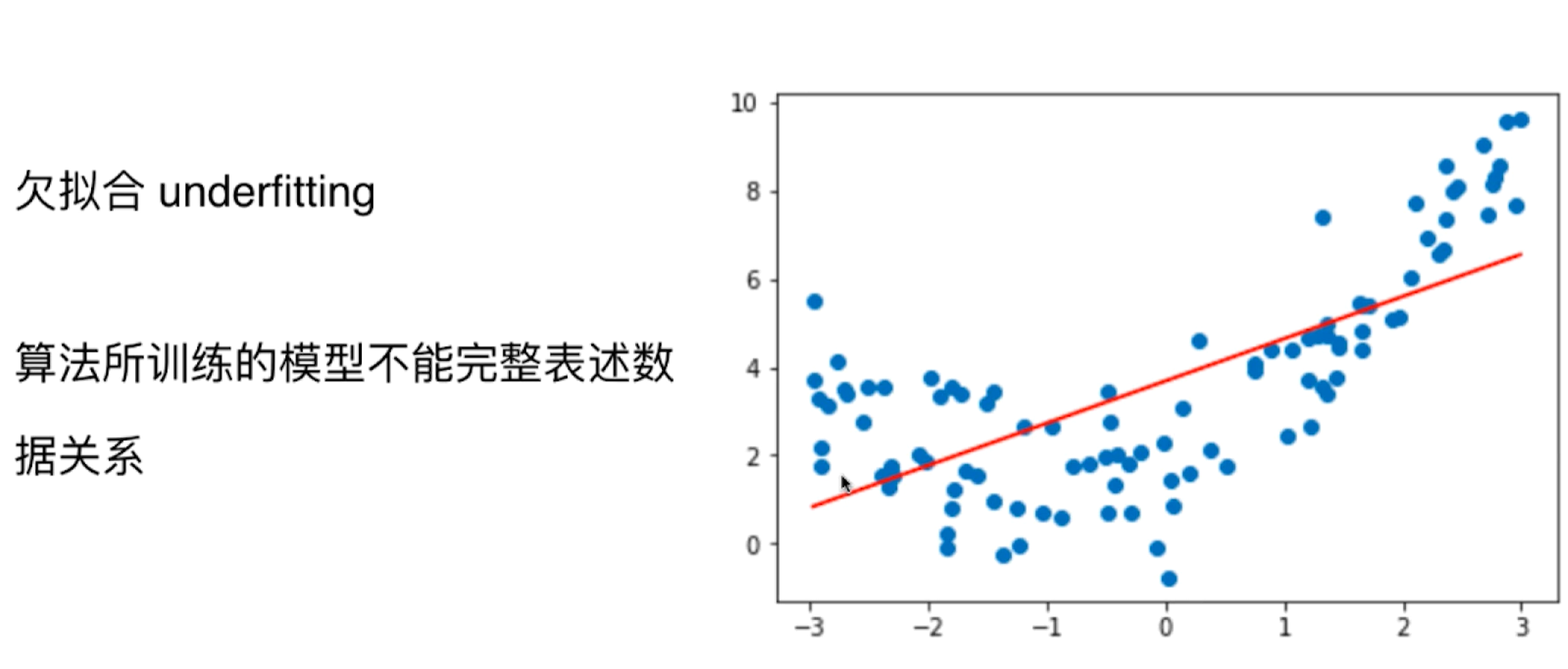
欠拟合
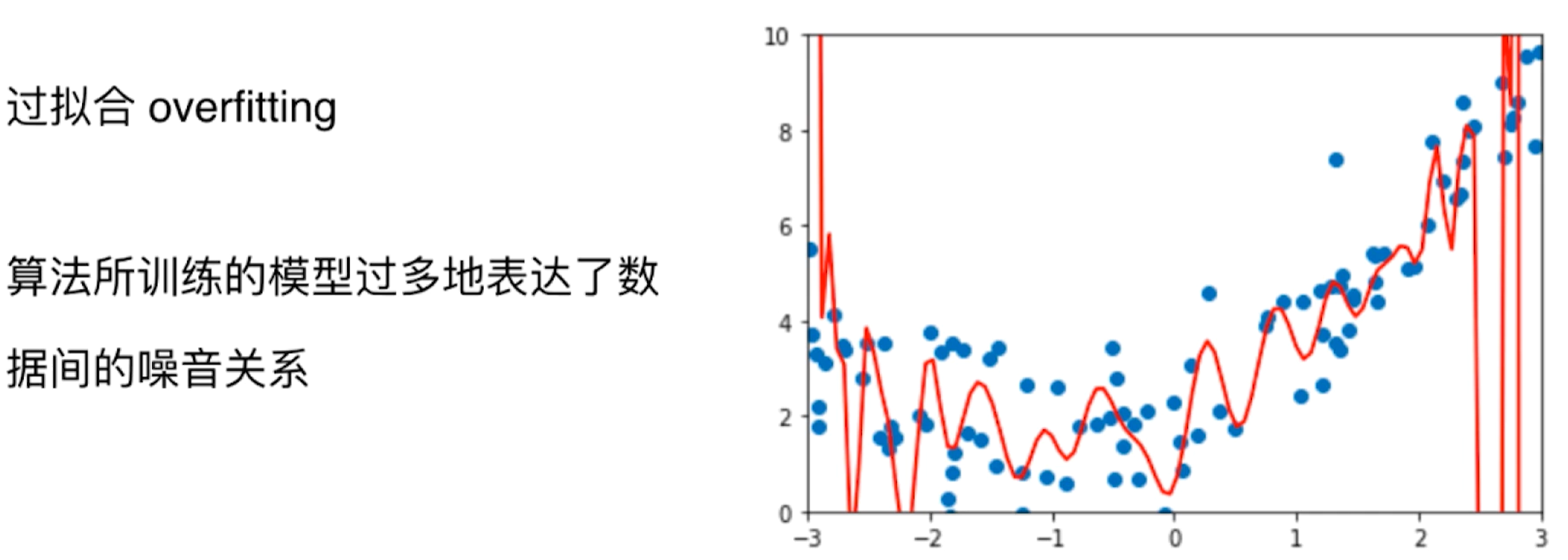
过拟合
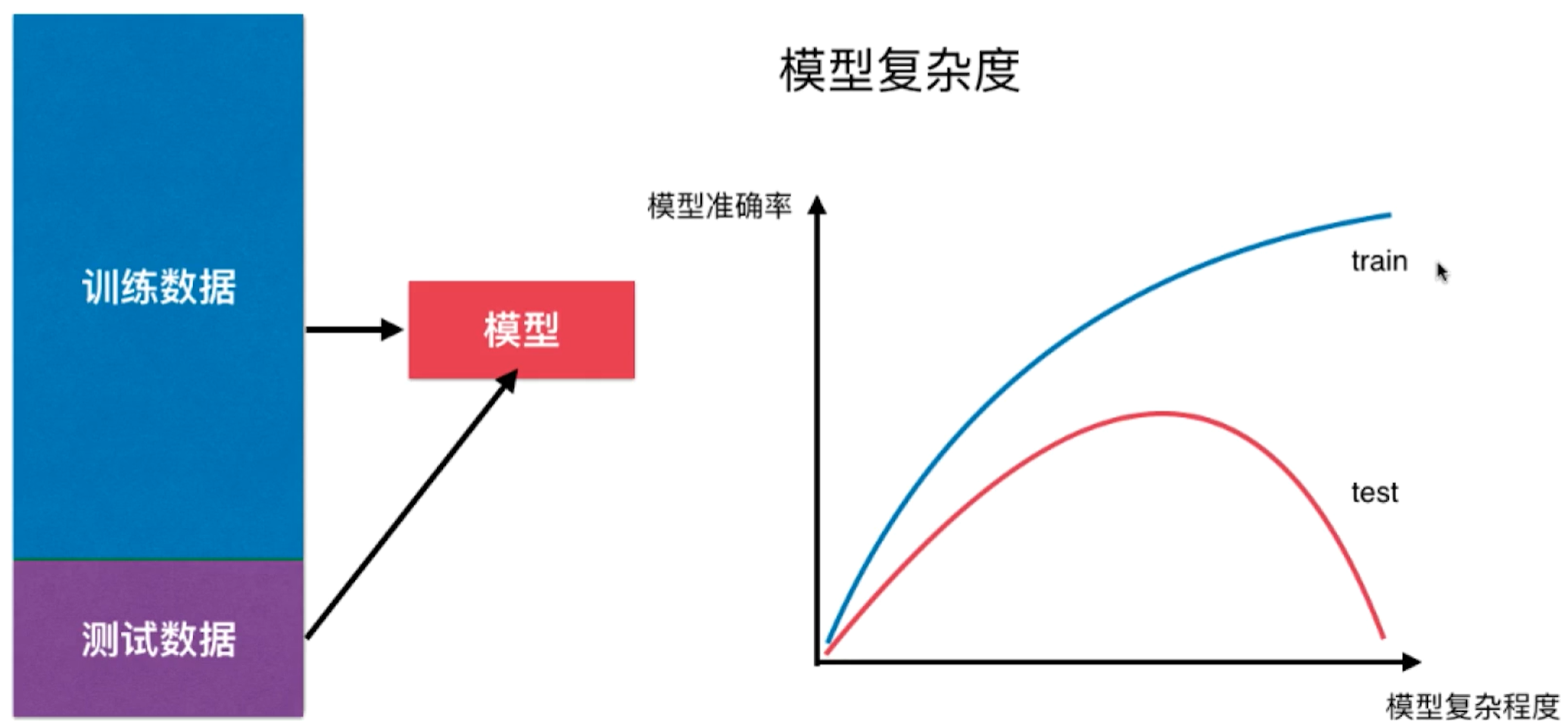
模型复杂度与拟合程度
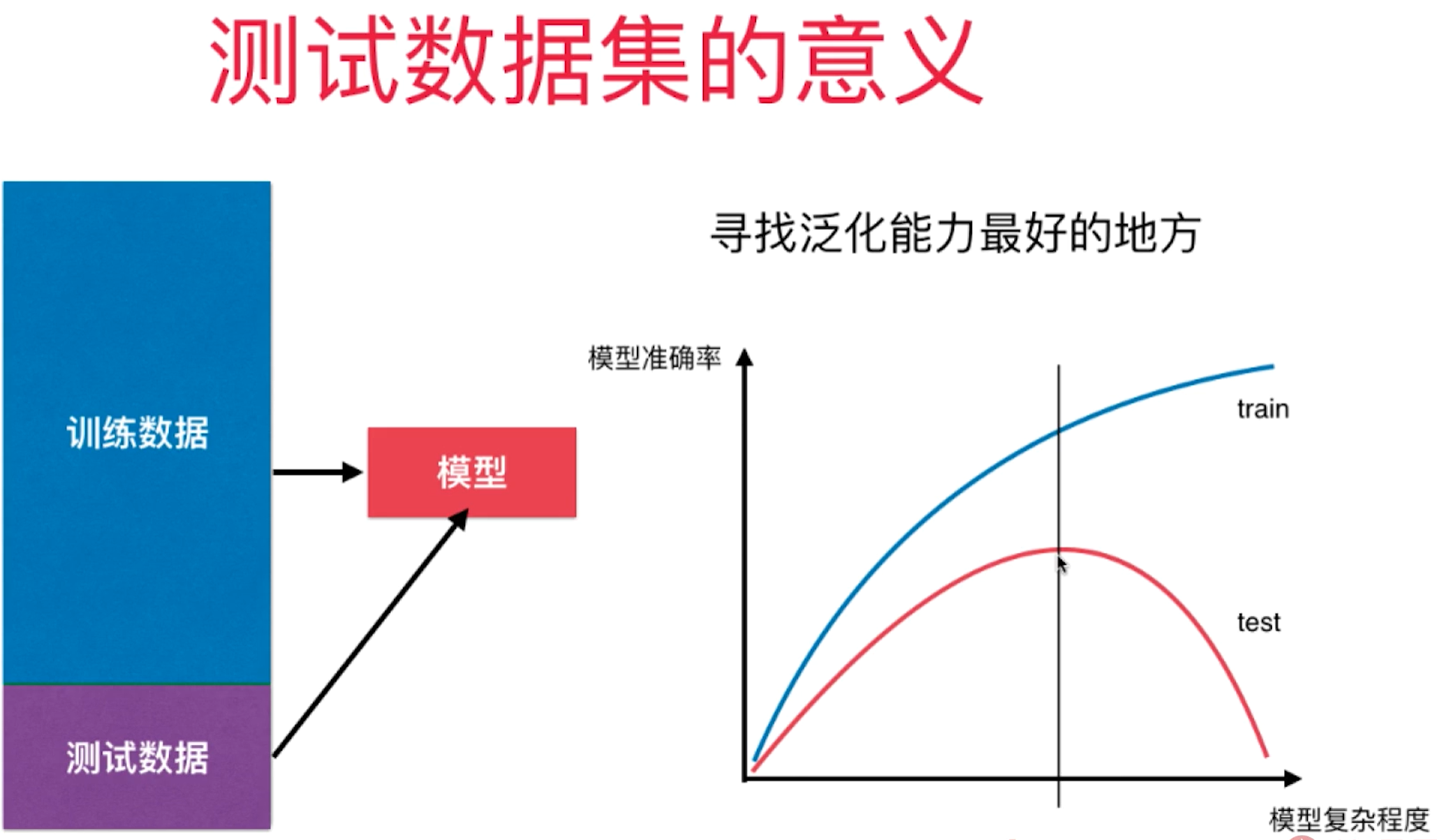
测试数据集的意义
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)lin_reg = LinearRegression()lin_reg.fit(X_train, y_train)y_predict = lin_reg.predict(X_test)mean_squared_error(y_test, y_predict) # 2.2199965269396573poly2_reg = PolynomialRegression(degree=2)poly2_reg.fit(X_train, y_train)y2_predict = poly2_reg.predict(X_test)mean_squared_error(y_test, y2_predict) # 0.80356410562978997poly10_reg = PolynomialRegression(degree=10)poly10_reg.fit(X_train, y_train)y10_predict = poly10_reg.predict(X_test)mean_squared_error(y_test, y10_predict) # 0.92129307221507939# 阶数过高,过拟合,泛化能力差poly100_reg = PolynomialRegression(degree=100)poly100_reg.fit(X_train, y_train)y100_predict = poly100_reg.predict(X_test)mean_squared_error(y_test, y100_predict) # 14075796419.234262

若有收获,就点个赞吧
0 人点赞
