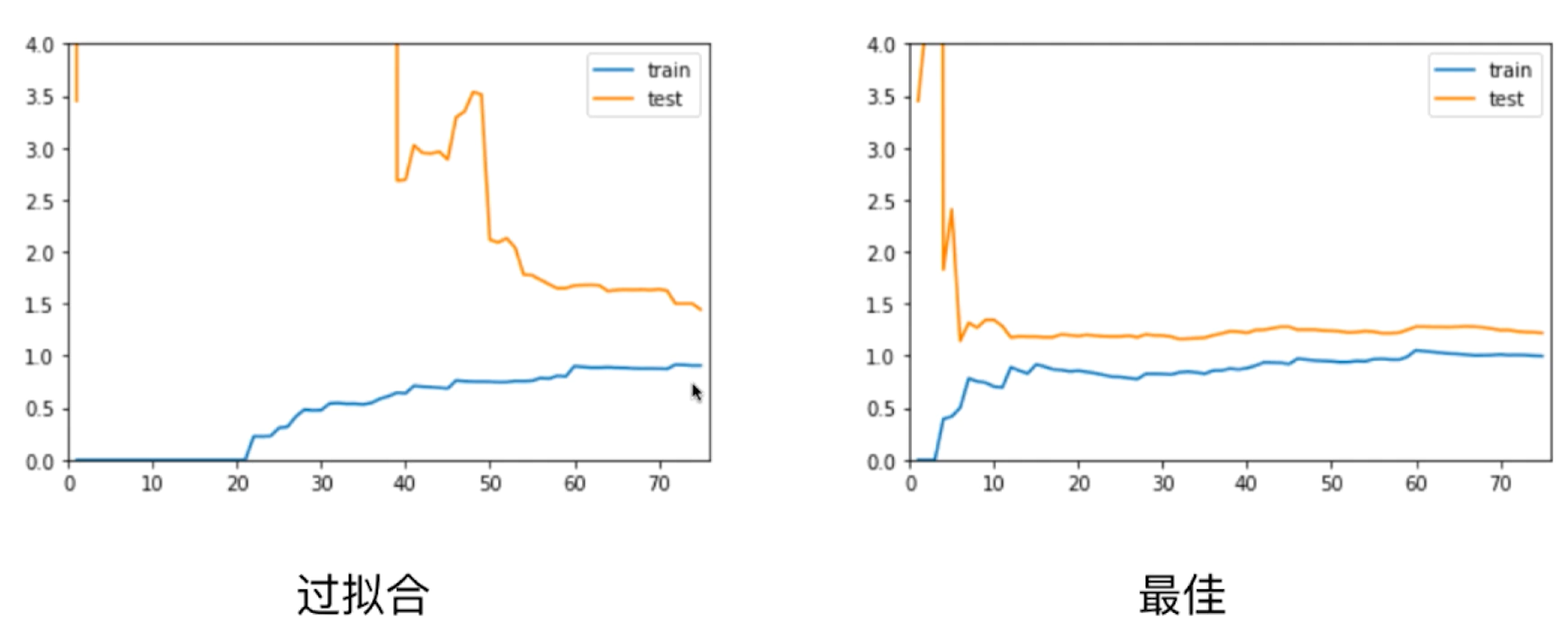
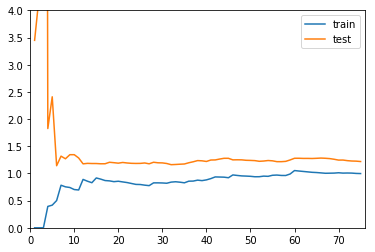- [x] 测试集、训练集上误差小且接近,说明模型拟合效果好<a name="efYgV"></a># 过拟合学习曲线```pythonpoly20_reg = PolynomialRegression(degree=20)plot_learning_curve(poly20_reg, X_train, X_test, y_train, y_test)

若有收获,就点个赞吧
0 人点赞
