准备数据
import numpy as npimport matplotlib.pyplot as plt# raw_data_X 第1列为特征1,第2列为特征2raw_data_X = [[3.393533211, 2.331273381],[3.110073483, 1.781539638],[1.343808831, 3.368360954],[3.582294042, 4.679179110],[2.280362439, 2.866990263],[7.423436942, 4.696522875],[5.745051997, 3.533989803],[9.172168622, 2.511101045],[7.792783481, 3.424088941],[7.939820817, 0.791637231]]# 标签raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]# 将list类型转换成ndarrayX_train = np.array(raw_data_X)y_train = np.array(raw_data_y)
可视化探索
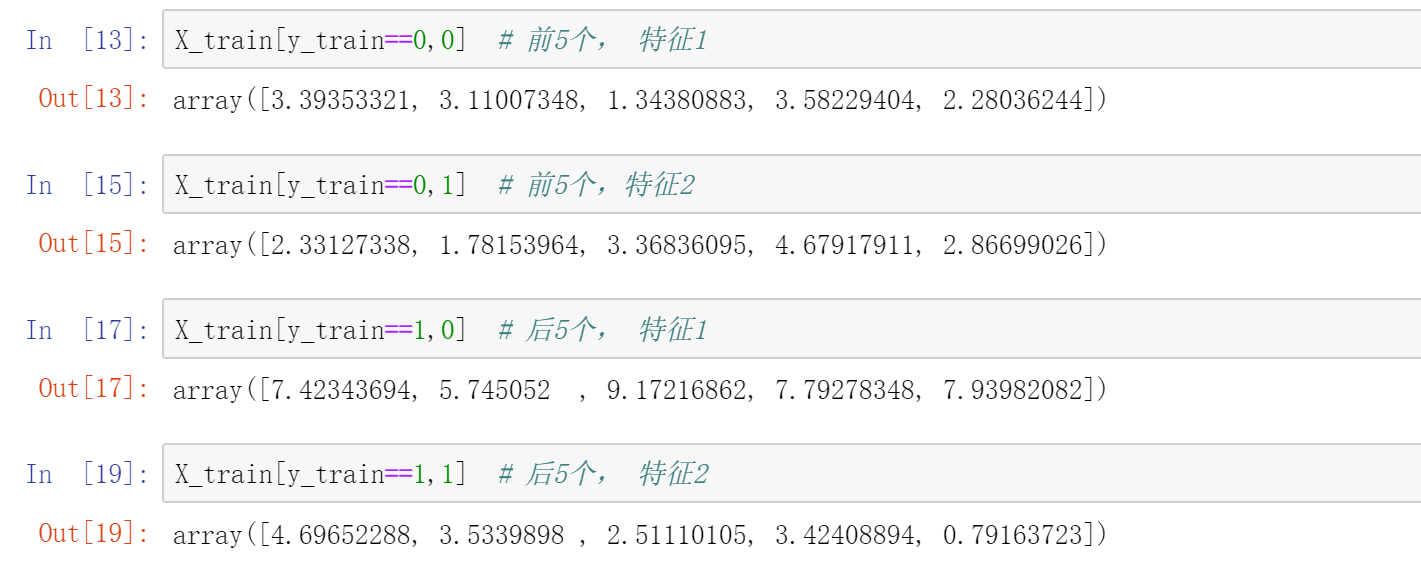
plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1], color='g') # 标签0 为绿色plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1], color='r') # 标签1 为红色plt.show()
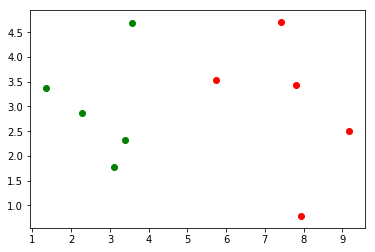
预测
x = np.array([8.093607318, 3.365731514]) # 预测点plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1], color='g')plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1], color='r')plt.scatter(x[0], x[1], color='b')plt.show()
