Pandas读取csv
读取某个CSV文件
import pandas as pddf =pd.read_csv('aqi_statistic_analysis.csv')
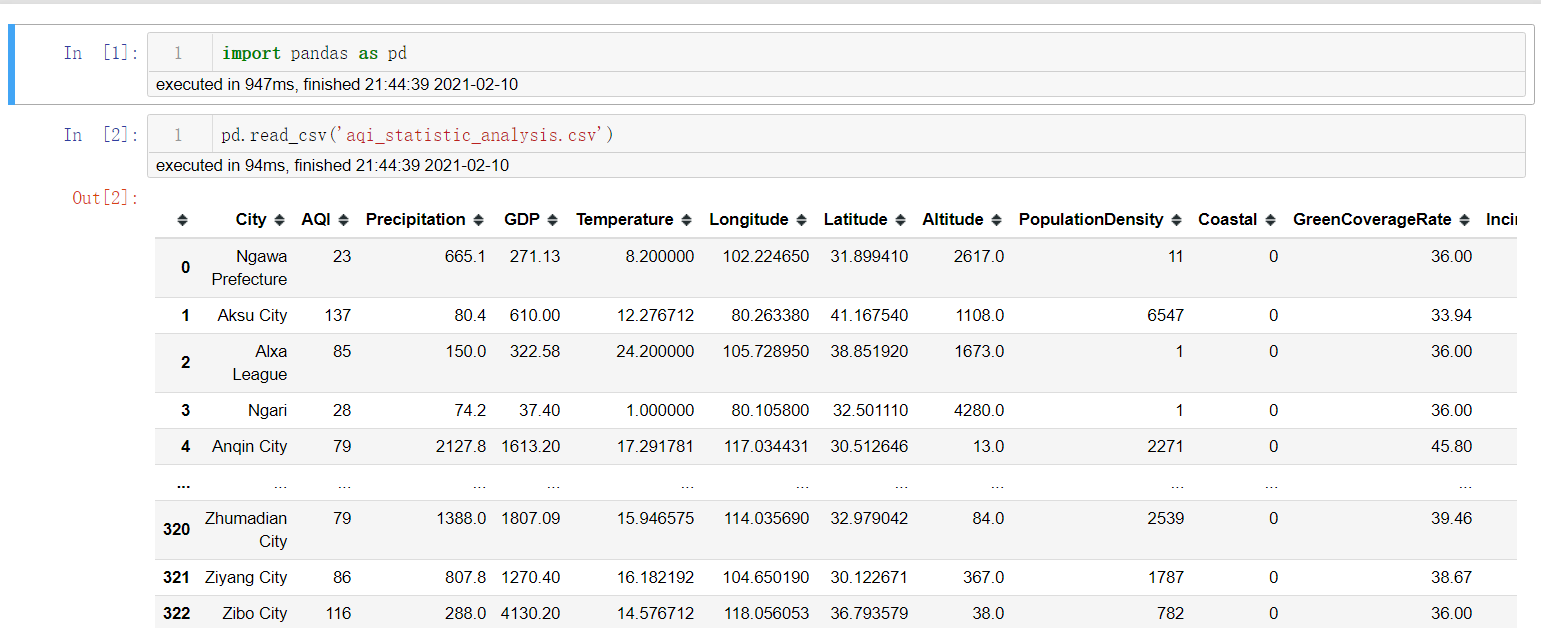
实际上pd.read_csv 还有很多参数,可以在notebook中通过 ?pd.read_csv查询 查询其参数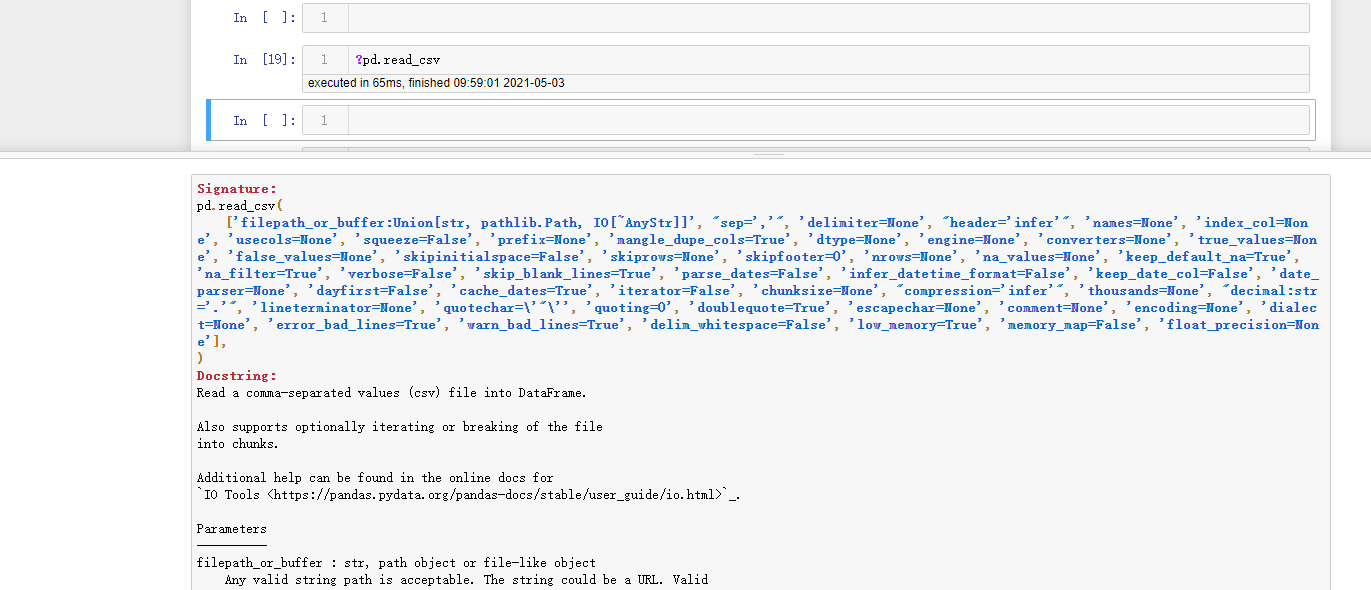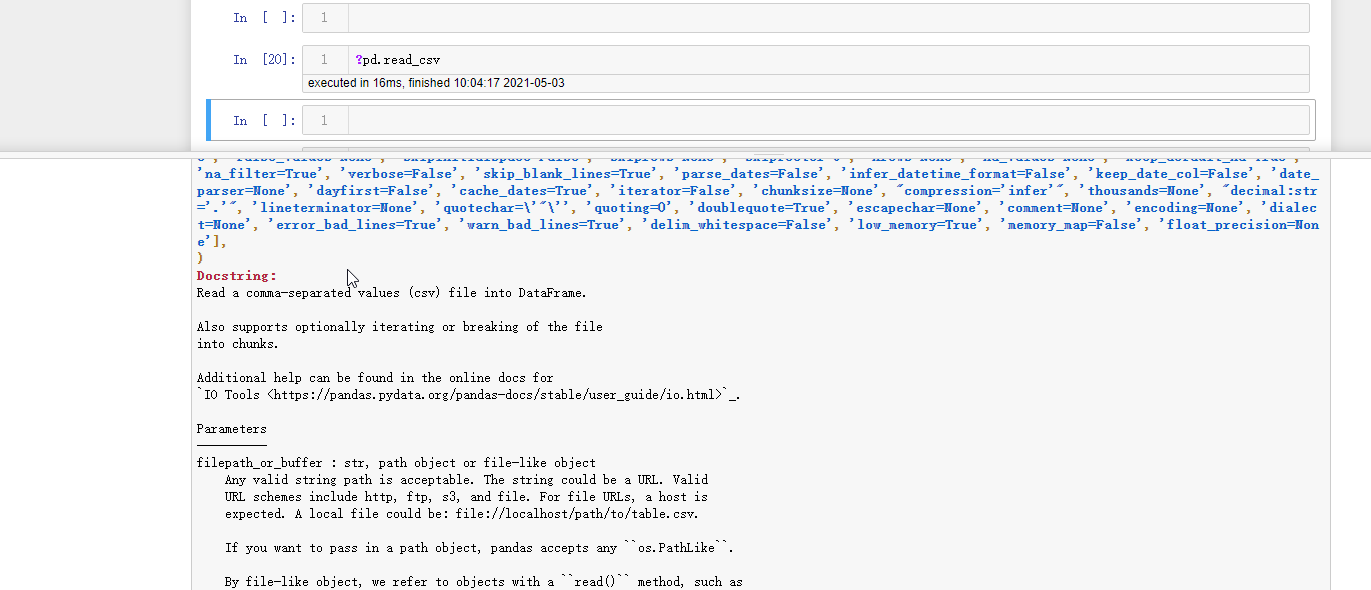