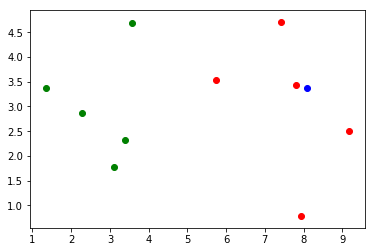
建模
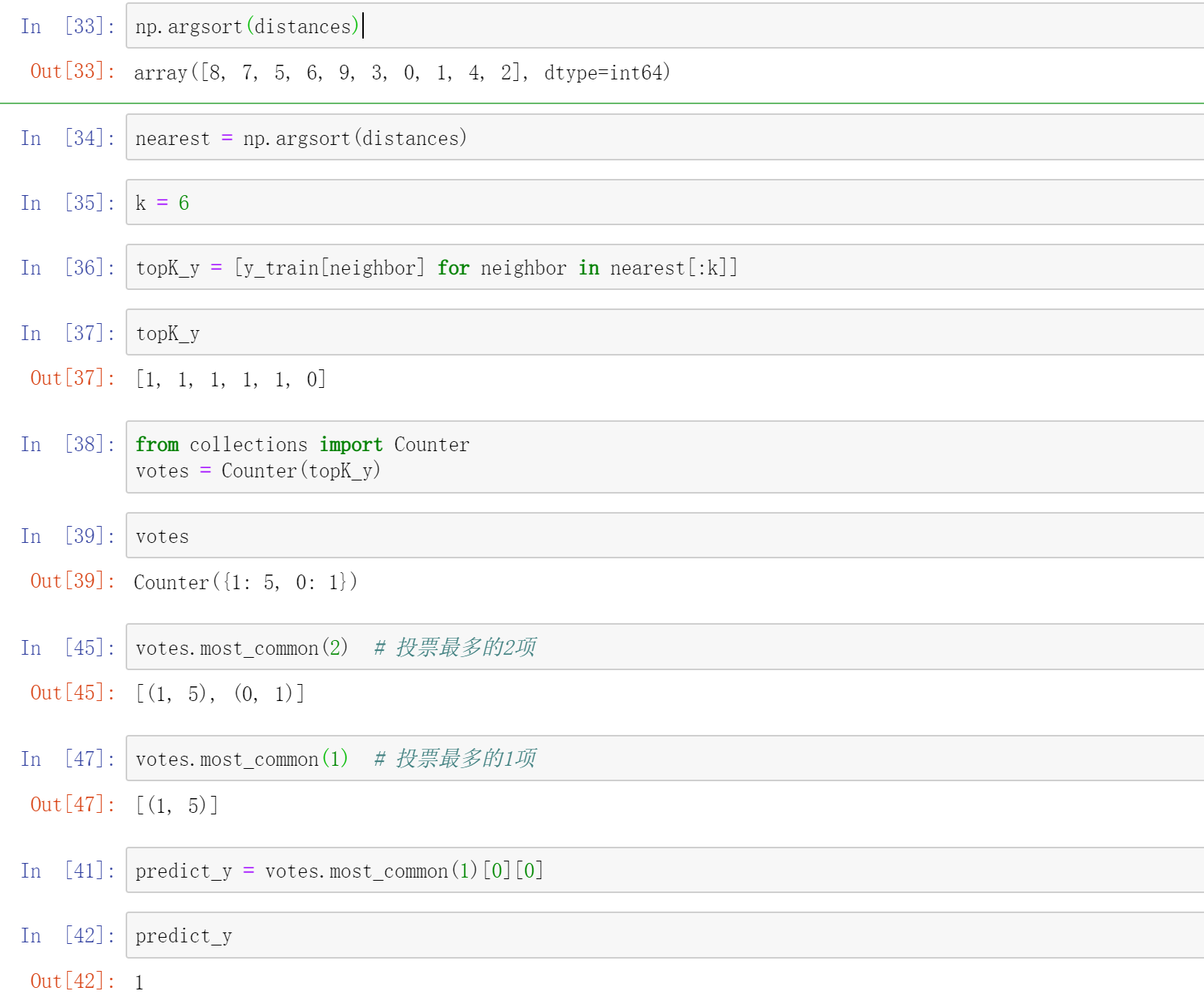
模型封装
简单封装
import numpy as npfrom math import sqrtfrom collections import Counterdef kNN_classify(k, X_train, y_train, x):assert 1 <= k <= X_train.shape[0], "k must be valid"assert X_train.shape[0] == y_train.shape[0], \"the size of X_train must equal to the size of y_train"assert X_train.shape[1] == x.shape[0], \"the feature number of x must be equal to X_train"distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train]nearest = np.argsort(distances)topK_y = [y_train[i] for i in nearest[:k]]votes = Counter(topK_y)return votes.most_common(1)[0][0]
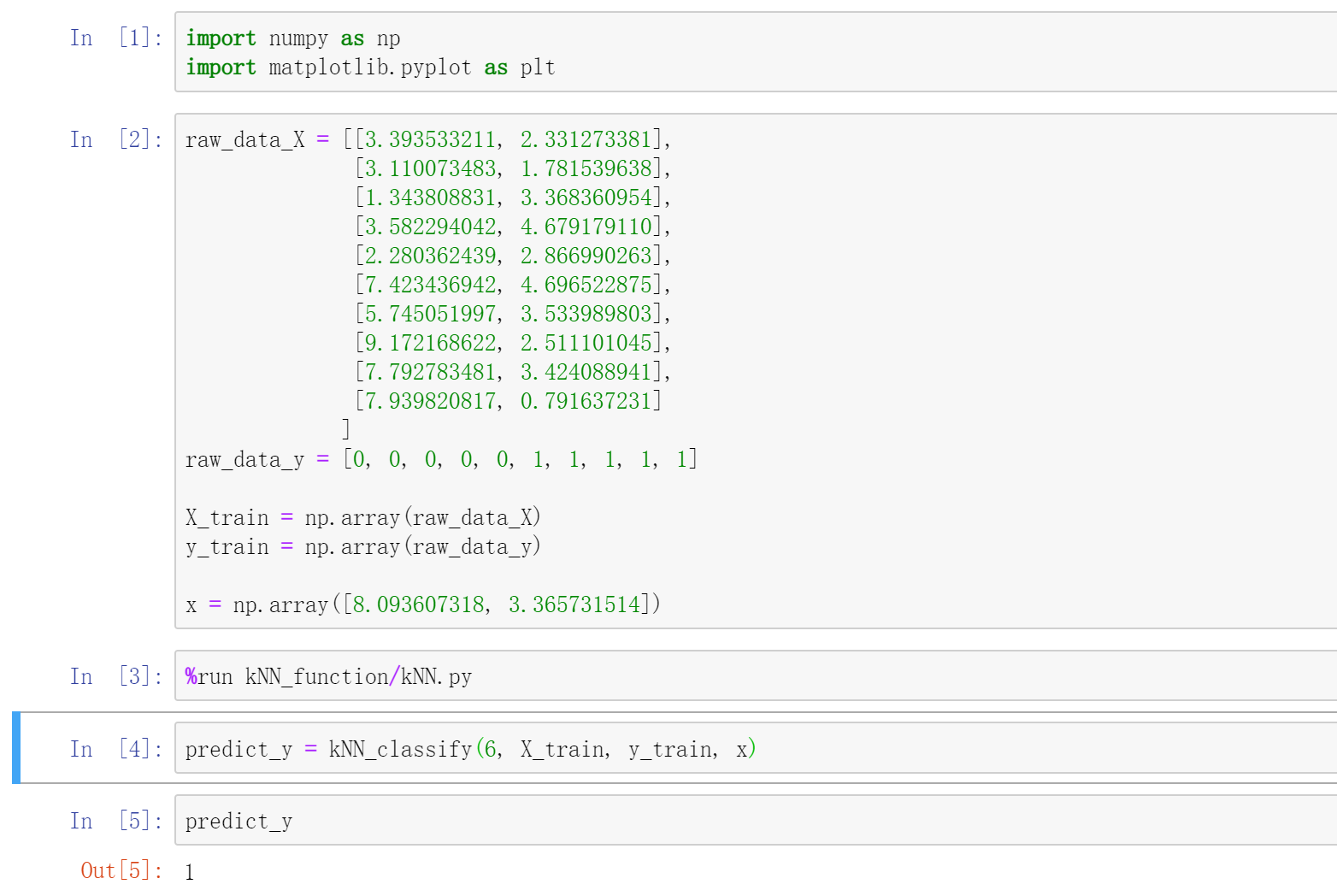
进一步封装
为了将语法和scikit-learn统一
# kNN.pyimport numpy as npfrom math import sqrtfrom collections import Counterclass KNNClassifier:def __init__(self, k):"""初始化kNN分类器"""assert k >= 1, "k must be valid"self.k = kself._X_train = Noneself._y_train = Nonedef fit(self, X_train, y_train):"""根据训练数据集X_train和y_train训练kNN分类器"""assert X_train.shape[0] == y_train.shape[0], \"the size of X_train must be equal to the size of y_train"assert self.k <= X_train.shape[0], \"the size of X_train must be at least k."self._X_train = X_trainself._y_train = y_trainreturn selfdef predict(self, X_predict):"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""assert self._X_train is not None and self._y_train is not None, \"must fit before predict!"assert X_predict.shape[1] == self._X_train.shape[1], \"the feature number of X_predict must be equal to X_train"y_predict = [self._predict(x) for x in X_predict]return np.array(y_predict)def _predict(self, x):"""给定单个待预测数据x,返回x的预测结果值"""assert x.shape[0] == self._X_train.shape[1], \"the feature number of x must be equal to X_train"distances = [sqrt(np.sum((x_train - x) ** 2))for x_train in self._X_train]nearest = np.argsort(distances)topK_y = [self._y_train[i] for i in nearest[:self.k]]votes = Counter(topK_y)return votes.most_common(1)[0][0]def __repr__(self):return "KNN(k=%d)" % self.k


若有收获,就点个赞吧
0 人点赞