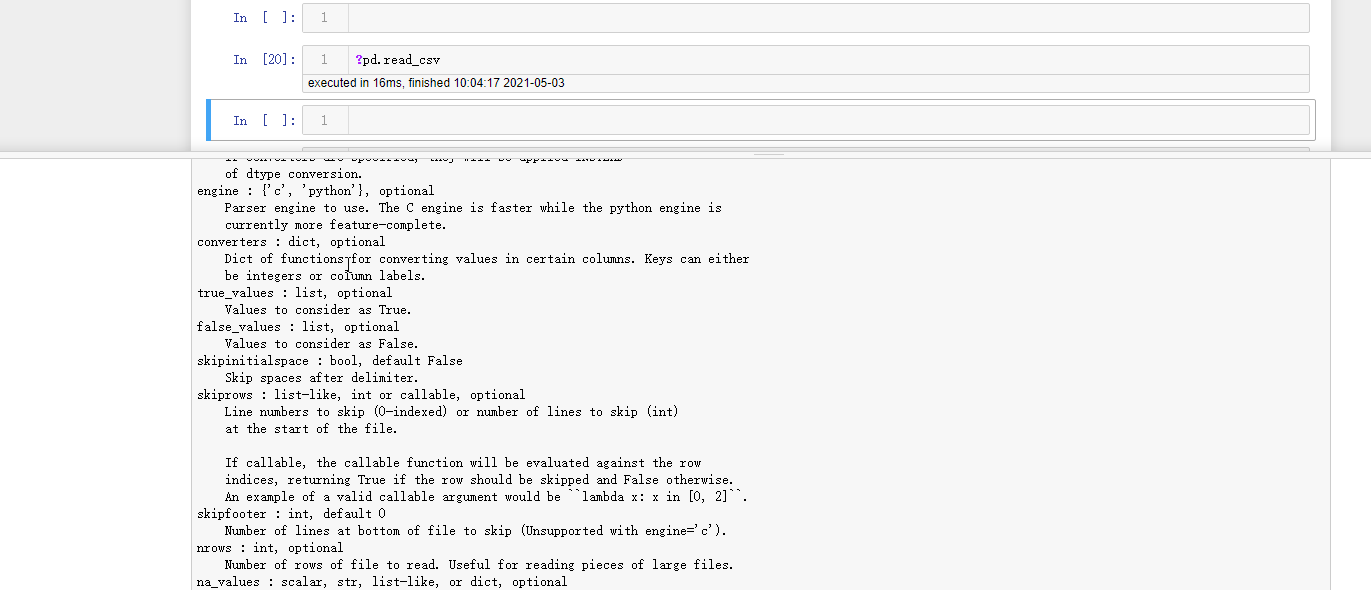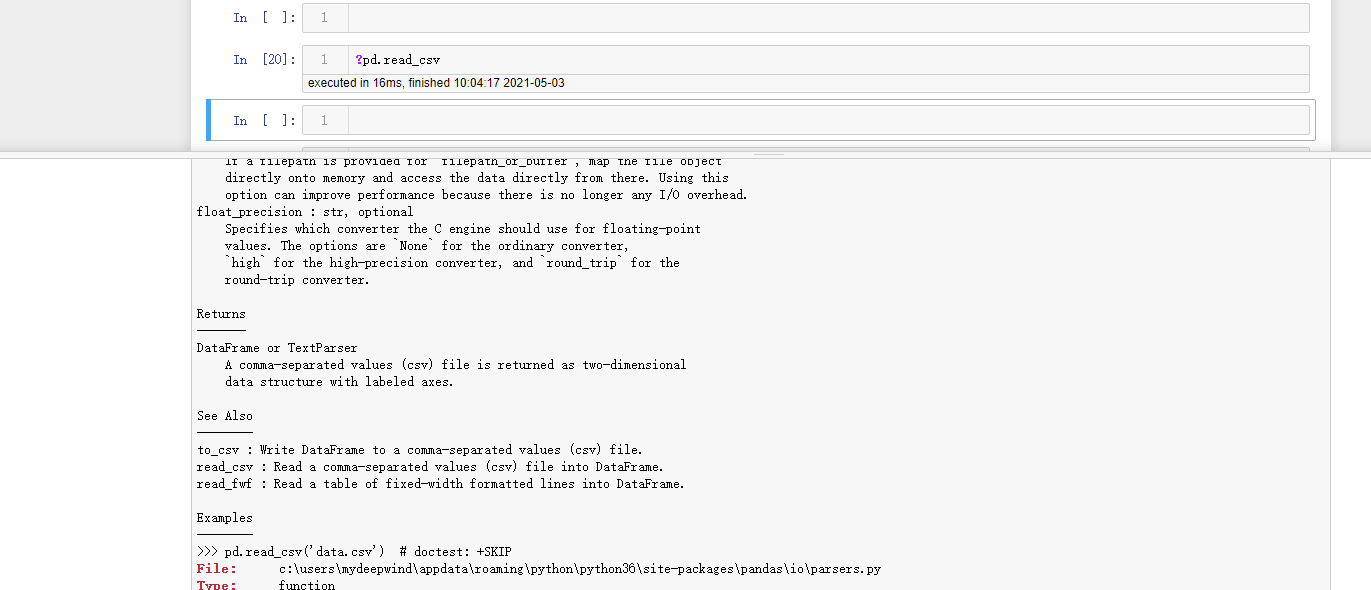
参数:
filepath_or_buffer :
字符串,或者任何对象的read()方法。这个字符串可以是URL,有效的URL方案包括http、ftp、s3和文件。可以直接写入”文件名.csv”
header :
将行号用作列名,且是数据的开头。注意当skip_blank_lines=True时,这个参数忽略注释行和空行。所以header=0表示第一行是数据而不是文件的第一行。
header=None
即指明原始文件数据没有列索引,这样read_csv为自动加上列索引,除非你给定列索引的名字。
header=0
表示文件第0行(即第一行,索引从0开始)为列索引,这样加names会替换原来的列索引。
parse_dates :
布尔类型值 or int类型值的列表 or 列表的列表 or 字典(默认值为 FALSE)
- TRUE:则尝试解析索引
- 由int类型值组成的列表(例子 [1,2,3]):作为单独数据列,分别解析原始文件中的1,2,3列
- 由列表组成的列表(例子[[1,3]]):将1,3列合并,作为一个单列进行解析
- 字典(例子{‘foo’:[1, 3]}):解析1,3列作为数据,并命名为foo
index_col:
int类型值,序列,FALSE(默认 None)将真实的某列当做index(列的数目,甚至列名).
skiprows: list-like or integer or callable, default None 忽略某几行或者从开始算起的几行
skip_blank_lines 默认为True,跳过blank lines 而且不是定义为NAN
thousands 千分位符号,默认‘,’
decimal 小数点符号,默认‘.’
encoding: 编码方式

若有收获,就点个赞吧
0 人点赞
